Centralidad
En teoría de grafos y análisis de redes la centralidad en un grafo se refiere a una medida posible de un vértice en dicho grafo, que determina su importancia relativa dentro de éste.1
Poder reconocer la centralidad de un nodo puede ayudar a determinar, por ejemplo, el impacto de una persona involucrada en una red social, la relevancia de una habitación en un edificio representado en sintaxis del espacio, la importancia de una carretera en una red urbana, o los componentes esenciales de una red de computadoras.
El concepto fue introducido inicialmente por Bavelas a fines de los años 1940.2 Es uno de los conceptos más estudiados en el análisis de redes y desde finales de los años 70 en el análisis de redes sociales,3 4 y muchos de los conceptos relacionados con las medidas de centralidad reflejan su origen sociológico.5
La centralidad no es un atributo intrínseco de los nodos o actores de una red, como podrían serlo la autoestima, la temperatura, el ingreso monetario, etc. sino un atributo estructural, es decir, un valor asignado que depende estrictamente de su localización en la red. La centralidad mide según un cierto criterio la contribución de un nodo según su ubicación en la red, independientemente de si se esté evaluando su importancia, influencia, relevancia o prominencia.
Por ejemplo, de acuerdo con una medida de centralidad razonable, en un grafo estrella el nodo central debería ocupar un valor máximo de centralidad, mientras que los nodos de las puntas ocuparían un valor de centralidad inferior.

A) centralidad de grado
B) cercanía
C) intermediación
D) centralidad de vector propio
E) centralidad de Katz
F) centralidad alfa.
Las tonalidades van del rojo (más centrales) al azul (más periféricos).
Medidas de centralidad
Las medidas de centralidad se pueden agrupar en dos categorías: medidas radiales («radial measures») y mediales («medial measures»).6 Las primeras toman como punto de referencia un nodo dado que inicia o termina recorridos por la red, mientras que las segundas toman como referencia los recorridos que pasan a través de un nodo dado.7 Las medidas radiales a su vez se pueden clasificar en medidas de volumen y de longitud, según el tipo de recorridos que consideran. Las primeras miden el volumen (o el número) de recorridos limitados a dicha longitud prefijada, en tanto que las segundas miden la longitud de los recorridos necesarios para alcanzar un volumen prefijado.7
Desde la formulación realizada por Bavelas,2 se han propuesto diversas medidas de centralidad de un nodo. Existen cuatro de estas medidas que son ampliamente usadas en análisis de redes:
- La centralidad de grado («degree centrality»)
- La cercanía («closeness»)
- La intermediación («betweenness»)
- La centralidad de vector propio («eigenvector centrality»).
La primera y la última son medidas radiales de volumen. La segunda es una medida radial de longitud, y la tercera una medida medial.7 Para algunas de estas medidas existen a su vez versiones más generales o bien generalizaciones para las redes con pesos.8
Adicionalmente, se puede distinguir entre las medidas «absolutas» de centralidad, que indican un valor no comparable y aquellas que están normalizadas, denominadas medidas «relativas» de centralidad.
Centralidad de grado
La centralidad de grado («degree centrality») es la primera y más simple de las medidas de centralidad.7 Corresponde al número de enlaces que posee un nodo con los demás.
Formalmente, dado un grafo  , donde
, donde 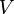 es su conjunto de vértices y
es su conjunto de vértices y 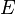 su conjunto de aristas, entonces para cada nodo
su conjunto de aristas, entonces para cada nodo  su centralidad de grado
su centralidad de grado 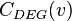 se define como:7
se define como:7
, donde es su conjunto de vértices y su conjunto de aristas, entonces para cada nodo su centralidad de grado se define como:7
Si se tiene la matriz de adyacencia del grafo, donde cada posición 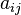 asume el valor 1, si existe la arista
asume el valor 1, si existe la arista 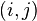 y el valor 0, si no existe, entonces la centralidad de grado de cada nodo
y el valor 0, si no existe, entonces la centralidad de grado de cada nodo  se puede definir como:
se puede definir como:
asume el valor 1, si existe la arista y el valor 0, si no existe, entonces la centralidad de grado de cada nodo se puede definir como: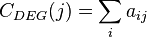
Para grafos dirigidos, se pueden definir dos medidas de centralidad de grado diferentes, correspondientes al grado de entrada o el de salida. En el sentido de relaciones interpersonales, el primero puede interpretarse como una medida de popularidad, mientras que el segundo como una de sociabilidad.
