El análisis de enlaces se puede utilizar para ayudar a comprender las relaciones dentro de sus datos. Cuando
se visualizan como un gráfico de enlaces o un mapa de enlaces, las
conexiones se pueden analizar y cuantificar para revelar patrones
subyacentes. Hemos
implementado varias mejoras nuevas en nuestra última versión que amplían
las formas de analizar y trabajar con sus tarjetas de análisis de
enlaces.
Las entidades son los nodos dentro de la red y pueden representar personas, lugares o cosas. Los enlaces, o aristas, son las conexiones entre estos nodos en la red de gráficos. Los
vínculos entre entidades pueden representar relaciones como
movimientos, transacciones u otras formas de conexiones dentro de su
conjunto de datos.
Al
mostrar estos enlaces en gráficos de enlaces y mapas de enlaces, puede
optar por aplicar estilo a estas conexiones con el parámetro Peso de borde . Este
valor escalará el ancho del enlace para indicar la frecuencia de las
conexiones entre nodos o un valor numérico relevante para su análisis. Por ejemplo, puede diseñar enlaces para visualizar:
la frecuencia de interacciones entre individuos en una red social
el valor monetario transferido entre cuentas financieras
o
las líneas de diálogo pronunciadas por los personajes en episodios de
mi serie de televisión de ciencia ficción, completamente ficticia, Rocket McDangerface .
Enlaces en el espacio
Explorando
mi entretenido ejemplo de televisión de ciencia ficción, he creado un
cuadro de enlaces para mostrar cada uno de los personajes y los
episodios en los que aparecen. Usaré la centralidad de cercanía
para explorar la red de personajes y episodios y nuestro gráfico de
enlaces visualizará esta centralidad escalando los nodos de los
personajes.
En este conjunto de datos, un personaje se registra en una sola fila si aparece en un episodio. Por tanto, en nuestra red todas las conexiones tienen la misma apariencia. El número de estos bordes simples que irradian de cada personaje ilustra su prevalencia en la serie. Sin
embargo, si codificáramos el atributo de diálogo en nuestro gráfico de
enlaces, podríamos aproximarnos visualmente a la importancia de los
personajes dentro de cada episodio.
Diseñar las conexiones de nuestro gráfico de enlaces utilizando el
peso del diálogo ayuda a visualizar la fuerza de su conexión con cada
episodio en el que aparecieron.
La
configuración de gráficos/mapas de enlaces con canales visuales
adicionales puede proporcionar pistas sobre la naturaleza de las
interacciones o relaciones entre los nodos dentro de su conjunto de
datos. Sin embargo, en la secuencia anterior notarás que al aplicar nuestro peso de diálogo solo se aplican estilos a las líneas. Los nodos de caracteres conservan su tamaño calculado. ¿Qué tan bueno sería si pudiéramos incorporar la medida del diálogo para calcular la importancia de cada personaje?
Centralidad ponderada
Esto nos lleva a nuestra primera mejora. Hemos implementado versiones ponderadas de nuestros algoritmos de centralidad
; la misma frecuencia o medidas numéricas utilizadas para diseñar sus
enlaces ahora se pueden utilizar como variable para calcular la centralidad . Esta
ponderación de centralidad se traduce en que los nodos se calculan como
más importantes dentro de la red cuando sus conexiones a otros nodos
ocurren con mayor frecuencia o tienen un peso mayor que otros. Si
aplicamos esto a nuestro análisis de personajes, podemos calcular una
medida analítica de su importancia y visualizar su centralidad
ponderada.
Centralidad en el espacio
Usando
nuestros gráficos de enlaces anteriores, tenemos un gráfico de enlaces
que muestra los personajes y los episodios donde aparecieron. También escalé el ancho de la conexión usando las líneas de diálogo que habló cada personaje en el episodio.
Para
ponerlo en contexto, imaginé que Rocket McDangerface y Stella Stardust
son nuestros héroes y Hugo Von Meteor es el villano cobarde. Inmediatamente, notarás que estos personajes aparecen como nodos prominentes en la red. Dado
que estos personajes aparecen en muchos episodios junto con muchos
otros personajes, se calcula que su grado de centralidad es mayor que el
de otros (se pueden utilizar otras medidas de centralidad para
enfatizar diferentes tipos de influencia). Sin
embargo, la simple métrica de su presencia en un episodio también
calcula que Astra Galactic tiene una importancia significativa a pesar
de ser un personaje terciario en la estructura del programa.
Cada uno de los diversos algoritmos de centralidad enfatiza la importancia de las entidades de manera diferente. Utilizando
la centralidad de cercanía no ponderada, el cuadro de enlaces anterior
calcula que algunos personajes secundarios son más importantes que
nuestros héroes en nuestra red.
Para calcular una medida más relevante, podríamos aplicar las líneas de diálogo como peso a nuestro cálculo de centralidad. Este método aumentará la centralidad de cada personaje en función de cuántas líneas de diálogo se les asignaron por episodio.
La aplicación del diálogo como peso en nuestros cálculos da como
resultado una clasificación de importancia del personaje que se alinea
más estrechamente con lo que esperaríamos como fanáticos devotos del
programa. Desafortunadamente,
esta ponderación también significa que el personaje favorito de culto,
'Cadet Spiff', también queda relegado a una importancia muy secundaria.
El
uso del grado de centralidad ponderado del diálogo escala a los
personajes de una manera que visualiza mejor los matices de su
importancia en el programa y la influencia que tuvieron dentro de cada
episodio. Rocket, Stella y Hugo se vuelven mucho más prominentes visualmente en comparación con otros personajes. Además, el personaje de Astra Galactic asume una importancia más secundaria como personaje secundario. Desafortunadamente,
esto también significa que mi fiel compañero y mi personaje favorito,
Cadet Spiff, también hereda una importancia mucho menor en el elenco de
personajes.
Ver cálculos de centralidad
Usando
estos nuevos cálculos, podemos visualizar la centralidad ponderada y
examinar cómo ha cambiado la centralidad de los nodos aplicando nuestro
peso de borde. Examinar
visualmente la red y comparar los nodos o inspeccionar ventanas
emergentes siempre es una opción, pero no es muy conveniente si está
revisando muchos nodos en una red compleja.
¡Ingrese a nuestra segunda mejora relacionada con el análisis de enlaces! ¿Quizás hayas notado la nueva opción Ver centralidades dentro del grupo de opciones de Gráfico ? Al hacer clic en esta opción, se agregará una nueva tarjeta de tabla de referencia a su libro de trabajo que contiene los resultados de los cálculos. Esta tabla está organizada con las siguientes columnas:
Entidad : indica el grupo de entidades al que pertenece el nodo. En
una red de producción de películas, la entidad podría indicar si un
nodo es una película, un miembro del reparto, un director o un escritor.
Nodo : esta columna proporciona el identificador específico de cada nodo. En
nuestro ejemplo de producción de películas, esto podría contener el
título de la película o el nombre del miembro del elenco/producción
dependiendo de la entidad del nodo (los mapas de enlaces derivan esta
columna del campo Visualización configurado en el campo Ubicación ).
Centralidad
: esta columna contiene el valor de centralidad calculado para el nodo
en función de los parámetros del algoritmo actual y la configuración del
gráfico. Esta tabla está
vinculada al mapa de enlaces o al gráfico de enlaces y se actualizará en
consecuencia a medida que se produzca la configuración del gráfico.
Como ejemplo, volvamos a nuestro cuadro de vínculos de personajes. Ver
los cálculos de centralidad en la tabla hace que sea muy conveniente
ordenar, revisar y seleccionar entidades de las tarjetas de enlace y
mostrarlas en la tabla para compararlas.
Ver los resultados analíticos de sus tarjetas de enlace en una
tabla puede facilitar la clasificación, selección y visualización del
resultado de los cálculos de centralidad.
Esto cubre nuestras mejoras en el análisis de enlaces para esta versión. ¡Usar
los algoritmos de centralidad ponderada y ver los resultados de los
cálculos en una tabla debería hacer que realizar análisis de enlaces y
descubrir patrones en sus datos sea mucho más fácil!
Si desea profundizar más, consulte este libro de trabajo que muestra estas nuevas características.
Embárquese en una aventura en las centralidades con este libro de
demostración que destaca las funciones de análisis de enlaces en
nuestra última versión.
El análisis de datos con métodos visuales lo ayuda a obtener una mejor comprensión de la complejidad. Ya sea que indague en una base de datos filtrada, investigue las interacciones entremezcladas de un ecosistema, administre su organización en red o organice un gran archivo, comienza a dar sentido a un problema complejo al mapear sus actores y relaciones. Como un proceso de pensamiento fundamentalmente humano, el mapeo nos ayuda a navegar vínculos particulares entre los actores mientras vemos los patrones en un panorama más amplio y obtenemos información a lo largo de este viaje. Hemos estado adaptando interfaces y procesos para que esa experiencia sea lo más intuitiva posible en la plataforma Graph Commons.
