Cómo salir con alguien fuera de tu alcance
La minería de datos sugiere por qué las parejas tienden a coincidir en la deseabilidad y cómo mejorar sus probabilidades cuando persiguen a alguien más arriba en la escala.por Tecnología Emergente del arXiv
Una observación curiosa sobre las asociaciones humanas es que las parejas tienden a coincidir en términos de edad, educación, actitudes e incluso atractivo físico.
Los sociólogos y los biólogos evolutivos han discutido durante mucho tiempo acerca de cómo sucede esto, con las teorías que caen en dos campos. En un campo está la hipótesis de juego. Esta es la idea de que las personas de alguna manera saben cuán deseables son y eligen un compañero al mismo nivel.
En el otro campo está la hipótesis de la competencia. Esto supone que todos, independientemente de la deseabilidad, buscan el socio más deseable. El resultado es que las personas más deseables se emparejan, seguidas de las siguientes más deseables, y así sucesivamente.
Estas dos hipótesis producen resultados similares de tipos de comportamiento completamente diferentes. La única manera de separarlos es estudiar en detalle el comportamiento de apareamiento. Eso siempre ha sido demasiado difícil de hacer en la escala necesaria.
Hoy, eso cambia, gracias al trabajo de Elizabeth Bruch y Mark Newman en la Universidad de Michigan, que han extraído los datos de un popular sitio de citas en línea para romper el punto muerto. Su avance es una forma nueva y objetiva de medir la deseabilidad y clasificar a las personas en consecuencia.
El trabajo proporciona un nuevo prisma poderoso a través del cual se puede ver el comportamiento de de las citas exitosas. Los investigadores dicen que muestra que la competencia por parejas crea una jerarquía pronunciada en la deseabilidad y que tanto hombres como mujeres buscan consecuentemente parejas más deseables que ellas mismas. También apunta a una estrategia simple que podría mejorar las posibilidades de éxito para la mayoría de las personas.

Primero, el método objetivo de Bruch y Newman para medir la deseabilidad: dicen que las personas más populares son claramente las que reciben el mayor interés en los sitios de citas, según lo cuantificado por la cantidad de mensajes que reciben.
Según esta medida, la persona más popular en el estudio es una mujer de 30 años de Nueva York, que recibió 1,504 mensajes durante el mes en que Bruch y Newman realizaron su estudio. "[Eso es] equivalente a un mensaje cada 30 minutos, día y noche, durante todo el mes", dicen.
Pero la deseabilidad no se trata solo de la cantidad de mensajes recibidos, sino de quiénes son esos mensajes. "Si te contactan personas que son deseables, entonces presumiblemente eres más deseable", afirman los investigadores.
Si este tipo de enfoque le suena familiar, es porque se basa en el famoso algoritmo PageRank de Google. Esto se ha utilizado para clasificar todo, desde páginas web hasta ganadores del Premio Nobel.
En este escenario, el algoritmo PageRank proporciona un enfoque objetivo, basado en la red, para clasificar a hombres y mujeres por su deseabilidad. Y una vez hecho esto, resulta sencillo probar las hipótesis de concordancia y competencia al monitorear si las personas buscan parejas con un nivel similar de deseabilidad o no.
Los resultados hacen para la lectura interesante. "Encontramos que tanto los hombres como las mujeres buscan parejas que en promedio son aproximadamente un 25% más deseables que ellos mismos", dice Bruch y Newman. “Mensajería de parejas potenciales que son más deseables que uno mismo no es solo un acto ocasional de ilusiones; Es la norma ".
Este enfoque no está sin sus trampas. La probabilidad de recibir una respuesta disminuye dramáticamente a medida que aumenta la brecha de deseabilidad. Es fácil imaginar que las personas que contactan a parejas más deseables harían esto más a menudo para aumentar sus posibilidades de obtener una respuesta.
"De hecho, hacen lo contrario: la cantidad de contactos iniciales que un individuo realiza se reduce rápidamente a medida que aumenta la brecha y son las personas que se acercan a los socios menos deseados los que envían la mayor cantidad de mensajes", dicen Bruch y Newman.
Así que las personas obviamente adoptan diferentes estrategias para acercarse a parejas potenciales con alta y baja deseabilidad. De hecho, los investigadores dicen que las personas dedican más tiempo a elaborar mensajes más largos y personalizados para socios más deseables: un enfoque de calidad sobre la cantidad.
El equipo también estudió el contenido de estos mensajes utilizando el análisis de sentimientos. Curiosamente, encontraron que las mujeres tienden a usar más palabras positivas en los mensajes a los hombres deseables, mientras que los hombres usan menos palabras positivas.
Ese puede ser el resultado del aprendizaje por experiencia. "Los hombres experimentan tasas de respuesta ligeramente más bajas cuando escriben mensajes redactados de manera más positiva", dicen Bruch y Newman.
Si estas diferentes estrategias funcionan está lejos de ser claro. "La variación en la recompensa de las diferentes estrategias es bastante pequeña, lo que sugiere que, en igualdad de condiciones, el esfuerzo puesto por escribirlo más largo o más mensajes positivos puede desperdiciarse", dicen.
Es un trabajo interesante, pero tiene menos relevancia para las citas fuera de línea. Las citas en línea ofrecen un gran volumen de parejas potenciales con un umbral bajo para enviar un mensaje, que es bastante diferente del mundo sin conexión.
Sin embargo, los resultados proporcionan algunas ideas importantes. Con respecto a las hipótesis de coincidencia y competencia, la evidencia sugiere que las personas usan ambas. "Son conscientes de su propia posición en la jerarquía y ajustan su comportamiento en consecuencia, mientras que al mismo tiempo compiten modestamente por compañeros más deseables", dicen Bruch y Newman.
"Nuestros resultados son consistentes con el concepto popular de "ligas" de citas, como se refleja en la idea de que alguien puede estar "fuera de tu liga" o "fuera de tu alcance".
Los hallazgos también sugieren una estrategia obvia para atraer a un compañero que está "fuera de su liga". Bruch y Newman dicen que las posibilidades de recibir una respuesta de un socio altamente deseable son bajas, pero no son nulas.
Por lo tanto, la mejor estrategia debería ser enviar más mensajes a socios altamente deseables y estar preparados para esperar más tiempo para recibir una respuesta. "Mensajear a 2 o 3 veces más parejas potenciales para obtener una cita parece una inversión bastante modesta", dicen los investigadores.
Si alguien que busca un compañero tiene tiempo libre, inténtelo y díganos cómo le va.
Ref: arxiv.org/abs/1808.04840 : Aspirational Pursuit Of Mates In Online Dating Markets










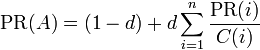
 es el PageRank de la página A.
es el PageRank de la página A.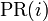 son los valores de PageRank que tienen cada una de las páginas i que enlazan a A.
son los valores de PageRank que tienen cada una de las páginas i que enlazan a A.