Dos criterios para normalizar esta medida pueden ser dividir el grado de cada nodo por el máximo grado obtenido de la red, o bien dividirlo por el número total de nodos de la red.
Las interpretaciones de esta medida pueden ser múltiples. En una red social, puede ser el número de amistades o conexiones que posee cada persona, en cuyo caso cuantifica la conectividad o popularidad en la red. En una red de infección puede medir el grado de riesgo de ser contagiado o el índice de exposición. En la propagación de un rumor, puede medir la probabilidad de obtener la información a través de un rumor.
En complejidad computacional, el cálculo de esta medida toma  en una matriz de adyacencia densa, y
en una matriz de adyacencia densa, y  en una matriz dispersa.
en una matriz dispersa.
en una matriz de adyacencia densa, y en una matriz dispersa.Centralidad de camino-K
El grado de un nodo puede verse como el número de caminos de longitud 1 que lo conectan con otros nodos. Una generalización natural a la centralidad de grado, es la centralidad de camino-K («K-path centrality») que para cada nodo mide el número de caminos de largo a lo más  que lo conectan otros nodos.7
que lo conectan otros nodos.7
que lo conectan otros nodos.7Centralidades de Katz y Bonacich
Otra generalización de la centralidad de grado es la centralidad de Katz,9 que para un nodo cuenta el número de todos los otros nodos que están conectados con él a través de un camino, al mismo tiempo que se penalizan las conexiones con nodos más distantes por medio de un factor  .
.
.
Formalmente, sea  la matriz de adyacencia del grafo, y
la matriz de adyacencia del grafo, y  el número total de nodos, la centralidad de Katz
el número total de nodos, la centralidad de Katz 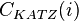 de un nodo
de un nodo  se define como:7
se define como:7
la matriz de adyacencia del grafo, y el número total de nodos, la centralidad de Katz de un nodo se define como:7
donde  es un vector fila cuyo -ésimo elemento es 1 y el resto son 0, y 1 es un vector de puros unos. Como se verá más adelante, esta medida está relacionada con la centralidad de vector propio.7
es un vector fila cuyo -ésimo elemento es 1 y el resto son 0, y 1 es un vector de puros unos. Como se verá más adelante, esta medida está relacionada con la centralidad de vector propio.7
es un vector fila cuyo -ésimo elemento es 1 y el resto son 0, y 1 es un vector de puros unos. Como se verá más adelante, esta medida está relacionada con la centralidad de vector propio.7
Una pequeña variación de la centralidad de Katz está dada por la centralidad de Bonacich,10 la cual permite valores negativos para el factor  :
:
:
De este modo el peso negativo permite restar los caminos de número par de los de número impar, lo cual es interpretable en redes de intercambio.7 6
Centralidad de Hubbell
Una generalización que incluye a las centralidades de Katz y Bonacich es la centralidad de Hubbell,11 definida formalmente como:
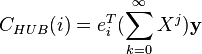
donde  es una matriz e
es una matriz e 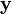 un vector. Si
un vector. Si 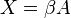 y
y 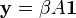 se obtiene la centralidad de Katz, y si y
se obtiene la centralidad de Katz, y si y  , se obtiene la centralidad de Bonacich.7
, se obtiene la centralidad de Bonacich.7
es una matriz e un vector. Si y se obtiene la centralidad de Katz, y si y , se obtiene la centralidad de Bonacich.7Cercanía
La medida de cercanía, definida por el matemático Murray Beauchamp en 196512 y luego popularizada por Freeman en 1979,3 es la más conocida y utilizada de las medidas radiales de longitud. Se basa en calcular la suma o bien el promedio de las distancias más cortas desde un nodo hacia todos los demás.7
Formalmente, la cercanía 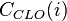 de un nodo se define como:
de un nodo se define como:
de un nodo se define como: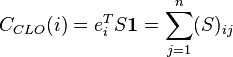
donde  es la matriz de distancias de la red, es decir, aquella matriz cuyos elementos corresponden a la distancia más corta desde el nodo hasta el nodo . Mientras menor sea el valor anterior, se puede decir que el nodo está más «cercano» al centro de la red. En tal caso definido así corresponde en realidad a una medida de lejanía. Por la misma razón, a veces la cercanía se define más bien como el valor recíproco de lo anterior, no cambiando por ello la idea del concepto.13