Comienza analizando un mapa de red examinando su centralidad y métricas de agrupación. La red se organiza a sí misma mediante una simulación basada en la física entre nodos vecinos, jalándose y empujándose unos a otros como resortes. Este proceso de organización del diseño revela los actores centrales y periféricos, los enlaces indirectos, los grupos orgánicos, los nodos puente y los valores atípicos que de otro modo no vería.
Mientras navega por un mapa de red, reconoce visualmente los nodos más conectados a partir de sus líneas de entrada y salida, que establecen conexiones específicas entre partes de la imagen, mientras descartan otras. El tamaño de fuente y círculo indica la importancia relativa de cada nodo. Observa los grupos de nodos estrechamente interconectados. Los nodos puente entre dos o más clústeres se vuelven claramente visibles. Sin embargo, cuando un mapa de red se hace más grande, el nivel de detalle abruma nuestros sentidos. Para examinar y comparar dichas cualidades con precisión, necesita vistas más cuantitativas de los datos contenidos en el grafo.
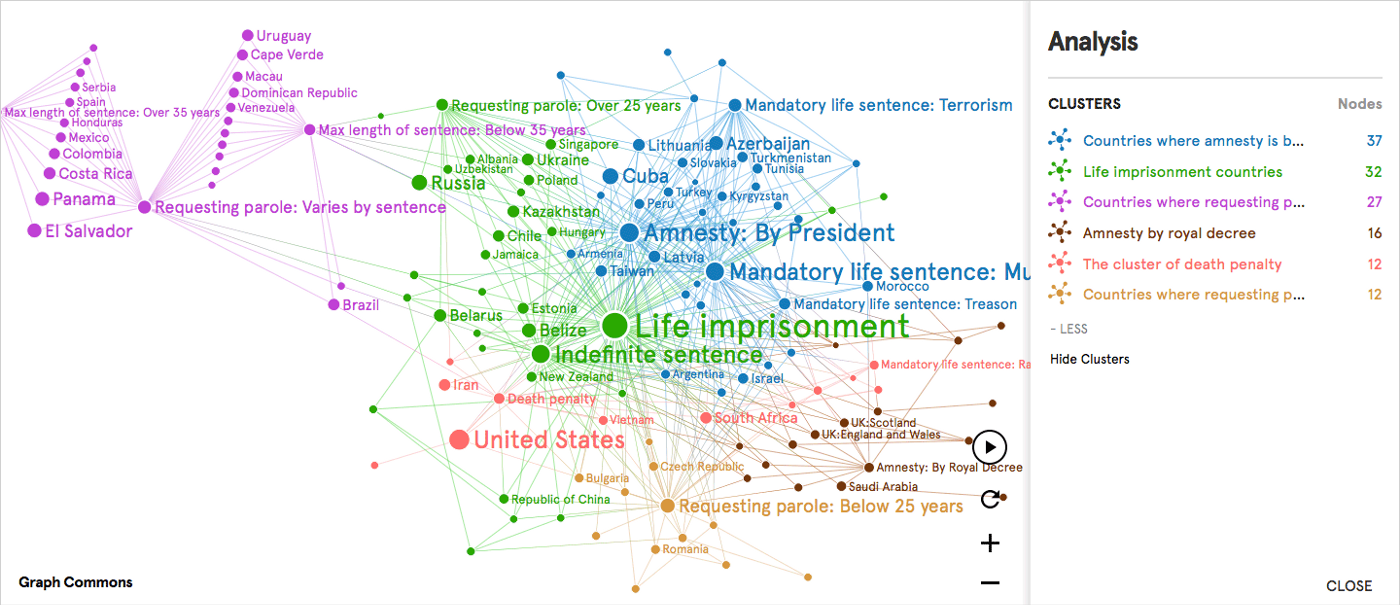
Red de Sistemas Penales (2013)— Un mapa de red de países vinculados a temas jurídicos ya sea que se ejerzan o no en su derecho.
La interfaz gráfica actual en Graph Commons proporciona una experiencia continua de cambiar de lo particular (un nodo específico y sus relaciones inmediatas) a lo general (ver la red más grande) y viceversa. Creemos que este ciclo te ayuda a crear un marco de referencia útil en tu mente para digerir la complejidad. Para respaldar esta experiencia cualitativa con métodos cuantitativos, hemos desarrollado una nueva característica que simplemente llamamos "Analysis".
De un grafo a una lista, luego a un gráfico
Para obtener un resumen de los nodos más importantes en un gráfico, abra la barra de Análisis, donde verá una lista de los nodos principales ordenados por sus métricas, como el número de conexiones, la centralidad de intermediación y propiedades numéricas como la edad, también como la frecuencia de propiedades nominales como el día de la semana. Desde una lista, abre un gráfico para ver la distribución de todos los nodos por una determinada métrica, lo que proporciona un análisis comparativo de un gráfico de dispersión típico.
Identifique clústeres en su red
Una tarea común de análisis en redes es descubrir los grupos orgánicos o comunidades en base a las conexiones entre los nodos de la red. La idea es encontrar grupos de nodos que tengan más conexiones entre sí que con los extraños.
Mostrando 6 clusters por color identificados en la red
Con la función "Clustering" en la barra de análisis, puede identificar grupos orgánicos en su red. Cuando ejecuta el proceso de agrupamiento, aplica el algoritmo de modularidad de Louvain y encuentra los grupos muy unidos caracterizados por una densidad de vínculos relativamente alta.
Cuando se detectan clústeres, es importante resaltar su importancia dentro de la red más grande. Por lo tanto, se etiquetan automáticamente en función del nodo más conectado del clúster. Sin embargo, le recomendamos encarecidamente que cambie el nombre de estas comunidades usted mismo para resaltar lo que estas comunidades especifican en su red.
La “Red de Sistemas Penales” (visto arriba), es un mapa de red de países en relación con temas jurídicos como cadena perpetua, libertad condicional, sentencia indefinida y amnistía. Al mostrar si estos temas se están ejerciendo o cómo, proporciona una comparación de sanciones a escala entre países y sistemas legales.
Cuando aplicamos el análisis de conglomerados, muestra los siguientes conglomerados, que están etiquetados por el nodo más central dentro de un conglomerado determinado:
Países donde la amnistía es otorgada por un presidente
Países con cadena perpetua
Países donde la solicitud de libertad condicional varía según la sentencia
Amnistía por real decreto
El cúmulo de la pena de muerte
Países donde solicitar libertad condicional es menor de 25 años
La agrupación de estos países y los sistemas de penas están en línea con la distinción de las tradiciones legales. Los países de derecho consuetudinario (desde EE. UU. hasta el Reino Unido y sus antiguas colonias), los países de derecho civil (Europa, América Latina, Asia y más allá) y la combinación de países de derecho civil y religioso (en parte, Oriente Medio y África del Norte ) se encuentran cerca uno del otro en el diagrama de red.
Lista de actores y vínculos importantes
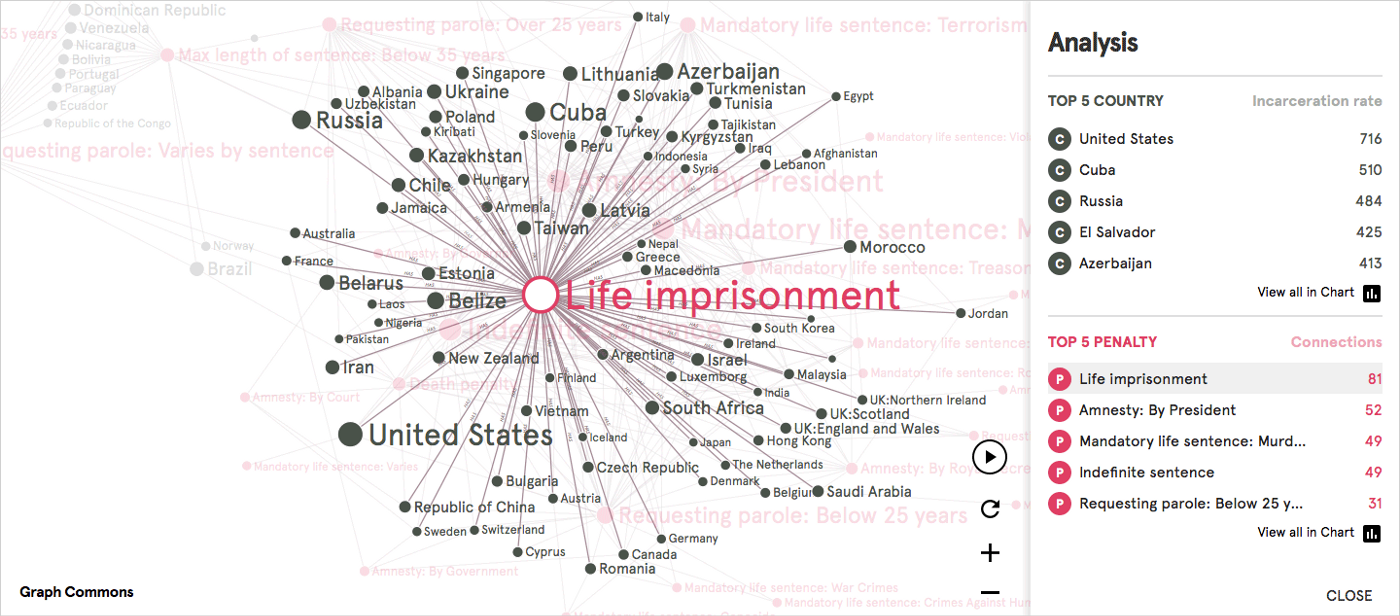
Según el tipo de red, algunos nodos pueden tener posiciones relativamente más importantes que otros. En algunas situaciones, los nodos importantes pueden definirse como centrales para la red cuando tienen muchas conexiones, o como puentes entre dos comunidades. Los nodos puente pueden ser importantes porque su eliminación puede dividir la red en partes o se vuelven demasiado poderosos, ya que son el intermediario del flujo de información entre las comunidades.
Estados Unidos tiene la tasa de encarcelamiento más alta del mundo.
En la barra de análisis, puede enumerar los nodos principales por una propiedad numérica, en este caso, esta es una lista de países por tasas de encarcelamiento (prisioneros por cada 100 000 habitantes). Los datos de este gráfico son de 2013, Estados Unidos tenía la tasa de encarcelamiento más alta del mundo, seguido de Cuba, Rusia, El Salvador, Azerbaiyán y Belice. Los principales países actuales con altas tasas de encarcelamiento no cambiaron drásticamente. Como ves en la captura de pantalla anterior, en la lista puedes hacer clic en un país y resaltarlo para ver sus conexiones.
La cadena perpetua existe en la mayoría de los países. Se hace clic en la penalización de la lista para resaltar sus conexiones/países.
En esta red tiene sentido enumerar las penalizaciones por número de conexiones, ya que podemos conocer las penalizaciones más comunes entre estos países. La “cadena perpetua” es la más común, seguida de la “amnistía del presidente” y la “cadena perpetua por asesinato”. Es bastante preocupante ver que la pena de “Sentencia indefinida” aún se aplica en 49 países del mundo.
Las listas proporcionan un resumen de los nodos más importantes de un gráfico. Al hacer clic en un nodo de la lista, verá dónde se encuentra en la red junto con sus conexiones resaltadas.
Comparar distribuciones en gráficos
Cuando está mapeando, a menudo descubre patrones que no sabía que existían antes. Ver la distribución de todos los actores le brinda una vista cuantitativa completa de todos los nodos ordenados por propiedad, para que comprenda mejor qué actores son más importantes que otros según las métricas que elija mirar. Cuando abre un gráfico, ve la distribución de todos los nodos en un gráfico de dispersión, que proporciona un análisis comparativo de los nodos en dos ejes.
Distribución de países por tasa de encarcelamiento. A partir de esta distribución de cabeza gruesa, podemos decir que muchos países tienen altas tasas de encarcelamiento. Para ver los gráficos interactivos, haga clic en el enlace "View in Chart" en la barra de análisis.
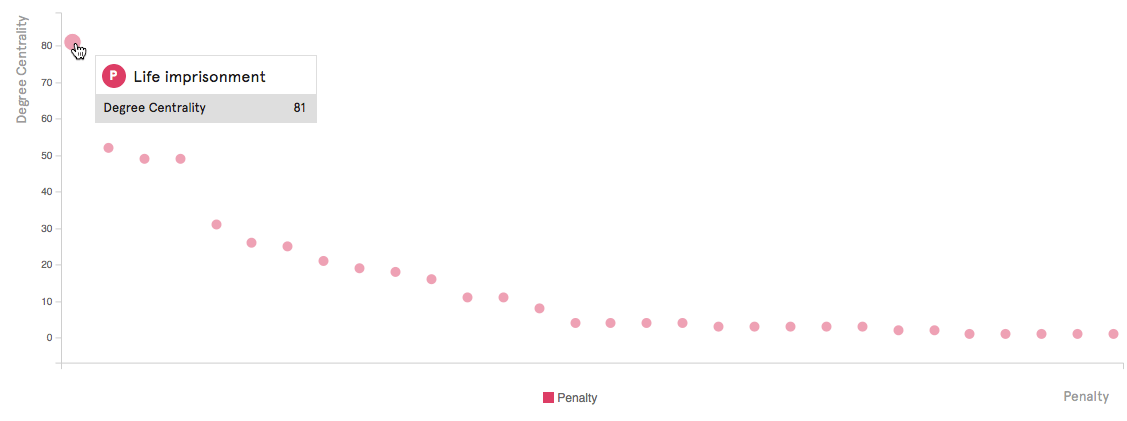
La distribución de penalizaciones por grado de centralidad (número de conexiones), que se muestra arriba, sigue ligeramente el típico diagrama de ley de potencia que se observa en las redes sin escala.
La distribución de sanciones por centralidad de intermediación se muestra arriba. Las primeras 2 y las siguientes 4 penalizaciones tienen valores de centralidad de intermediación distintivamente altos, lo que significa que tienen la mayor calidad de puente entre los diferentes grupos.
Arriba se muestra una comparación de las sanciones por grado (eje y) y valores de centralidad de intermediación (eje x). La “prisión perpetua” tiene con diferencia los valores más altos en ambos grados. En general, esta comparación es útil para encontrar valores atípicos, lo que no es realmente el caso en esta red en particular.
El uso de una interfaz híbrida que emplee mapas visuales, listas y gráficos le ayudaría a obtener una visión más profunda al analizar redes complejas.
Cómo generar conocimientos de revistas utilizando técnicas de visualización
Generación de conocimientos sobre el rendimiento de la revista Por la Dra. Daphne van Weijen y Matthew Richardson || Elsevier
Los editores y editores siempre sienten curiosidad por saber cómo se está desempeñando su revista en comparación con otras en el campo. También están ansiosos por descubrir si el contenido que están publicando está atrayendo citas. En este artículo, nos gustaría compartir con usted una serie de técnicas de visualización que pueden ayudar a generar conocimientos sobre el rendimiento de la revista.
Mapeo de términos
¿Cómo puede determinar cuáles son los temas "candentes" en una revista, grupo de revistas o área temática específica? O, más específicamente, ¿qué temas han mostrado un crecimiento activo y un fuerte impacto en la producción de investigación (artículos publicados) en los últimos años? Para responder a esta pregunta, desarrollamos una nueva herramienta de visualización en colaboración con el grupo de investigación CWTS, que se especializa en bibliometría en la Universidad de Leiden. La herramienta tiene acceso a todas las revistas y actas de congresos indexados en Scopus. A partir de esta información, puede generar mapas que revelen las relaciones entre los términos utilizados en los títulos y los resúmenes de los artículos publicados en una o más revistas seleccionadas. Lo hace con la ayuda de un programa de computadora llamado VOSviewer (1). ¿Cómo se crea un mapa de términos?
Hay una serie de pasos involucrados en la producción de un mapa de términos.
Primero debemos determinar qué revista o revistas deben incluirse. Si un grupo de revistas o un área temática es el foco del análisis, una búsqueda de palabras clave en Scopus puede ayudar con esto.
Una vez elegidas las revistas, la herramienta realiza un análisis de las palabras y frases encontradas en los títulos y resúmenes de los artículos durante un período de tiempo específico (por ejemplo, en los últimos dos, cinco o diez años). Las ventanas de publicación y cita pueden tener valores separados, por lo que también es posible determinar qué tan bien se ha citado el contenido publicado en un año específico en los años posteriores a la publicación.
Después de que se genera un mapa, se puede verificar si hay términos no informativos, como nombres de editoriales o sociedades, y términos genéricos como "literatura", "presentación" o "característica". Estos se pueden eliminar y, si es necesario, se puede crear una nueva versión del mapa.