es la matriz de distancias de la red, es decir, aquella matriz cuyos elementos corresponden a la distancia más corta desde el nodo hasta el nodo . Mientras menor sea el valor anterior, se puede decir que el nodo está más «cercano» al centro de la red. En tal caso definido así corresponde en realidad a una medida de lejanía. Por la misma razón, a veces la cercanía se define más bien como el valor recíproco de lo anterior, no cambiando por ello la idea del concepto.13
es la matriz de distancias de la red, es decir, aquella matriz cuyos elementos corresponden a la distancia más corta desde el nodo hasta el nodo . Mientras menor sea el valor anterior, se puede decir que el nodo está más «cercano» al centro de la red. En tal caso definido así corresponde en realidad a una medida de lejanía. Por la misma razón, a veces la cercanía se define más bien como el valor recíproco de lo anterior, no cambiando por ello la idea del concepto.13
En una red de flujo esta medida se puede interpretar como el tiempo de llegada a destino de algo que fluye a través de la red.1 También puede interpretarse como la rapidez que tomará la propagación de la información desde un nodo a todos los demás.14 La cercanía mide de alguna forma la accesibilidad de un nodo en la red. Este concepto es utilizado también de manera similar en topología (donde se define como un espacio métrico) y en teoría de grafos, donde se aplica entre otros campos al análisis de redes.
Variantes de cercanía
La medida tradicional de cercanía asume que la propagación de información siempre se da en la red a través del camino más corto. Este modelo puede no ser el más realista para algunos tipos de escenarios de comunicación. Por ello han surgido algunas variantes de esta medida.
Una de ellas es la denominada cercanía por camino aleatorio («random-walk closeness centrality») introducida por Noh y Rieger en 2003 y que considera recorridos aleatorios para acceder de un nodo a los demás, en lugar de escoger siempre el camino más corto.15
Varios años antes, en 1989, Stephenson y Zelen definieron una variante de medida de centralidad enfocada en el traspaso de información («information centrality») en una red. Esta medida determina la longitud media armónica de los caminos que acaban en un nodo , la que será pequeña si se conecta con muchos otros nodos a través de caminos cortos.16
, la que será pequeña si se conecta con muchos otros nodos a través de caminos cortos.16
En 2006, Dangalchev modifica la definición de cercanía para medir la vulnerabilidad en las redes, permitiendo analizar grafos desconectados (en la definición original, los nodos aislados del grafo tendrían una cercanía igual a cero):17
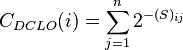
En 2010 Opsahl propuso otra extensión de la medida para redes con componentes desconectadas.18
Intermediación
La intermediación («betweenness centrality») es una medida que cuantifica la frecuencia o el número de veces que un nodo actúa como un puente a lo largo del camino más corto entre otros dos nodos.7
La medida fue introducida por Linton Freeman en 1977, como forma de cuantificar el control de un humano en la comunicación existente con otros humanos en una red social. La idea intuitiva es que si se eligen dos nodos al azar, y luego también al azar uno de los eventuales posibles caminos más cortos entre ellos, entonces los nodos con mayor intermediación serán aquellos que aparezcan con mayor probabilidad dentro de este camino.19

Las tonalidades que van desde el rojo (valor 0) hasta el azul (valor máximo) indican la intermediación de los nodos en el grafo
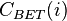 de un nodo
de un nodo 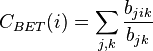
donde  es el número de caminos más cortos desde el nodo hasta el nodo , y
es el número de caminos más cortos desde el nodo hasta el nodo , y  el número de caminos más cortos desde hasta que pasan a través del nodo .
el número de caminos más cortos desde hasta que pasan a través del nodo .
es el número de caminos más cortos desde el nodo hasta el nodo , y el número de caminos más cortos desde hasta que pasan a través del nodo .