Grupos de términos concurrentes
El mapa que se muestra en la Figura 1 se conoce como mapa de conglomerados de co-ocurrencia. Cada término que aparece al menos cinco veces en los títulos y resúmenes de los artículos de las revistas seleccionadas está representado por un nodo individual en el mapa. Cuanto más grande es el nodo, más artículos contienen el término y cuanto más pequeño es el espacio entre los términos, más a menudo tienden a coexistir. Sin embargo, es importante señalar que esta es una representación 2D de una red multidimensional, por lo que la proximidad de los términos no puede reflejar perfectamente la relación en todos los casos. Finalmente, los términos están coloreados en grupos de términos que tienden a coexistir.
Verde (centro y arriba a la izquierda) relacionado con estadísticas y experimentos;
grupo rojo (lado derecho) relacionado con la educación en enfermería;
grupo azul (abajo a la izquierda) relacionado con la cirugía; y
grupo amarillo (izquierda) relacionado con ensayos clínicos y revisiones de la literatura.
La experiencia en el campo puede ayudar a verificar y nombrar adecuadamente los clústeres, así como a predecir qué clústeres es probable que contengan el contenido más citado y por qué.
Figura 1 - Mapa de similitud de clústeres de co-ocurrencia de términos de revistas para un grupo de seis revistas de enfermería seleccionadas de 2009-2012. Fuente: Scopus. Figura 1 - Mapa de similitud de clústeres de co-ocurrencia de términos de revistas para un grupo de seis revistas de enfermería seleccionadas de 2009-2012.Fuente: Scopus.
Términos muy citados
El siguiente paso para determinar los temas candentes en el campo es verificar qué términos se citan relativamente bien en comparación con el resto del contenido publicado en la (s) revista (s). Esto se puede hacer cambiando el color en el mapa de conglomerados para mostrar el impacto medio de las citas de los artículos que contienen ese término, en relación con el impacto medio de las citas (1,00) de todos los artículos incluidos en el mapa (Figura 2). Como las publicaciones más antiguas han tenido más tiempo para ser citadas, las citas se normalizan por año de publicación para hacer posible una comparación justa. En la Figura 2, los términos con un impacto de citas por encima del promedio están coloreados en rojo, los términos con un impacto de citas promedio son verdes y los términos con un impacto de citas por debajo del promedio se muestran en azul.
Figura 2 - Mapa de impacto de citas de co-ocurrencia de términos de revistas para un grupo de seis revistas de enfermería seleccionadas de 2009-2012. Fuente: Scopus Figura 2 - Mapa de impacto de citas de co-ocurrencia de términos de revistas para un grupo de seis revistas de enfermería seleccionadas de 2009-2012. Fuente: Scopus
Podemos ver claramente que los términos relativamente citados tienden a aparecer a la izquierda del mapa. Estos son términos que se encuentran principalmente en los grupos amarillo y verde de la Figura 1, relacionados con experimentos (verde) y ensayos clínicos (amarillo). Los términos muy citados en estas áreas incluyen:
Nurse staffing, self-esteem y statistical terms (Dotación de personal de enfermería, autoestima y términos estadísticos) (grupo verde, arriba a la izquierda).
Depressive symptoms, meta-analysis, pregnancy y controlled trials (Síntomas depresivos, metaanálisis, embarazo y ensayos controlados) (grupo amarillo, lado izquierdo).
¿Temas de actualidad?
Finalmente, se puede realizar una búsqueda de palabras clave de Scopus para los términos en el mapa con el mayor impacto relativo de citas, para determinar si se trataba de ocurrencias aisladas. El resultado de esta búsqueda de palabras clave, restringida al campo de enfermería, confirmó que había al menos cuatro áreas en este análisis que tenían una tasa de crecimiento anual compuesta (CAGR) de más del 5 por ciento, lo que indica que hubo un aumento por encima del promedio en el número de artículos publicados en estas áreas durante los últimos cinco años, ya que el CAGR promedio es del 3 al 5 por ciento (ver Tabla 1).
Tabla 1 - En la Figura 2, se identificaron términos relativamente citados. En esta tabla, enumeramos la cantidad de artículos que presentan esos términos junto con sus tasas de crecimiento anual compuestas.Fuente: Scopus
La búsqueda de palabras clave de Scopus confirmó que los temas sugeridos por el mapa eran de hecho temas que han estado llamando la atención en el campo. Aunque este mapa específico a nivel de campo es algo genérico, proporciona una idea general de dónde buscar temas candentes con más detalle.
Experiencias de un editor El Dr. Paul H. Gobster es un científico social investigador del Servicio Forestal del Departamento de Agricultura de los Estados Unidos (USDA). Acaba de dimitir después de cuatro años como coeditor en jefe de Landscape and Urban Planning de Elsevier, permaneciendo en la junta de la revista como editor asociado. Él y sus colegas utilizaron mapas de términos para ayudar en el desarrollo de un editorial para el 40 aniversario de la revista (2).
El Dr. Gobster dijo: “Identificamos conceptos y temas importantes representados en su contenido publicado y desarrollamos una serie de tiempo de cuatro mapas para describir cualitativamente los cambios en cada década sucesiva.
“El término mapas fue relativamente fácil de interpretar y produjo visualizaciones adecuadas para presentarlas a los lectores dentro de nuestra editorial. Creo que el término mapas tiene un valor adicional para las funciones de planificación estratégica y administrativa de la revista; la agrupación puede ayudar a aclarar el contenido temático para la clasificación de manuscritos y la asignación de presentaciones a los editores asociados, y los grupos y términos específicos (su presencia, posiciones y cualquier cambio). con el tiempo) puede ayudar a identificar subtemas de trabajo emergentes y duraderos ".
Los beneficios del mapeo de revistas
Mientras que los mapas de términos se utilizan para resaltar los temas publicados dentro de una revista o disciplina, el mapeo de revistas se puede utilizar para examinar la posición y el alcance de una revista y sus interacciones con otras revistas en el campo. Al igual que con los mapas de términos, Scopus puede proporcionar los datos de origen, lo que garantiza que el análisis se base en todas las revistas indexadas.
Estos mapas de revistas se crean mediante enlaces de citas. Una cita de un artículo publicado en una revista a un artículo publicado en otra establece que sus respectivos contenidos son relevantes entre sí y sugiere un nivel de similitud entre los dos. En un período de tiempo dado, una revista tiende a contener citas de muchas otras revistas, y las que más cita deben ser las revistas con las que está más estrechamente relacionada. Por ejemplo, si la Revista A proporciona muchas citas a la Revista B y solo unas pocas a la Revista C, esto es una señal de que tiene una conexión más fuerte con la Revista B. Si con el tiempo el saldo cambia de modo que comienza a proporcionar más citas a la Revista. C, esto indica que el alcance de las revistas o la estructura del campo está cambiando y se está volviendo progresivamente más relacionado con la Revista C. Cuando los enlaces de citas se construyen en muchas más revistas que en este ejemplo simplificado, un mapa es una opción conveniente. forma de mostrar los enlaces y ver cómo interactúan las revistas para formar grupos más grandes.
Consulte la Figura 3 para ver un ejemplo de un mapa de revistas basado en las mismas seis revistas de enfermería utilizadas en los ejemplos de mapas de términos anteriores.
Figura 3 - Mapa de revistas basado en un grupo de seis revistas de enfermería seleccionadas de 2009-2012
Cada revista en el mapa se muestra como un nodo (círculo), con el tamaño determinado por el promedio de citas a los artículos de esa revista en el período de tiempo. Puede ver en la Figura 3 que las revistas de medicina general incluidas en el mapa tienen un impacto promedio de citas mucho más alto que las otras revistas. Las revistas seleccionadas están en azul y todas pertenecen a la región de las revistas principales de enfermería, mientras que otras revistas están en gris y se incluyen debido a sus enlaces de citas a estas revistas semilla. Las relaciones de citas se muestran como bordes (líneas) de grosor variable. Estas relaciones de citas se normalizan por el número de citas recibidas por la revista citada y por el número de citas dadas por la revista que cita. Cuanto más gruesa sea la línea, mayor será la proporción de citas representadas.
En este ejemplo de mapeo, las áreas clave de las diferentes especialidades de las ciencias de la salud se han etiquetado en función de los grupos de revistas. Esto le permite ver los vínculos entre especialidades más amplias, así como revistas individuales. Estas agrupaciones tenderán a ser bastante estables, pero comparar mapas basados en diferentes períodos de tiempo le permite identificar revistas emergentes en un área determinada o las relaciones de investigación cambiantes que hacen que un área temática se vuelva más relevante para otra con el tiempo.
El entorno de citas en el que se encuentra una revista es único y dinámico, y el análisis de este puede utilizarse como un medio objetivo para determinar la posición competitiva de una revista establecida en un campo de investigación.
Usar los mapas para respaldar su trabajo
Tanto el mapeo de términos como el mapeo de revistas pueden ayudar a comparar la revista con la competencia y proporcionar información útil para las reuniones del consejo editorial. Si bien en el texto anterior se han sugerido algunas razones estratégicas para usar estas herramientas analíticas, su ventaja real radica en cuán adaptables son a diferentes preguntas de investigación. Si desea saber más acerca de cómo estas herramientas pueden ayudarlo, u otras herramientas analíticas para proporcionar información sobre la posición de su revista, comuníquese con su editor.
Referencias
(1) Van Eck, N.J., & Waltman, L. (2010) “Software survey: VOSviewer, a computer program for bibliometric mapping”, Scientometrics, Vol 84, No. 2, pp. 523–538.
(2) Gobster, P.H. (2014) “(Text) Mining the LANDscape: Themes and trends over 40 years of Landscape and Urban Planning”, Landscape and Urban Planning, Vol 126, pp. 21–30.
Usando la inteligencia artificial para encontrar los bloques de construcción de nuestras relaciones
Luca Maria Aiello || Medium
Las relaciones sociales son primordiales. Determinan dónde trabajamos, con quién nos casamos y qué hacemos. Es por eso que los investigadores de ciencias sociales, y más recientemente sus primos de "ciencias sociales computacionales", dedicaron considerables esfuerzos para establecer categorizaciones sistemáticas de las dimensiones sociológicas fundamentales que describen las relaciones humanas. Intentamos descubrir cuáles son las dimensiones fundamentales de las relaciones sociales y cómo detectarlas automáticamente a partir de los datos de interacción en línea.
Al compilar una extensa revisión de los hallazgos de décadas en sociología y psicología social, identificamos diez dimensiones que se han utilizado ampliamente para clasificar las relaciones:
Intercambio de conocimiento
Dinámica de poder (p. Ej., Entre un jefe y su empleado)
Condición de estado: conferir apreciación, gratitud o admiración.
Expresiones de confianza
Dar apoyo emocional o práctico
Romance
Similitud: intereses, motivaciones o perspectivas compartidas
Identidad: sentido de pertenencia a un grupo o comunidad
Divertido
Conflicto
Resulta que las personas encuentran estas dimensiones muy identificables. A través de un pequeño experimento de crowdsourcing, le pedimos a 200 personas que deletrearan palabras que describieran sus conexiones sociales y descubrimos que todas encajaban en las 10 dimensiones.
Ser capaz de cuantificar estas 10 dimensiones a partir de los datos de interacción es bastante útil porque, combinándolos en proporciones oportunas, se puede dibujar una descripción precisa, explicable e intuitiva de la naturaleza de la mayoría de las relaciones.
En nuestro trabajo que se presentará en The Web Conference 2020, utilizamos el procesamiento del lenguaje natural para medir las 10 dimensiones del texto conversacional. Le pedimos a los trabajadores colectivos que etiqueten 9,000 comentarios de Reddit con las 10 dimensiones. Utilizamos estos datos para entrenar herramientas de IA que pueden predecir todas las dimensiones con bastante precisión a partir de cualquier texto, para 🤓 ojos: usando BERT y LSTM obtuvimos AUC que van desde 0.75 (Identidad) a 0.98 (Romance).
Y ahora, la parte divertida. Aplicamos nuestra herramienta a los datos en línea para descubrir cómo se utilizan las 10 dimensiones en diferentes contextos y en diferentes niveles de agregación: mensajes individuales, relaciones, grupos e incluso Estados enteros en los EE. UU.
Dimensiones sociales en mensajes individuales - guiones de películas
Los diálogos con guiones de películas son representaciones ficticias pero plausibles de conversaciones que abarcan un amplio espectro de emociones humanas y tipos de relaciones. Ejecutamos nuestros modelos en todas las líneas de películas del corpus de guiones de películas de Cornell, y descubrimos cuáles son las dimensiones transmitidas por las líneas de películas icónicas.
A continuación, algunas líneas de algunas películas icónicas del siglo XX. Informamos los niveles detectados de las 10 dimensiones en los diagramas de inserción; los que están por encima de la línea punteada son los más significativos.
“Solo un Caballero Jedi completamente entrenado, con La Fuerza como su aliado, conquistará a Vader y su Emperador. Si terminas tu entrenamiento ahora, si eliges el camino rápido y fácil, como lo hizo Vader, te convertirás en un agente del mal "- Ben Kenobi
Ben transfiere su conocimiento de los caminos de la Fuerza a Luke. Esta línea destaca la relación de poder entre el maestro y el alumno, y advierte sobre conflictos inminentes.
"Frankie, eres un buen anciano y has sido leal a mi padre durante años ... así que espero que puedas explicar lo que quieres decir" - Michael Corleone
A Michael le gusta pensar en sí mismo como un hombre de honor. Él rinde homenaje a su amigo por sus servicios y le otorga confianza a raíz de las sospechas de traición.
"Mira, Dave, sé que eres sincero y que estás tratando de hacer un trabajo competente, y que estás tratando de ser útil, pero puedo asegurarte que el problema está en las unidades AO y en tu equipo de prueba "- HAL 9000
Parece que la supercomputadora HAL 9000 está tratando de proporcionar algún soporte técnico (= conocimiento + soporte) a un astronauta cada vez más preocupado.
"Pero, como le gusta tanto observar, doctor, no soy humano" - Spock
La identidad de un vulcano, expresada ante el sacrificio extremo.
Dimensiones sociales en las relaciones - Twitter
La "Isla de los lazos" es uno de los juegos de tinghy.org. Los jugadores marcan a sus amigos de Twitter con 3 dimensiones que mejor describen sus relaciones con ellos.
Las dimensiones estimadas a nivel de mensaje pueden predecir las dimensiones que las personas usarían para describir sus relaciones sociales. Para demostrarlo, recopilamos datos de tinghy.org, una plataforma de juegos que recoge las percepciones de las personas sobre sus amigos de Twitter (ver foto a la izquierda). Descubrimos que podemos obtener buenas predicciones de las etiquetas de nivel de relación (por ejemplo, una relación basada en la confianza) mirando 20 respuestas de Twitter o más entre las dos personas involucradas.
Dimensiones sociales de las comunidades - Enron corp. correos electrónicos
Enron Corporation era una empresa estadounidense fundada en 1985 que se declaró en quiebra en 2001, cuando sus prácticas sistemáticas de fraude contable fueron expuestas al público. Después del escándalo y la investigación resultante, The Enron Email Dataset fue lanzado al público. Observamos cómo las expresiones de diferentes dimensiones variaban con el tiempo en los correos electrónicos de Enron, en promedio.
Cómo la presencia de cinco dimensiones sociales en los correos electrónicos de los empleados de Enron cambia con el tiempo, en comparación con el análisis de sentimientos tradicional (realizado con la herramienta Vader). Las parcelas están marcadas con cuatro eventos importantes en la historia de Enron: i) el comienzo de las preocupaciones sobre la estabilidad financiera de la empresa; ii) la primera ronda de despidos; iii) el inicio de pérdidas financieras; iv) la declaración de quiebra.
La evolución de las dimensiones conversacionales revela una imagen rica que coincide con las etapas conocidas de la caída de Enron. Cuando surgieron las preocupaciones iniciales, el intercambio de estatus y apoyo se desplomó: el pánico comenzó a extenderse y los empleados dejaron de celebrar sus logros, agradeciéndose mutuamente y ofreciendo consuelo. Aproximadamente tres meses después, la frecuencia del intercambio de conocimientos se redujo drásticamente: a medida que aumentaron las preocupaciones, los empleados dedicaron menos tiempo a ocuparse de sus tareas cotidianas. Unas semanas antes de los despidos, cuando quedó claro que muchos empleados habrían sido despedidos, el conflicto explotó y la estructura de poder colapsó: se dieron menos órdenes a la multitud de empleados enojados que se dieron cuenta de los recortes de empleos que obstaculizaban. A raíz de los despidos, los que lograron permanecer en la empresa se apoyaron durante unas semanas antes del inminente crack.
Dimensiones sociales en la sociedad - Estadísticas de los Estados Unidos
Por último, probamos si la presencia de esas dimensiones en las conversaciones está asociada con los resultados del mundo real a nivel social. Extrajimos las diez dimensiones sociales de 160 millones de mensajes de Reddit publicados por 1 millón de usuarios a quienes pudimos geo-referenciar a nivel de los Estados Unidos. Realizamos un análisis geográfico para estudiar la relación entre la presencia de las 10 dimensiones y los resultados socioeconómicos, estimados por las estadísticas oficiales. En particular, verificamos la relación entre:
Intercambio de conocimiento y nivel de educación promedio.
Intercambio de conocimientos e ingresos medios.