En complejidad computacional, determinar el camino más corto para cada par de nodos de un grafo  puede calcularse en tiempo
puede calcularse en tiempo 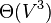 (por ejemplo usando el algoritmo de Floyd-Warshall) y utilizando un espacio .7 En un grafo disperso, el algoritmo de Johnson puede lograr lo mismo en tiempo
(por ejemplo usando el algoritmo de Floyd-Warshall) y utilizando un espacio .7 En un grafo disperso, el algoritmo de Johnson puede lograr lo mismo en tiempo 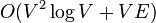 , y si el grafo es sin pesos, se puede lograr en tiempo
, y si el grafo es sin pesos, se puede lograr en tiempo 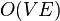 y espacio
y espacio  utilizando el algoritmo de Brandes.20
utilizando el algoritmo de Brandes.20
puede calcularse en tiempo (por ejemplo usando el algoritmo de Floyd-Warshall) y utilizando un espacio .7 En un grafo disperso, el algoritmo de Johnson puede lograr lo mismo en tiempo , y si el grafo es sin pesos, se puede lograr en tiempo y espacio utilizando el algoritmo de Brandes.20
Los nodos con una alta intermediación, al igual que las aristas con una alta intermediación en los lazos interpersonales (tema que no tiene que ver directamente con centralidad y que no abordaremos aquí), suelen jugar un rol crítico en la estructura de la red, cuando hay grandes flujos de información que son transportados por nodos pertenecientes a grupos compactos. En una red social están relacionados con los agujeros estructurales («structural holes»), es decir, con aquellos nodos de los que depende la integración de algunas componentes de la red.7 Los nodos que poseen una posición de intermediarios de alguna manera son también controladores o reguladores del flujo de información. Así, en un proceso de difusión, si el valor de intermediación de un nodo es alto entonces puede actuar como un broker; y si es suficientemente alto como para controlar el flujo de información, entonces puede actuar como un guardián.
Intermediación de Newman
Newman propuso en 200514 una versión alternativa de la medida de intermediación, basada en considerar caminos aleatorios del grafo, y no exclusivamente los más cortos. La idea es tomar en cuenta todos los caminos posibles, y calcular la medida de acuerdo a los elegidos aleatoriamente. Formalmente se define como:7
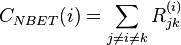
donde  es la matriz cuyos elementos
es la matriz cuyos elementos 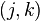 contienen la probabilidad de ocurrencia de un camino al azar desde hasta y que contiene al nodo como nodo intermediario.
contienen la probabilidad de ocurrencia de un camino al azar desde hasta y que contiene al nodo como nodo intermediario.
es la matriz cuyos elementos contienen la probabilidad de ocurrencia de un camino al azar desde hasta y que contiene al nodo como nodo intermediario.Centralidad de vector propio
La centralidad de vector propio mide la influencia de un nodo en una red. Fue propuesta por Phillip Bonacich en 1972,21 y corresponde al principal vector propio de la matriz de adyacencia del grafo analizado.7
Intuitivamente, los nodos que poseen un valor alto de esta medida de centralidad están conectados a muchos nodos que a su vez están bien conectados, también en este sentido; por lo tanto, son buenos candidatos para difundir información, divulgar rumores o enfermedades, etc. Los nodos más centrales en este sentido corresponden a centros de grandes grupos cohesivos. Mientras que en el caso de la centralidad de grado, cada nodo pesa lo mismo dentro de la red, en este caso la conexión de los nodos pesa de forma diferente.
El cálculo del PageRank de Google, utilizado para medir la relevancia de páginas web en Internet, es una variante de esta medida.22 Otra medida muy relacionada con esta es la centralidad de Katz, debido a que la centralidad de vector propio es ellímite de la centralidad de Katz cuando el factor se aproxima a  por debajo,7 6 donde
por debajo,7 6 donde  es el valor propio obtenido de la ecuación
es el valor propio obtenido de la ecuación  .
.
se aproxima a por debajo,7 6 donde es el valor propio obtenido de la ecuación .
En general habrán varios valores propios para los cuales existe una solución de vector propio. Sin embargo, el requerimiento adicional de que las entradas de los vectores propios sean positivos implica (por el Teorema de Perron-Frobenius) que sólo los mayores valores propios conduzcan a la medida de centralidad deseada.23 El método de las potencias es uno de los muchos algoritmos existentes para calcular el valor propio que puede ser utilizado para encontrar el vector propio dominante.22Además, este puede generalizarse tal que las entradas en la matriz de adyacencia puedan ser números reales representrando fuerzas de conexión, como en una matriz estocástica.
puedan ser números reales representrando fuerzas de conexión, como en una matriz estocástica.Centralidad alfa
La centralidad alfa es una variante de la centralidad de vector propio en que los nodos están sujetos a distinta importancia dependiendo de factores externos. Esta medida fue definida por Bonacich y Lloyd en 2001.24
Esta medida está implementada en la biblioteca de un software de análisis de redes sociales denominado «igraph», y se utiliza para especificar la importancia relativa de factores endógenos vs. exógenos en una determinación de centralidad al momento de analizar o visualizar una red.25
Referencias
- ↑ a b Borgatti, Stephen P. (2005). «Centrality and network flow». Social Networks 27: pp. 55-71.doi:.