Expresión de apoyo social y tasas de suicidio
Como se esperaba, el conocimiento está positivamente asociado a los niveles de educación y a la riqueza: el intercambio de conocimiento es un motor de innovación y crecimiento económico. El apoyo se asocia positivamente con las tasas de suicidio: las personas afectadas por la depresión, especialmente aquellas que tienen pensamientos suicidas, no tienden a confiar en sus compañeros y buscan apoyo social en diferentes contextos, a menudo en línea.
Todas las dimensiones combinadas predicen las estadísticas oficiales con bastante precisión (hasta un R2 ajustado de 0,52), incluso después de descontar los factores de confusión como la densidad de población.
Las expresiones de las dimensiones sociales en el lenguaje en línea se correlacionan con los resultados sociales relevantes estimados por las estadísticas oficiales a nivel de los Estados Unidos.
¿Para qué es todo esto?
La capacidad de extraer automáticamente las dimensiones fundamentales del intercambio social del texto podría contribuir a crear herramientas de investigación y análisis para las redes sociales. Creemos que la dinámica de una serie de procesos mediados por las redes sociales podría reinterpretarse con nuestra aplicación del modelo de 10 dimensiones a las redes de conversación. Por ejemplo, los investigadores podrían observar los fenómenos de difusión de información, difusión de noticias falsas, polarización y creación de enlaces a la luz de las diez dimensiones sociales.
Las empresas de redes sociales podrían monitorear la prevalencia de las diez dimensiones en el discurso público en línea como una forma de detectar y promover interacciones positivas y significativas, por ejemplo, aquellas basadas en el apoyo y la confianza, en lugar de simplemente castigar el mal comportamiento.
En este artículo, propongo un método y una herramienta para medir el nivel de sesgo en el discurso basado en el análisis de red de texto. La medida se basa en la estructura del texto y utiliza parámetros cuantitativos y cualitativos de un gráfico de texto para identificar qué tan sesgado es. Por lo tanto, puede ser utilizado por humanos, así como implementarse en varias API y AI para realizar un análisis de sesgo automático.
Sesgo: lo bueno y lo malo
El sesgo se entiende comúnmente como inclinación o prejuicio hacia un cierto punto de vista. Un discurso o texto que tiene un sesgo puede tener una determinada agenda o promover cierta ideología.
En la era de las "noticias falsas", el surgimiento de ideologías extremas y varias técnicas de desinformación es importante poder identificar el nivel de sesgo en el discurso: ya sean publicaciones en redes sociales, artículos periodísticos o discursos políticos.
El sesgo no es necesariamente algo malo. A veces puede hacer que una intención sea más fuerte, impulsar una agenda, hacer un punto, persuadir, disuadir y transformar. El sesgo es un agente de cambio, sin embargo, cuando hay demasiado de él, el sesgo también puede ser destructivo. Cuando medimos el sesgo medimos qué tan cargado ideológicamente es un texto, cuánto quiere expresar un cierto punto de vista. En algunos contextos, como ficción o discursos políticos muy cargados, un sesgo fuerte puede ser preferencial. En algunos otros contextos, como noticias o no ficción, un fuerte sesgo puede revelar una agenda.
Actualmente no hay herramientas que puedan medir el sesgo de un texto. Varias API de minería de textos clasifican los textos según su contenido y sentimiento, pero no hay instrumentos que puedan medir el nivel de inclinación hacia un cierto punto de vista en el texto. El instrumento y el método propuesto en este artículo pueden servir como el primer paso en esta dirección. La herramienta en línea de código abierto para el análisis de redes de texto que desarrollé ya puede medir el sesgo en función de esta metodología, por lo que le invitamos a probarlo en sus propios textos y ver cómo funciona. A continuación describo cómo funciona el índice de sesgo y algunos detalles técnicos.
La estructura del discurso como red dinámica.
Cualquier discurso puede representarse como una red: las palabras son los nodos y sus coincidencias son las conexiones entre ellos. El gráfico resultante traza las vías de circulación de significado. Podemos hacerlo más legible alineando los grupos de nodos que están más densamente conectados (algoritmo de atlas de fuerza) en los distintos grupos marcados con un color específico. También podemos hacer que los nodos más influyentes sean más grandes en el gráfico (los nodos con la centralidad de alta intermediación). Puede leer más sobre los detalles técnicos en este documento técnico sobre análisis de red de texto.
Por ejemplo, aquí hay una visualización de la charla de TED de Julian Treasure llamada “How to Speak So People Will Want to Listen”, realizada con este método. Si está interesado en ver el gráfico interactivo real, puede abrirlo aquí.
De este grafo podemos ver claramente que los conceptos principales son las nociones de
“people”, “time”, “world”, “listen”, “voice” etc.
Estos conceptos son las uniones para la circulación del significado en ese discurso en particular. Conectan las diferentes comunidades de nodos (designadas por distintos colores).
El algoritmo funciona de una manera que emula la percepción humana (siguiendo el modelo de lectura del paisaje, la idea de cebado semántico y también el sentido común): si las palabras se mencionan con frecuencia en el mismo contexto, formarán una comunidad en el gráfico. Si aparecen en diferentes contextos, se alejarán unos de otros. Si las palabras se usan con frecuencia para conectar diferentes contextos, aparecerán más grandes en el gráfico.
Como resultado, la estructura de un grafo de red de texto puede decirnos mucho sobre la estructura del discurso.
Por ejemplo, si el gráfico tiene una estructura de comunidad pronunciada (varias comunidades de palabras diferentes), el discurso también tiene varios temas distintos, que se expresan en el texto. En nuestro ejemplo tenemos al menos 4 temas principales:
people — listen — speak (dark green)
time —talk —register (light green)
world—sound—powerful (orange)
amazing—voice (pink)
Si analizamos otros textos de la misma manera, veremos que las estructuras gráficas resultantes son diferentes. Por ejemplo, aquí hay una visualización del primer capítulo de Quaran:
Visualización de la red de texto de Quaran realizada con InfraNodus. La estructura del gráfico es menos diversificada y más centralizada. Hay solo unos pocos conceptos principales, el discurso circula alrededor de ellos, el resto del texto apoya los conceptos principales.
Se puede ver que tiene una estructura de red diferente. Es mucho más centralizado y menos diversificado. Hay algunos conceptos principales:
“god”, “people”, “believe”, “lord”, “give”
y todo el discurso circula en torno a estos conceptos. Todas las otras nociones están ahí para apoyar las principales.
Realizamos un análisis similar con los discursos de inauguración de los presidentes de EE. UU. De 1969 a 2013 y visualizamos la forma en que su narrativa cambió con el tiempo:
Visualización de los discursos de inauguración de los presidentes de los Estados Unidos realizados con InfraNodus (TNA) y Gephi (visualización). Se puede ver que con el tiempo la estructura se mantiene más o menos igual, sin embargo, los discursos de Obama parecen tener términos influyentes más distintos, lo que indica un discurso más diversificado.
Se puede ver que mientras la estructura del discurso se mantuvo más o menos igual a lo largo de los años, mientras que los conceptos enfatizados han cambiado con cada dirección. Esto puede indicar que la estrategia retórica se mantuvo igual, mientras que el contenido se ha transformado con los años. Los discursos de Obama parecen tener un mayor número de nodos influyentes distintos, lo que puede indicar un discurso más diversificado.
El sesgo como un conducto para la ideología en las redes
Ahora que hemos mostrado cómo el discurso se puede representar como una estructura de red, podemos discutir la noción de sesgo en el contexto de la ciencia de redes. Usaremos algunas ideas para la epidemiología para demostrar cómo la topología de la red afecta la velocidad y la propagación de la información a través de los nodos.
Una red se puede ver como una representación de las interacciones que ocurren a lo largo del tiempo, un diagrama de los rastros dejados por un proceso dinámico. Si estudiamos la topología de una red, podemos obtener una gran cantidad de información sobre la naturaleza de los procesos dinámicos que representa.
En el contexto de las ciencias sociales y de la atención médica, la información sobre la estructura de la red puede proporcionar información valiosa para la epidemiología: qué tan rápido se puede propagar una enfermedad (un virus, una opinión o cualquier otra (mala) información), qué tan lejos puede propagarse, qué es lo mejor. Las estrategias inmunológicas pueden ser.
Se ha demostrado (Abramson & Kuperman 2001; PastorSatorras & Vespignani 2001) que a medida que la estructura de una red se vuelve más aleatoria, su umbral epidemiológico disminuye. Las enfermedades, los virus, la desinformación pueden propagarse más rápido y a un mayor número de nodos. En otras palabras, como la estructura de la comunidad de una red es cada vez menos pronunciada y el número de conexiones aumenta, la red propaga información a más nodos y esta propagación se produce en oscilaciones altamente pronunciadas (infectadas / no infectadas).
Una figura del estudio de Abramson y Kuperman (2001) donde se muestra la fracción de elementos infectados (n) en relación con el tiempo (t) para redes con un grado diferente de trastorno (p). Cuanto mayor es el grado de desorden, más elementos se infectan, las oscilaciones se intensifican más y más, pero también el lapso de tiempo de la infección es relativamente corto.
Al mismo tiempo, cuando la estructura de la comunidad se pronuncia mientras la red está relativamente interconectada (red de mundo pequeño), los “bolsillos” de los nodos ayudan a mantener la enfermedad epidémica durante más tiempo en la red. En otras palabras, menos nodos pueden infectarse, pero la infección puede permanecer más tiempo (estado endémico).
Representación de estructuras de red: [a] aleatoria, [b] libre de escala (comunidades mejor pronunciadas) y, [c] jerárquica (menos conectividad global) (de Stocker et al. 2001)
En otro estudio realizado en varias redes sociales (Stocker, Cornforth y Bossomaier 2002) se ha demostrado que las redes jerárquicamente planas (es decir, desordenadas) no son tan estables como las que no tienen escala (es decir, las que tienen una estructura comunitaria más pronunciada ). En otras palabras, las jerarquías pueden ser buenas para pasar las órdenes, pero las estructuras sin escala son mejores para mantener una cosmovisión determinada.
Como podemos ver, no hay una topología de red que pueda considerarse preferencial. De hecho, depende de la intención, el contexto, la situación. En algunos casos, puede ser bueno si una red puede propagar información fácilmente a todos sus elementos relativamente rápido. En algunos otros casos la estabilidad puede ser más preferencial.
En general, la topología de una red refleja qué tan bien puede propagar la información, qué tan susceptible es a las nuevas ideas, si las ideas se apoderarán de toda la red solo durante un breve período de tiempo o permanecerán durante un período más largo.
El mismo enfoque se puede aplicar cuando estudiamos el sesgo. El supuesto aquí es que una red de discurso es una estructura que propaga ideas.
Si la estructura del discurso se centra en unos pocos nodos influyentes y no hay una estructura de comunidad pronunciada, significa que el discurso es bastante homogéneo y las ideas en torno a esos nodos se propagarán mejor que las ideas de la periferia. Designamos dicho discurso como parcializado.
Si, en el otro lado, una red de discurso consta de varias comunidades distintas de palabras / nodos (red de pequeño mundo sin escala) significa que hay varios temas distintos dentro del texto y cada uno de ellos recibe la misma importancia dentro del discurso. . A este discurso lo llamamos diversificado.
Una estructura de comunidad de red se puede identificar no solo de manera cualitativa mediante una visualización gráfica, sino también a través de la medida de modularidad (consulte Blondel et al 2008). Cuanto mayor sea la modularidad (generalmente por encima de 0,4), más pronunciada es la estructura de la comunidad.
Otro criterio importante es la distribución de la influencia (a través de las palabras / nodos más influyentes) en diferentes comunidades. Para que un discurso se diversifique, los nodos más influyentes deben distribuirse entre las diferentes comunidades. Utilizamos la entropía para medir la dispersión de influencia en el gráfico y tener esto en cuenta al identificar el nivel de sesgo. También verificamos si las comunidades principales incluyen un número de nodos desproporcionadamente alto, en cuyo caso el puntaje de diversificación disminuye y el número de componentes en el gráfico.
Por lo tanto, podemos identificar los tres criterios principales que podemos usar para identificar el nivel de sesgo en el discurso:
Estructura de la comunidad: cuán distintos son y el% de nodos que pertenecen a las comunidades principales;
Distribución de la influencia: cómo los nodos / palabras más influyentes se reparten entre los diferentes temas / comunidades gráficas;
Número de componentes del gráfico: cómo está conectado el discurso;
El índice de sesgo basado en la estructura del discurso
Sobre la base de las proposiciones y los criterios anteriores, proponemos el Índice de sesgo que tiene en cuenta la estructura del discurso y tiene cuatro parámetros principales:
Dispersado (sin sesgo)
Diversificado (sesgado localmente)
Enfocado (ligeramente parcial)
Sesgado (muy sesgado)
El primer valor, Dispersed, es un discurso que tiene una estructura de comunidad muy pronunciada (varios temas distintos) que no están muy bien conectados o tiene varios componentes (y, por lo tanto, ningún sesgo). Nuestras pruebas muestran que dichos gráficos se producen generalmente para poesía, notas personales, tweets esquizofrénicos y varios otros esfuerzos creativos. Por ejemplo, aquí hay una visualización del poema de Lord Byron "Darkness" (también puede consultar el gráfico interactivo en InfraNodus):
Visualización de la "Darkness" de Lord Byron realizada utilizando InfraNodus. La estructura del discurso se identifica como Dispersada (vea el panel de Análisis a la derecha) debido a la alta modularidad (0.68) y la alta influencia de la dispersión (las palabras más influyentes se difunden entre las diferentes comunidades y solo el 14% de las palabras están en la parte superior comunidad).
Como podemos ver en el gráfico, es bastante escaso visualmente y nuestra herramienta ha identificado la estructura del discurso como Dispersada porque la medida de modularidad es bastante alta (comunidades / temas pronunciados) y los nodos / palabras influyentes se distribuyen bastante equitativamente entre los temas principales (80 % de dispersión y solo el 14% de las palabras en la comunidad / tema superior). Si lees el poema mismo, verás que tiene un vocabulario bastante rico y que evoca muchas imágenes diversas, sin tratar de impulsar una agenda específica (quizás solo a través de medios poéticos, no retóricos).
El siguiente valor, Diversificated, es un discurso que tiene una estructura de comunidad pronunciada pero donde las comunidades están bien conectadas. Por lo general, indica un discurso que refleja varias perspectivas diferentes y les otorga una posición más o menos igual en el nivel global (sesgo local). Muchos artículos y charlas que tienen como objetivo presentar varios puntos de vista, notas de investigación, titulares de periódicos (tomados de una variedad de fuentes) y piezas de no ficción tendrán esta estructura. Por ejemplo, aquí hay una visualización de los titulares de las noticias (con teasers) del 4 de octubre de 2018 (vea la visualización interactiva aquí):
Visualización de los titulares de noticias y teasers (a través de RSS) realizada con InfraNodus para el 4 de octubre de 2018, tomada de NYT, WSJ, FT, The Guardian y Washington Post. Como podemos ver, la selección de noticias se clasifica como Diversificada, ya que la medida de modularidad es relativamente alta y, sin embargo, los temas también están relacionados entre sí. Las palabras más influyentes se reparten entre los principales grupos / comunidades tópicas, lo que indica que la selección de noticias fue bastante diversa.
Podemos ver que la estructura del discurso está clasificada como diversificada, lo que significa que hay varios temas distintos que se desarrollan dentro de este discurso y, sin embargo, están conectados a nivel global.
El tercer valor, Focused, indica un discurso que tiene un sesgo suave hacia un tema determinado. Por lo general, esto significa que el discurso presenta varias perspectivas, pero se enfoca en una sola, y lo desarrolla aún más. Las estructuras del discurso con el puntaje Enfocado son características de los artículos periodísticos, ensayos, informes, que están diseñados para proporcionar una representación clara y concisa de una idea determinada. Por ejemplo, aquí hay una visualización de las tres partes anteriores de este artículo:
Las tres secciones anteriores de este artículo se visualizan como un gráfico de texto utilizando InfraNodus. Podemos ver que la estructura del discurso está clasificada como Enfocada, lo que indica un ligero sesgo. La estructura de la comunidad está presente, pero no son muy distintas. Casi todas las palabras más influyentes se concentran en una comunidad / tema: "red / estructura / discurso" y luego hay un tema más pequeño con "texto / sesgo / medida".
Finalmente, el cuarto tipo de estructura del discurso es parcial, que es característico de los textos que tienen una estructura de comunidad baja o nula. Las ideas principales se concentran juntas y todas las otras nociones utilizadas en el texto están ahí para apoyar la agenda principal. Dicha estructura de discurso generalmente se puede observar en textos altamente ideológicos, discursos políticos y cualquier otro texto, que recurre a la retórica para persuadir a las personas a actuar. Por ejemplo, aquí hay una visualización de El Manifiesto Comunista:
Visualización de red de texto del Manifiesto comunista utilizando InfraNodus. La estructura de la comunidad no se pronuncia y las palabras más influyentes pertenecen a los dos temas principales y están altamente interconectadas. El resto del discurso está subyugado hacia la agenda principal (lucha de clases).
Epílogo
En este artículo, propuse una medida del sesgo del discurso en función de la estructura de la visualización de la red de texto y de varios parámetros que se pueden obtener a partir del análisis gráfico.