- ↑ a b Bavelas, A. (1948). «A mathematical model for group structures». Human Organization 7: pp. 16-30.
- ↑ a b Freeman, L.C. (1979). «Centrality in networks: I. Conceptual clarification». Social Networks 1: pp. 215-239.doi:.
- ↑ Freeman, L.C.; Borgatti, S.P.; White, D.R. (1991). «Centrality in valued graphs: a measure of betweenness based on network flow». Social Networks 13: pp. 141-154. doi:.
- ↑ Newman, M.E.J. (2010). Networks: An Introduction. Oxford, Reino Unido: Oxford University Press.
- ↑ a b c Borgatti, S.P.; Everett, M.G. (2006). «A graph-theoretic perspective on centrality». Social networks 28 (4): pp. 466-484.doi:.
- ↑ a b c d e f g h i j k l m n ñ o p q Jimeng, Sun; Jie, Tang (2011). Charu C. Aggarwal. ed. «A survey of models and algorithms for social influence analysis». Social network data analytics (Nueva York: Springer): pp. 177-214. doi:. ISBN 978-4419-8461-6.
- ↑ Opsahl, T.; Agneessens, F.; Skvoretz, J. (2010). «Node centrality in weighted networks: Generalizing degree and shortest paths». Social Networks 32 (3): pp. 245. doi:.
- ↑ Katz, L. (1953). «A new status index derived from sociometric index». Psychometrika 18 (1): pp. 39-43.
- ↑ Bonacich, P. (1987). «Power and centrality: a family of measures». American Journal of Sociology 92 (5): pp. 1170-1182.
- ↑ Hubbell, C. (1965). «An input-output approach to clique identification». Sociometry 28 (4): pp. 377-399.
- ↑ Beauchamp, M. A. (1965). «An improved index of centrality». Systems Research and Behavioral Science 10 (2): pp. 161-163. doi:.
- ↑ Sabidussi, G. (1966). «The centrality index of a graph». Psychometrika 31 (4): pp. 581-603.
- ↑ a b Newman, M.E.J. (2005). «A measure of betweenness centrality based on random walks». Social Networks 27: pp. 39-54. doi:.
- ↑ Noh, J. D.; Rieger, H. (2004). «Random walks on complex networks». Phys. Rev. Lett. 92 (11).doi:.
- ↑ Stephenson, K. A.; Zelen, M. (1989). «Rethinking centrality: Methods and examples». Social Networks 11 (1): pp. 1-37.doi:.
- ↑ Dangalchev, Ch. (2006). «Residual closeness in networks». Physica A 365 (2): pp. 556-564.
- ↑ Tore Opsahl (20 de marzo de 2010). «Closeness centrality in networks with disconnected components». Consultado el 4 de enero de 2012.
- ↑ Freeman, L. (1977). «A set of measures of centrality based upon betweenness». Sociometry 40 (1): pp. 35-41.
- ↑ Brandes, U. (2001). «A faster algorithm for betweenness centrality». Journal of Mathematical Sociology 25: pp. 163-177.doi:.
- ↑ Bonacich, P. (1972). «Factoring and weighting approaches to clique identification». Journal of Mathematical Sociology 2(1): pp. 113-120.
- ↑ a b David Austin. «How Google Finds Your Needle in the Web's Haystack» (en inglés). Consultado el 2 de enero de 2013.
- ↑ Newman, M.E.J. (PDF). The mathematics of networks. Consultado el 2 de enero de 2012.
- ↑ Bonacich, Phillip; Lloyd, Paulette (2001). «Eigenvector-like measures of centrality for asymmetric relations». Social Networks 23 (3): pp. 191-201. doi:.
- ↑ Package igraph version 0.6. «Find Bonacich alpha centrality scores of network positions». Consultado el 4 de enero de 2013.