Es importante tener en cuenta que no afirmo (todavía) que las proposiciones que hice son científicamente sólidas. Un estudio completo sobre un corpus de datos mucho más grande está en camino (es bienvenido a unirse).
Mi experiencia muestra que este índice puede ser útil al estudiar textos y ya está implementado como una característica de trabajo en la herramienta de visualización y análisis de red de texto InfraNodus.
Por lo tanto, los invito a que lo prueben usted mismo y me envíen cualquier comentario, sugerencia y propuesta que puedan tener. Por favor, siéntase libre de dejar cualquier comentario aquí, estaría muy curioso de ver lo que piensa y cómo podemos desarrollarlo más. InfraNodus es una herramienta de código abierto, por lo que le invitamos a unirse e implementar cualquier propuesta que pueda tener como código.
La visualización de redes de texto de los resultados de búsqueda de Google puede ser muy útil para las comprobaciones de optimización de motores de búsqueda (SEO). Los fragmentos de texto que los motores de búsqueda muestran en sus resultados de búsqueda se consideran los más relevantes para la consulta de búsqueda. Por lo tanto, sería muy útil saber qué otras palabras contienen esos fragmentos, de modo que podamos crear contenido que sea más relevante tanto para Google como para la audiencia.
Demostraremos nuestro enfoque utilizando el ejemplo de este artículo sobre análisis de redes de texto y visualización de datos para la optimización de motores de búsqueda.
Paso 1: identificar las consultas de búsqueda relevantes: contexto de SEO
Queremos que este artículo sea leído por aquellos interesados en SEO, análisis de redes de texto y visualización de datos. Entonces, el primer paso es comprender mejor lo que las personas realmente están buscando cuando buscan esos términos: el contexto. Una búsqueda rápida en la Herramienta de palabras clave de Google y la función de autosugestión de Google revela que las siguientes frases de búsqueda más destacadas se utilizan en este contexto:
en todos los casos, los usuarios están buscando
"Herramientas", "técnicas", "software" y "tutorial"
Por lo tanto, vemos que hay un gran interés para el software y los tutoriales relacionados con la optimización del motor de búsqueda, así como la visualización de datos.
Lo que significa que este artículo se escribirá específicamente para incluir esas palabras clave tanto en su título principal (etiquetas) como en todo el texto.
Paso 2: Análisis de red de texto de resultados de búsqueda de Google: visualización de datos de SEO
Ahora que sabemos lo que los usuarios realmente están buscando, necesitamos ver qué resultados de búsqueda ven realmente. Esto es importante por dos razones diferentes:
Los fragmentos de resultados de búsqueda contienen el texto que los motores de búsqueda consideran relevante para la consulta de búsqueda. Por lo tanto, sabremos qué otras palabras clave debe incluir nuestro texto para aparecer en los resultados de búsqueda.
Al utilizar la visualización de la red de texto, identificaremos las lagunas, o las áreas vacías entre los grupos de palabras clave que tienden a coincidir en los fragmentos de texto. Estas lagunas nos mostrarán lo que falta en los resultados de búsqueda, de modo que podamos incluir esas partes faltantes en nuestro texto y asegurarnos de que aparezca en la parte superior de los resultados de búsqueda de Google.
Usaremos la herramienta de visualización de red de texto InfraNodus para visualizar fragmentos de texto de diferentes resultados de búsqueda. Este instrumento nos mostrará un gráfico de las palabras que tienden a coincidir una al lado de la otra en los mismos fragmentos (de las primeras 5 páginas de resultados). También nos mostrará las palabras clave más relevantes que se utilizan con la consulta de búsqueda que estamos estudiando.
Usando la función "Importar" de InfraNodus creamos una visualización de red de texto de los siguientes términos de búsqueda:
"SEO de optimización de motores de búsqueda"
Los propios términos de búsqueda se excluyen del gráfico, por lo que podemos ver el contexto real en el que aparecen en los resultados de búsqueda.
Hay tres clústeres prominentes en este gráfico, lo que significa que esas palabras tienden a coincidir más a menudo juntas:
Esto demuestra que los resultados de búsqueda de Google básicamente tienen 3 temas principales: mejorar la visibilidad de un sitio web, optimizar el rango del sitio web de Google y también propuestas de / para agencias de marketing.
Lo que significa que si queremos encajar bien en esa constelación con nuestro artículo, tenemos que hacer dos cosas.
Primero, debemos incluir todos esos términos en este artículo (especialmente en,, y otras etiquetas). Hicimos eso de manera automática porque hemos estado escribiendo sobre las palabras anteriores.
En segundo lugar, el gráfico muestra lo que los usuarios realmente encuentran. Necesitamos proponerles algo original, algo que aún no encuentran. Esto se puede hacer cerrando las brechas en el gráfico entre los clústeres de términos de búsqueda que identificamos.
Puede jugar con el gráfico usando la interfaz a continuación. Haga clic en el icono del gráfico de la esquina superior derecha para eliminar los fragmentos de texto, haga clic en los nodos del gráfico para ver en qué resultados de búsqueda aparecen y cómo se relacionan entre sí.
Paso 3: mejore la visibilidad y el ranking de Google de la página de su sitio web - escriba algo original
Es importante notar aquí que Google todavía tiene en cuenta cuántas páginas externas se vinculan a su página y esto afectará la clasificación. Sin embargo, las palabras clave, especialmente para los sitios web que ya tienen un alto rango, son muy importantes.
Ahora demostraremos cómo puede mejorar la visibilidad y clasificación de esta página
cerrar las brechas entre los diferentes clústeres de palabras clave que aparecen en el grafo y también
proponer algo nuevo (que nuestros competidores en los resultados de búsqueda no escriben).
El primer punto ya está algo completo porque este artículo contiene todos los posibles conglomerados de palabras (contextos) que ya aparecen en los resultados de búsqueda. No nos arriesgaremos a repetirlos una vez más para evitar penalizaciones por spam de Google.
En cambio, puede ser interesante mencionar algunas veces más algunos términos que los usuarios están buscando junto con "seo" y "optimización de motores de búsqueda", pero que realmente no aparecen en los resultados de búsqueda. Estos serán mencionados más adelante.
El segundo punto también se cumple por el hecho de que estamos escribiendo sobre un nuevo tema: la visualización de la red de texto de los resultados de búsqueda de Google, que no encontrará en ningún otro lado.
Es importante tener esto en cuenta cuando se crean textos optimizados para SEO: cerrar las brechas entre diferentes temas y agregar nuevos aumentará su clasificación en los motores de búsqueda.
Paso 4: InfraNodus como herramienta SEO - Software para visualización de red de texto
Cree una cuenta (obtenga un código de invitación de nosotros), haga clic en "Importar", elija "Búsqueda de Google", escriba su consulta de búsqueda, elija el nombre para el Contexto (la categoría / lista donde se guardan los resultados), elija el número de los fragmentos de resultados de búsqueda que desea ver en el gráfico (preferimos 50), haga clic en "Guardar" y visualice el gráfico.
También puede usar el análisis de red de texto para sus textos, para que pueda ver qué tan relevantes son para las consultas de búsqueda y los resultados de búsqueda en su tema. Para hacer eso, simplemente copie y pegue el texto en InfraNodus (o use la función de importación) y se visualizará como una red:
Si excluimos los términos como "búsqueda", "seo", "optimización" que deben figurar en este texto, vemos que las palabras clave como "resultado", "google" y "palabra clave" son las más destacadas. Tal vez los dos últimos están bien, pero el primero, "resultado", no fue prominente en las consultas de búsqueda y en la búsqueda ... err ... respuestas. Por lo tanto, tendría sentido revisar este artículo y eliminar esa palabra clave, por lo que no es tan prominente.
Paso 5: Salga de la burbuja del filtro: mejore el discurso en línea
Demostramos más arriba cómo se puede usar el análisis de red de texto para optimizar las páginas de sitios web para la búsqueda. El enfoque no es nuevo, sin embargo, esperamos que las herramientas y técnicas que proponemos sean útiles para cualquier persona interesada en SEO y visualización de datos.
Una cosa interesante de agregar es que la mayoría de las páginas en la web en realidad se crean con motores de búsqueda en mente, lo que significa que la mayoría de las veces vemos lo que esperamos encontrar. Por lo tanto, si le interesa darles a sus usuarios un poco de valor agregado y ayudarlos a salir de la burbuja de filtro de los motores de búsqueda, intente identificar los temas que serían novedosos para el discurso ya existente disponible en línea. Los gráficos de red de texto pueden ser muy útiles para eso y ofrecen una clara metáfora visual para la interacción digital.
PD
Después de dos días, este artículo ha estado en línea: