Tutoriales avanzados
Estos tutoriales ilustran el uso avanzado de Visone.
- La administración avanzada de atributos le presenta todo el poder del administrador de atributos de Visone y le muestra cómo seleccionar elementos que dependen de los valores de los atributos. El
administrador de atributos le permite, por ejemplo, convertir la fuerza
de los lazos en distancia o clasificaciones y viceversa, dicotomizar
redes, cambiar la escala de los pesos de los lazos y mucho más.
- Colecciones de redes y redes dinámicas . Una colección de redes
es un conjunto o secuencia de varias redes que pertenecen juntas, por
ejemplo, mediante la construcción de una red longitudinal. Este
tutorial lo guía a través de varios ejemplos de aplicaciones para
colecciones de redes, incluida la visualización dinámica y el modelado
estadístico de la dinámica de redes con el software RSiena .
- Redes de eventos. Los enlaces en una red de eventos
están formados por eventos de interacción con marca de tiempo, como
usuarios que envían correos electrónicos a otros usuarios, usuarios que
editan documentos en un entorno Web 2.0, etc. Este tutorial ilustra el
análisis y la visualización de redes de eventos con visone.
------------------------------------------------------------------------------------------
Gestión de atributos (tutorial)
Saltar a navegación Saltar a buscar
Este tutorial le presenta todo el poder del administrador de atributos de Visone y le muestra cómo seleccionar elementos que dependen de los valores de los atributos. El
administrador de atributos le permite, por ejemplo, convertir la fuerza
de los lazos en distancia o clasificaciones y viceversa, dicotomizar
redes, cambiar la escala de los pesos de los lazos y mucho más.
Este
tutorial asume que tiene una comprensión básica de cómo analizar y
visualizar redes en visone, como se ilustra, por ejemplo, en el tutorial anterior .
Un conjunto de datos ejemplar: Newcomb Fraternity Data
The Newcomb Fraternity Data (ver Newcomb T. (1961). The acquaintance process. New York: Holt, Reinhard & Winston.
) consta de 15 matrices que registran clasificaciones de preferencias
sociométricas semanales de 17 hombres que asistieron a la Universidad de
Michigan en el otoño de 1956. Cada participante clasifica a los otros
16 desde el mejor amigo hasta el menos amigo. Este conjunto de datos se explica con más detalle en la página Newcomb Fraternity (datos) .
Para seguir los pasos ilustrados en este tutorial, debe descargar el archivo Newfrat.zip (archivo ZIP que contiene las 15 matrices newfrat01.csv a newfrat15.csv ), guardarlo en su computadora y descomprimirlo .
Importar los archivos CSV
Comenzamos importando una de las matrices de adyacencia (por ejemplo, newfrat01.csv ) a visone. Por lo tanto, use el menú archivo, abra y seleccione archivos de tipo archivos CSV (.txt, .csv) . La siguiente imagen muestra el cuadro de diálogo de opciones de importación que se abre a continuación. Podemos elegir entre diferentes formatos de datos en el menú desplegable superior. Como queremos importar una matriz de adyacencia, debemos seleccionar la matriz de adyacencia como formato de datos.

Configurar las otras opciones como se muestra arriba y hacer clic en Aceptar abre la red que se parece a la que se muestra a la derecha.
Se
puede ver que la red está completa (es decir, cada par de actores está
conectado por un lazo bidireccional. Todos los enlaces tienen un
atributo llamado valor csv cuyo valor corresponde a la entrada respectiva en la matriz de adyacencia y, por lo tanto, es igual a la rango del nodo de destino en la lista ordenada de amigos del nodo de origen.
En el tutorial de entrada de datos se proporciona un tratamiento más exhaustivo de cómo importar datos a Visone .
¿Quién es el más popular?
Por ejemplo, queremos explorar la popularidad de los actores con respecto a las nominaciones agregadas de todos los demás. Claramente, el número de enlaces entrantes no sería una buena medida para esto, ya que cada nodo recibe exactamente 16 enlaces. La información sobre qué tan populares son los actores se encuentra en la clasificación de los lazos. En
el caso extremo, sería posible que un actor (el más popular) reciba 16
enlaces con un rango igual a 1 y otro actor reciba 16 enlaces
etiquetados como 16 (es decir, este actor sería el menos amigo de todos
los demás).
Hay
varias posibilidades para convertir las nominaciones ponderadas en una
medida unidimensional de popularidad: dicotomizar la red definiendo un
umbral que separe entre los "amigos" y los "no amigos"; calcular un grado de entrada ponderado que tenga en cuenta los pesos de enlace; o combinaciones de los dos. Algunas de estas posibilidades se ilustran a continuación.
Selección y eliminación de enlaces por debajo de un umbral
Es conveniente renombrar el atributo que codifica los rangos, ya que csv value no es un nombre muy intuitivo. Para hacer esto, abra el administrador de atributos , haga clic en el enlace del botón en la fila superior y configure a la izquierda. Haga clic en el campo de texto donde actualmente dice valor csv y escriba, por ejemplo, clasificación en él; haga clic en el botón aplicar .
A modo de ejemplo, queremos mantener solo los enlaces que van a los 3 mejores amigos . Para
seleccionar todos los enlaces con un rango superior a 3 (es decir,
todos los enlaces que queremos eliminar) haga clic en el botón de filtro en el lado izquierdo (todavía teniendo el enlace seleccionado en la fila superior). En la fila donde puede definir el filtro, seleccione atributo , luego clasifique , marque ( solo ) la casilla antes del signo mayor que ( > ), escriba 3 en el campo de texto. Seleccione el botón de radio reemplazar en la parte inferior y haga clic en seleccionar

Esto
debería seleccionar 221 de 272 enlaces (esta información se puede
encontrar en la esquina inferior izquierda de la ventana de Visone) que
ahora se pueden eliminar haciendo clic en los enlaces del menú , eliminar enlaces o desde el menú contextual del enlace . Al hacer clic en el botón de diseño rápido, debería mostrarse una red como la de la derecha. Si la identificación del atributo se visualiza como etiqueta de nodo (a través de la asignación de su valor ), se puede ver en esta imagen que los nodos 16 y 10 parecen ser bastante populares.
Diseños de estado
Para establecer esto de manera más cuantitativa, calculamos el grado de entrada de los nodos a través de la pestaña de análisis (ignorando los pesos de enlace al seleccionar fuerza de vínculo = uniforme ) y lo guardamos en un grado de entrada de atributo (sin ponderar) . Este
atributo de nodo codifica, por tanto, el número de veces que el nodo ha
sido nominado como mejor amigo, 2º mejor amigo o 3º mejor amigo.

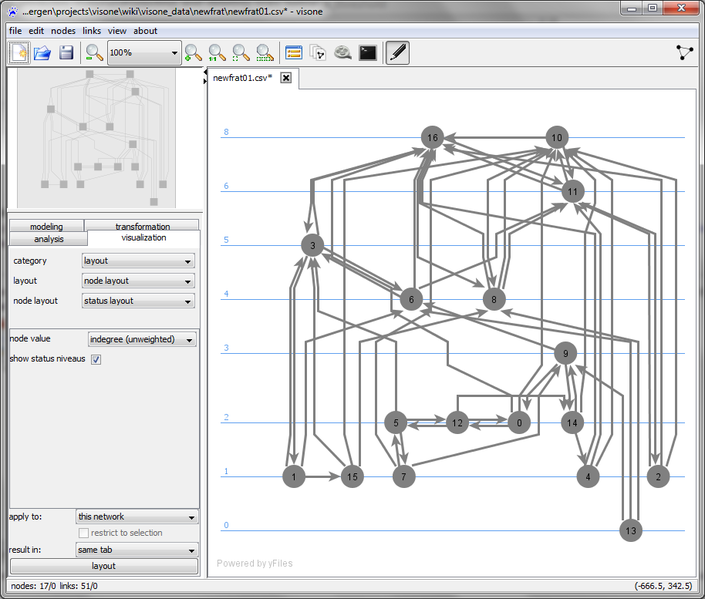
Para visualizar los valores relativos, usamos un diseño de estado que se puede calcular a través de la pestaña de visualización (establezca el valor del nodo en el atributo de nodo recién calculado en grados (sin ponderar) como se muestra en la captura de pantalla anterior).
Transformando atributos
El
grado de entrada no ponderado calculado anteriormente cuenta el número
de veces que el nodo ha sido nominado como primer, segundo o tercer
mejor amigo. Para contar
las nominaciones como mejor amigo más que las nominaciones como segundo
mejor amigo, podemos asignar estas clasificaciones a valores y luego
calcular los grados ponderados . Los
valores de rango no pueden tomarse directamente como medidas de la
fuerza del lazo ya que un rango más alto (p. ej., 3) indica una
intensidad de amistad más baja que un rango más bajo (p. ej., 1). Por lo tanto, tenemos que aplicar un mapeo de inversión de orden en el atributo de rango. Esto se puede hacer a través del administrador de atributos.. Tenga
en cuenta que la elección particular para la transformación a
continuación se ha realizado arbitrariamente y simplemente sirve para
ilustrar cómo se pueden transformar los atributos; cuando
se debe responder a una pregunta de investigación en particular, se
debe poder justificar tal elección, o mostrar que la elección particular
de transformación no influye significativamente en los hallazgos.

En el administrador de atributos, seleccione el botón de enlace en la parte superior y manipule a la izquierda. Seleccionar, de arriba a abajo, manipular valores , revertir y clasificar , otorgar un nuevo nombre al atributo transformado (como clasificación invertida ) y hacer clic en el botón Aplicar agrega el nuevo atributo a todos los nodos. Inversa significa que el intervalo de valores se revierte según lo especificado por la fórmula
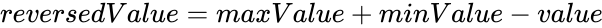 .
.
En
nuestro ejemplo, 1 se asigna a 3, 2 a 2 y 3 a 1. Puede inspeccionar las
otras posibilidades para transformar valores de atributos; tenga
en cuenta que las transformaciones que no se implementan directamente
en el administrador de atributos se pueden realizar a través de la consola R de visone (consulte el tutorial de la consola R para obtener una ilustración).
Centralidad y estado en redes ponderadas
Un grado de entrada ponderado, que depende del atributo recién calculado, se puede calcular a través de la pestaña de análisis (similar al grado de entrada no ponderado, pero configurando la fuerza del enlace para clasificar invertido ). El mapeo de este grado de entrada ponderado en un diseño de estado
revela que el actor 16 es más popular que el 10 con respecto a la
medida ponderada, pero igualmente popular con respecto al grado de
entrada no ponderado.
-------------------------------------------------------------------------------------
Colecciones (tutorial)
Una colección de redes
es un conjunto o secuencia de varias redes que pertenecen juntas, por
ejemplo, al representar ondas en una red longitudinal (es decir, una red
observada en varios momentos en el tiempo). Las
colecciones de redes se pueden analizar y visualizar de forma conjunta
(por ejemplo, calculando el mismo índice de centralidad o aplicando el
mismo algoritmo de diseño en todas las redes abiertas). Una colección de red Visone que representa datos longitudinales se puede visualizar mediante un algoritmo de diseño dinámico que muestra la evolución de la red a lo largo del tiempo y se puede analizar con el software RSiena para modelar la coevolución de las redes y el comportamiento. este tutoriallo guía a través de estos escenarios de aplicación de una manera basada en ejemplos. Para seguir los pasos que se ilustran aquí, descargue el archivo Newfrat_top3.zip, enlazado y descrito en la página Newcomb Fraternity (datos) , y extraiga (descomprima) su contenido (compuesto por los archivos newfrat01.graphmla newfrat15.graphml) en su disco duro. Este tutorial asume que tiene conocimientos básicos sobre cómo trabajar con Visone, tal como se ilustra en los tutoriales básicos .
Manejo de varias redes (conceptos básicos)
En visone, se pueden abrir varias redes al mismo tiempo, cada una en su propia pestaña de red. En general, puede cargar redes en Visone (1) iniciando y editando una nueva red vacía , (2) abriendo una red desde un archivo local o (3) creando una red aleatoria . Para cargar el conjunto de redes que sirve como ejemplo ilustrativo en este tutorial, haga clic en el archivo de menú, abra , navegue en el explorador de archivos hasta el directorio donde colocó los archivos newfrat01.graphml( newfrat15.graphmlver arriba) y selecciónelos todos antes que usted. haga clic en el botón Aceptar . (La selección de estos archivos se puede hacer de diferentes maneras, por ejemplo, manteniendo el Control-tecla
presionada mientras selecciona sucesivamente los archivos con un clic
izquierdo del mouse o haciendo clic en uno de los archivos y luego
escribiendo Control-a para seleccionar todos los archivos en el directorio actual).

Las 15 redes deben mostrarse en 15 pestañas separadas en el área de red . Para
cambiar entre estas redes, haga clic en el nombre de la red respectiva
en la parte superior de las pestañas (hay pequeños botones con flechas
izquierda/derecha en el lado derecho en la fila de nombres de red que le
permiten navegar a través de las pestañas cuando la lista de nombres
excede el ancho de la pantalla). Para cerrar una pestaña, haga clic en la cruz en forma de X en el lado derecho de la pestaña respectiva. Para
cerrar todas las pestañas o todas las pestañas excepto la actual, haga
clic con el botón derecho del mouse en uno de los nombres de red y
seleccione la opción adecuada; si hay cambios sin guardar, visone le pregunta si desea guardar los archivos y puede responder sí/nopor separado para cada red o eligió salir sin guardar ningún cambio (haga clic en no a todo ), para guardar todas las redes modificadas ( sí a todo ) o eligió cancelar , es decir, no cerrar las pestañas. (Si cerró una o varias de las redes, recuerde abrirlas nuevamente para seguir los pasos a continuación).
Análisis y visualización simultáneos
Los algoritmos de análisis y visualización de redes se pueden aplicar a todas las redes abiertas simultáneamente. Por ejemplo, para calcular el grado de entrada de los nodos en las 15 redes que están actualmente abiertas en Visone, vaya a la pestaña de análisis , elija las opciones apropiadas para calcular el grado de entrada (para obtener información al respecto, consulte el tutorial sobre visualización y análisis ) y seleccione redes abiertas . en el menú desplegable Aplicar a en la parte inferior de la pestaña de análisis antes de presionar el botón analizar . Cada una de las redes tiene ahora un atributo llamado, por ejemplo , grado (o el nombre que haya elegido) cuyos valores son iguales a los grados de los nodos en los puntos de tiempo respectivos.
Tenga en cuenta que puede elegir si la operación debe realizarse directamente en la red (elija la misma pestaña antes de hacer clic en analizar ) o si primero se crea una copia de cada red en una nueva pestaña y la operación se realiza solo en estas copias (elija nuevo pestaña ). Elegiría la segunda opción si no desea mantener la versión actual de la red. En el ejemplo en ejecución, seleccionar la misma pestaña es apropiado.
Aplicar un algoritmo de visualización simultáneamente a todas las redes abiertas funciona en consecuencia. Por ejemplo, asigne el grado recién calculado al tamaño del nodo (puede encontrar más información sobre cómo asignar atributos a gráficos en el tutorial sobre visualización y análisis ).
Creación de una colección de red
Los algoritmos de análisis y visualización ilustrados anteriormente procesaron las redes por separado, una a la vez. Hasta el momento, un nodo de una red no ha sido identificado con ningún nodo de otra red. Para ello hay que decirle a visone qué atributo es el que identifica los nodos creando una colección de red con el gestor de colecciones . Debe crear una colección de red antes de calcular un diseño dinámico o antes de modelar y analizar la evolución de la red con la interfaz RSiena (estas dos tareas de aplicación se ilustran a continuación en este tutorial).
Para crear una colección de red, abra el administrador de colecciones haciendo clic en el  icono en la barra de herramientas de Visone . En el administrador de la colección, presione el botón Crear colección , seleccione las redes que se ofrecen en el área denominada Redes disponibles y agréguelas a la colección actual presionando el botón
icono en la barra de herramientas de Visone . En el administrador de la colección, presione el botón Crear colección , seleccione las redes que se ofrecen en el área denominada Redes disponibles y agréguelas a la colección actual presionando el botón  Agregar . El orden en que aparecen las redes en el área etiquetada como redes en la colecciónimporta
ya que define el orden de las redes a lo largo del tiempo: la red en la
primera línea corresponde al primer punto de tiempo de observación, la
de la segunda línea se ha recopilado a continuación, y así
sucesivamente. En nuestro
ejemplo particular, los números enteros del 01 al 15 en los nombres de
las redes sugieren este orden: las redes con números más altos se
recopilaron más tarde. (Solo como ejemplo, si la red
Agregar . El orden en que aparecen las redes en el área etiquetada como redes en la colecciónimporta
ya que define el orden de las redes a lo largo del tiempo: la red en la
primera línea corresponde al primer punto de tiempo de observación, la
de la segunda línea se ha recopilado a continuación, y así
sucesivamente. En nuestro
ejemplo particular, los números enteros del 01 al 15 en los nombres de
las redes sugieren este orden: las redes con números más altos se
recopilaron más tarde. (Solo como ejemplo, si la red newfrat12.graphmlfuera
la que se recolectó en el último momento de observación, puede moverla
al final de la lista eliminándola y agregándola nuevamente. Se
necesitarán algunos pasos más para corregir esto y ponerla volver a la
posición 12.) La opción importante que debe configurar es el atributo de identificación,
siendo el nombre del atributo que identifica los nodos en diferentes
puntos de tiempo (para obtener más información sobre la identificación
de atributos, consulte la página de recopilación de redes ). Tenga en cuenta que en el ejemplo actual solo se le ofrece elegir id como atributo de identificación (el atributo engrado
no es una opción para el atributo de identificación ya que sus valores
no son únicos, es decir, varios nodos tienen los mismos grados). Si
bien puede crear una colección de red incluso si algunos nodos no están
presentes en todo momento, una colección de red se marca como compatible con siena si todos los nodos están presentes en todo momento. Si una colección de red no es compatible con Siena, no se puede modelar con RSienapero, no obstante, puede calcular un diseño dinámico. Se puede crear más de una colección y cambiar entre ellas en el administrador de colecciones.
Visualización dinámica y animación de una colección de red.
Siempre
que haya una colección de red activa, puede crear una animación que
muestre una película que lo lleve desde la primera red hasta la última
(el orden se define en el administrador de la colección de red). Mostrar
una animación de este tipo en el ejemplo actual dará como resultado una
película muy mala e inestable, lo que sugiere erróneamente que hay un
cambio enorme de un punto de tiempo al siguiente. La razón de esto es que actualmente cada una de las redes se ha diseñado por separado. En realidad, cada vez que crea una animación, primero debe calcular un diseño dinámico y escalar las redes a un cuadro delimitador común antes de comenzar la animación. Estos puntos se ilustran en esta sección.
Con fines ilustrativos, veamos la animación sin la aplicación previa de un diseño dinámico. Para abrir la ventana de animación, haga clic en el  icono de la barra de herramientas de Visone . Para iniciar la animación, haga clic en el botón "reproducir" en la parte inferior de la ventana de animación. La velocidad de la animación se puede aumentar (disminuir) moviendo el control deslizante hacia la derecha (izquierda). Al
pasar de un punto de tiempo al siguiente, los lazos que desaparecen se
colorean en rojo, los lazos nuevos emergen en color verde y los nodos se
mueven gradualmente a sus nuevas posiciones. Sin un diseño dinámico apropiado es imposible seguir la evolución de la estructura de la red. De hecho, mientras que el diseño en cada punto de tiempo muestra la estructura de la red respectiva,
icono de la barra de herramientas de Visone . Para iniciar la animación, haga clic en el botón "reproducir" en la parte inferior de la ventana de animación. La velocidad de la animación se puede aumentar (disminuir) moviendo el control deslizante hacia la derecha (izquierda). Al
pasar de un punto de tiempo al siguiente, los lazos que desaparecen se
colorean en rojo, los lazos nuevos emergen en color verde y los nodos se
mueven gradualmente a sus nuevas posiciones. Sin un diseño dinámico apropiado es imposible seguir la evolución de la estructura de la red. De hecho, mientras que el diseño en cada punto de tiempo muestra la estructura de la red respectiva,
Para calcular un diseño dinámico, vaya a la pestaña de visualización y elija en los menús desplegables (de arriba a abajo) diseño , diseño de nodo y diseño dinámico . visone ofrece tres métodos de diseño dinámico: diseño agregado, anclado y vinculado. Encontrará una breve descripción de todos ellos en la página de diseño dinámico . Para nuestro propósito, elija el diseño agregado
, que le da a la animación la máxima estabilidad (los nodos no se
mueven en absoluto al pasar de un punto de tiempo al siguiente). Haga clic en el botón "Colección de diseño" para iniciar el cálculo.
Después de calcular un diseño dinámico, haga clic en el  icono de la barra de herramientas de Visone para ajustar todas las redes en un cuadro delimitador común. Luego, la colección de red se puede animar como se describe anteriormente; esto
ahora debería producir una animación mucho más fluida que muestre la
evolución de la estructura de la red a lo largo del tiempo. Las
propiedades de los nodos o enlaces, como el tamaño o el color, también
se interpolan entre los pasos de la animación; según lo que codifiquen
estas propiedades gráficas, esto permite seguir la evolución de, por
ejemplo, la centralidad a lo largo del tiempo.
icono de la barra de herramientas de Visone para ajustar todas las redes en un cuadro delimitador común. Luego, la colección de red se puede animar como se describe anteriormente; esto
ahora debería producir una animación mucho más fluida que muestre la
evolución de la estructura de la red a lo largo del tiempo. Las
propiedades de los nodos o enlaces, como el tamaño o el color, también
se interpolan entre los pasos de la animación; según lo que codifiquen
estas propiedades gráficas, esto permite seguir la evolución de, por
ejemplo, la centralidad a lo largo del tiempo.
Modelado estadístico de la dinámica de redes
La dinámica de una colección de red que es compatible con Siena se puede modelar a través de la interfaz RSiena . RSiena implementa modelos estocásticos orientados a actores para la evolución de redes y comportamiento. Permite, por ejemplo, probar hipótesis sobre la influencia social y los procesos de selección social en datos empíricos de redes longitudinales. La interfaz de RSiena se inicia desde la pestaña de modelado ; se requiere que la conexión R esté correctamente instalada . Puede encontrar más información sobre la interfaz de RSiena en el tutorial sobre el uso de RSiena desde dentro de visone .
-------------------------------------------------------------------------------
Redes de eventos (tutorial)
Los enlaces en una red de eventos
codifican la interacción con marca de tiempo entre los actores, por
ejemplo, los usuarios que envían correos electrónicos a otros usuarios. Hay una diferencia importante con las redes de estados relacionales , como las redes de amistad. Para ilustrar la diferencia, cuando dos actores son amigos entre sí en algún momento, entonces, si no sucede nada en el medio , seguirán siendo amigos en un futuro muy cercano. Por
el contrario, si alguien envía un correo electrónico a otra persona en
algún momento, no necesariamente envía un correo electrónico a la misma
persona en el siguiente instante. Dicho de otra manera, las relaciones como la amistadtienen
inercia (algo tiene que pasar para cambiarlos), mientras que los
eventos relacionales marcan puntos temporales de interacción.
Este
tutorial es una guía práctica, basada en ejemplos, que ilustra la
importación, transformación, visualización y análisis de redes de
eventos con visone. Puede encontrar más antecedentes sobre las redes de eventos en
y en otros artículos vinculados en las referencias .
La funcionalidad para el análisis estadístico de redes de eventos ha sido reemplazada por el analizador de redes de eventos (eventnet) . Sin embargo, visone todavía se puede usar para el análisis visual de redes de eventos.
Dirija sus preguntas y comentarios sobre este tutorial a mí ( Jürgen Lerner ).
Datos de ejemplo: redes de conflicto político y cooperación
Este tutorial utiliza para ilustrar redes de eventos entre actores políticos que han sido recopilados por el Proyecto de datos de eventos de Penn State (anteriormente Sistema de datos de eventos de Kansas ). Específicamente,
usamos eventos de codificación de datos en o alrededor de la región del
Golfo Pérsico en el período de 1979 a 1999. Este conjunto de datos se
describe y vincula desde la página de Datos de eventos de Penn State . Para seguir los pasos descritos en este tutorial, debe descargar el archivo Gulf_events_preprocessed.zip .
Otra área de aplicación específica para las redes de eventos, utilizando diferentes datos de ejemplo, se trata en el tutorial sobre redes de edición de Wikipedia .
Importación de redes de eventos
visone puede importar listas de eventos desde archivos de valores separados por comas (CSV). Estos
archivos deben contener un encabezado en la primera línea (que
proporcione las etiquetas de las columnas) seguido de cualquier número
de líneas, cada una de las cuales codifica un evento. Por ejemplo, algunas líneas en el archivo de ejemplo se ven así.
"WEIS.code";"Time";"Source";"Target";"Description";"Goldstein.weight";"Type"
...
222;980213;"ISR";"WES";"NONMIL DESTR";-8.7;"conflicto"
223;920717;"SYR";"ISR";"MIL ENGAGEME";-10;"conflicto"
...
Para abrir dicho archivo, haga clic en abrir en el menú de archivos , seleccione archivos de tipo: archivos de lista de eventos (.csv, .txt) , navegue hasta el archivo que desea abrir y haga clic en Aceptar . En
el cuadro de diálogo de opciones de importación (ver a continuación),
debe especificar el carácter que separa las diferentes entradas en cada
línea; este es el punto y coma ( ; ) en nuestro archivo de ejemplo, y un carácter que encierra el texto (si lo hay), este es el doble comillas ( " ) en nuestro archivo de ejemplo.

Para
encontrar la configuración correcta, puede mirar la pestaña de archivo
en el cuadro de diálogo de opciones de importación que le muestra parte
del archivo de entrada.
visone
ahora puede leer las diversas entradas del archivo de entrada, y debe
especificar cómo deben asignarse a la red resultante en el cuadro de
diálogo Especificación de EventNetwork (que se muestra a continuación). Concretamente, debe especificar cómo se codifican los diversos componentes de un evento en el archivo ( pestaña Formato de evento ); cómo iterar sobre la secuencia de red ( pestaña Iterador de eventos ); cómo se asignan los eventos a los atributos de enlace de la red ( pestaña Red de eventos ); y, si lo desea, qué estadísticas deben calcularse al construir la red de eventos ( Estadísticas de Eventnetpestaña). Las
pestañas deben completarse en el orden en que están numeradas en el
cuadro de diálogo, ya que las posibilidades de elección para las últimas
pestañas dependen de la configuración anterior. Si realiza cambios en alguna pestaña, debe establecer posteriormente (nuevamente) los valores para las últimas pestañas.
Formato de evento
En
la pestaña de formato de evento (vea la imagen a continuación), primero
debe especificar qué columnas del archivo de entrada contienen la
información sobre los cinco componentes de un evento ( fuente , destino , hora , tipo y peso ). En nuestro ejemplo, puede establecer los valores como en la imagen a continuación. El significado de los cinco componentes se explica a continuación.
- FUENTE El actor fuente es el que inicia el evento.
- OBJETIVO El actor objetivo es el que recibe el evento.
- HORA La hora indica cuándo ocurrió el evento. visone
admite una amplia gama de codificaciones de tiempo, desde horas
numéricas hasta cadenas que representan la fecha y la hora del
calendario en formatos más comunes o menos comunes. Además, se puede especificar una unidad de tiempo que define la precisión de la variable de tiempo.
- TIPO El tipo de evento es una variable categórica que especifica lo que sucedió. En nuestro ejemplo, hay diferentes opciones para los tipos de eventos. Una posibilidad es la distinción bastante tosca entre eventos cooperativos (positivos) y conflictivos (negativos). La otra posibilidad es distinguir entre los más de 100 tipos de eventos WEIS diferentes. Una
posibilidad intermedia (y eso es lo que haremos a continuación) es usar
solo la distinción entre conflicto y cooperación pero para distinguir
cuantitativamente entre eventos "fuertes" y eventos "débiles" por el
peso del evento. Por ejemplo, el uso de la fuerza militar se considera más serio que una advertencia, aunque ambos son eventos conflictivos.
- PESO El peso del evento es una variable numérica que cuantifica la intensidad del evento con respecto al tipo de evento (ver el ejemplo anterior). Por ejemplo, el compromiso militar tiene un peso de -10,0 mientras que las advertencias tienen un peso de -3,0.

Después de elegir estos cinco componentes, la visión necesita alguna información sobre la interpretación del tiempo. La primera opción es la selección entre tiempo numérico (si los campos de tiempo corresponden a números enteros) o tiempo de calendario (si los campos de tiempo pueden, de alguna manera, especificados a continuación, convertirse en una fecha/hora). Tenemos tiempo de calendario en nuestro ejemplo.
Si la hora viene dada por el calendario, se debe especificar un patrón de formato de hora . visone propone un patrón conocido, entre otros, el patrón aaMMdd que es apropiado para los tiempos de eventos de KEDS. (Este
patrón implica que hay dos dígitos para el año, seguidos de dos dígitos
para el mes, seguidos de dos dígitos para el día del mes; por ejemplo,
940930 para el 30 de septiembre de 1994). Puede ingresar otro dígito que
no sea el propuesto. patrones en el campo de texto si la fecha/hora
tiene un formato diferente (consulte la página web en la clase Java SimpleDateFormatpara ayuda). visone
lo ayuda a encontrar el patrón correcto al mostrar algunas cadenas de
fecha/hora tal como aparecen en el archivo y, siempre que seleccione un
patrón de formato de fecha, el cuadro de diálogo le muestra la hora
actual formateada por el patrón especificado.
Finalmente, tienes que especificar una unidad de tiempo . Si el tiempo es numérico, debe ingresar un número entero en el campo de texto. Si el tiempo está dado por el calendario, puede seleccionar una unidad de tiempo "natural" de Milisegundo a Año . Una
unidad de tiempo adecuada hace que la iteración sobre la secuencia de
eventos (y, potencialmente, el deterioro de los atributos del enlace a
lo largo del tiempo) sea más intuitiva. Al
calcular las estadísticas de la red de eventos, los eventos que ocurren
dentro de la misma unidad de tiempo se tratan como independientes entre
sí. La hora de los eventos KEDS se da por día. Por lo tanto, las unidades de tiempo apropiadas son DÍA o más gruesas.
Tenga
en cuenta que la única información requerida son las columnas que
contienen el origen y el destino; para los demás componentes, puede
tomar valores predeterminados (seleccionando <implícito> en lugar de un encabezado de columna). El valor predeterminado para el tipo de evento es la cadena EVENT (tomar este tipo predeterminado significa que no hay variación en los tipos de eventos, todos tienen el mismo tipo); el peso predeterminado es igual a 1,0; la
hora predeterminada del evento es el número de fila en el archivo de
entrada (de modo que solo se tenga en cuenta el orden de los eventos).
Cuando
haya terminado con todas las configuraciones en la pestaña de formato
de evento, puede crear la lista de eventos haciendo clic en el botón Aplicar (crear eventos) . Un mensaje informa sobre el número de eventos y el número de unidades de tiempo desde el primero hasta el último evento. (Los
eventos se ordenan en orden ascendente por tiempo después de leerlos;
por lo tanto, no es necesario que los eventos estén ordenados por tiempo
en el archivo de entrada).
iterador de eventos
En
la pestaña del iterador de eventos (ver a continuación), debe
especificar la hora de inicio y finalización del intervalo de tiempo que
se procesará y el retraso entre las instantáneas de la red.

Cuando
los eventos han sido creados luego de llenar la pestaña de formato de
evento (ver la sección anterior) visone sugiere como hora de inicio la
hora del primer evento y como hora de finalización la hora del último
evento. Si no desea procesar toda la secuencia de eventos, puede aumentar la hora de inicio y/o disminuir la hora de finalización. Después de hacer clic en el botón superior Aplicar / obtener información , visone le informa sobre la cantidad de eventos y unidades de tiempo en la subsecuencia especificada. Puede tomar todos los eventos sin cambiar los límites del intervalo; esto incluye todos los eventos del 15 de abril de 1979 al 31 de marzo de 1999, como se puede ver en el cuadro de diálogo.
Luego,
debe elegir los puntos de tiempo en los que se creará una instantánea
de red especificando el retraso entre las instantáneas. Puede
ver en el cuadro de diálogo que la secuencia de eventos abarca más de
7200 unidades de tiempo (es decir, días con la configuración actual), lo
que equivale a casi 20 años. El
número de instantáneas debe ser pequeño (algunas 10 o 20 instantáneas
están bien), ya que todas se abren en una nueva pestaña en Visone. Cuando queremos crear una instantánea una vez al año, especificamos crear instantáneas después de cada 365 unidades de tiempo . (El
número de instantáneas es entonces 20). Visone siempre crea una
instantánea al final de la secuencia del evento, incluso si el tiempo de
espera es menor que el número especificado.
Red de eventos
La pestaña para especificar la red de eventos es la más importante: aquí define qué atributos de enlace
de la red de eventos resumen los eventos pasados, cómo los eventos de
varios tipos se suman a estos atributos y cómo cambian con el tiempo.

Lo primero que debe hacer es decidir sobre los atributos del enlace. Aquí puede elegir libremente cualquier nombre de atributo (que facilita recordar la intuición del atributo). Además, se debe especificar un medio tiempo, que define qué tan rápido decaen los atributos con el tiempo. El
medio tiempo tiene el siguiente efecto: cuando un atributo de enlace
particular en una díada particular (par o actores) tiene un valor de 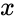 en el tiempo
en el tiempo 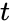 , entonces (si no ocurre ningún evento en la misma díada en el medio) el valor es
, entonces (si no ocurre ningún evento en la misma díada en el medio) el valor es 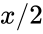 en el tiempo
en el tiempo 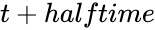 . Intuitivamente, los atributos de enlace con un medio tiempo positivo capturan la interacción reciente ; si el medio tiempo se acorta, capturan una interacción aún más reciente. Un medio tiempo igual a cero o negativo indica que el atributo respectivo no decae con el tiempo; estos atributos capturaninteracción pasada independientemente del tiempo transcurrido.
. Intuitivamente, los atributos de enlace con un medio tiempo positivo capturan la interacción reciente ; si el medio tiempo se acorta, capturan una interacción aún más reciente. Un medio tiempo igual a cero o negativo indica que el atributo respectivo no decae con el tiempo; estos atributos capturaninteracción pasada independientemente del tiempo transcurrido.
En nuestro ejemplo concreto, elegimos los siguientes atributos de enlace que tienen un medio tiempo de (aproximadamente) un año.
- Un atributo cooperación resume los pesos de eventos cooperativos pasados.
- El conflicto de atributos de enlace es similar y resume eventos conflictivos pasados. Este atributo también será no negativo; es decir, un valor más alto significa más conflicto pasado/reciente. (Vea más adelante cómo se logra esto).
- La interacción resume la fuerza de los eventos pasados, independientemente de que sean cooperativos o conflictivos.
- La interacción (no ponderada)
suma el número de eventos pasados, independientemente de si estos son
cooperativos o conflictivos e independientemente de su peso.
- Finalmente cooperación-conflicto suma los pesos (positivos) de los eventos cooperativos y los pesos (negativos) de los eventos conflictivos. Este
atributo es positivo en díadas que tienen más eventos cooperativos (o
eventos cooperativos con mayor peso) y es negativo en díadas en las que
hay más eventos conflictivos (o eventos conflictivos más graves).
Cuando se agregan los atributos del enlace (p. ej., haga clic en el botón Agregar/actualizar todo ), debe especificar cómo los eventos contribuyen a ellos. Al hacer clic en Crear tabla de función de peso, se crea una tabla que tiene una fila para cada atributo de vínculo y una columna para cada tipo de evento. En la celda indexada por un atributo 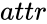 y un tipo de evento , especifica la función que asigna pesos de eventos de tipo a incrementos del atributo de enlace . En nuestro ejemplo, seleccionar la función Identidad en la celda indexada por cooperación de atributo y cooperación de tipo de evento significa que siempre que ocurra un evento de tipo cooperación y peso ,
y un tipo de evento , especifica la función que asigna pesos de eventos de tipo a incrementos del atributo de enlace . En nuestro ejemplo, seleccionar la función Identidad en la celda indexada por cooperación de atributo y cooperación de tipo de evento significa que siempre que ocurra un evento de tipo cooperación y peso ,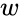 entonces agregaal valor actual del atributo de cooperación . Si hubiéramos elegido SquareRoot como la función de peso en la misma celda, agregaríamos
entonces agregaal valor actual del atributo de cooperación . Si hubiéramos elegido SquareRoot como la función de peso en la misma celda, agregaríamos 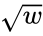 al atributo de cooperación cada vez que ocurra un evento de tipo cooperación y peso . El identificador de función de peso N/A significa que los eventos de ese tipo no provocan ningún cambio en el atributo respectivo. Por ejemplo, los eventos de tipo conflicto no cambian el atributo cooperación . Tenga en cuenta que para el conflicto de atributos y el conflicto de tipos elegimos la función de peso MinusIdentity; por lo tanto, cuando ocurre un evento conflictivo con peso -10, agregamos el valor (positivo) 10 al atributo conflicto (por lo tanto, el atributo conflicto siempre es no negativo y los valores más altos indican más conflictos pasados). La configuración para todos los atributos y tipos se puede ver en la imagen de arriba.
al atributo de cooperación cada vez que ocurra un evento de tipo cooperación y peso . El identificador de función de peso N/A significa que los eventos de ese tipo no provocan ningún cambio en el atributo respectivo. Por ejemplo, los eventos de tipo conflicto no cambian el atributo cooperación . Tenga en cuenta que para el conflicto de atributos y el conflicto de tipos elegimos la función de peso MinusIdentity; por lo tanto, cuando ocurre un evento conflictivo con peso -10, agregamos el valor (positivo) 10 al atributo conflicto (por lo tanto, el atributo conflicto siempre es no negativo y los valores más altos indican más conflictos pasados). La configuración para todos los atributos y tipos se puede ver en la imagen de arriba.
Una vez que se hayan realizado estos ajustes, puede crear las instantáneas haciendo clic en el botón ¡Procesar red de eventos! . Si desea crear una tabla de estadísticas, primero debe completar la pestaña número 4. Pasamos a las estadísticas más adelante y creamos las instantáneas ahora.
Visualización y análisis de redes de eventos.
Con la configuración anterior, Visone abre 20 pestañas de red. Los nodos de la red tienen una etiqueta de atributo que contiene los nombres de los nodos de origen o de destino tal como se proporcionan en el archivo de lista de eventos. Los
enlaces tienen (en nuestro ejemplo) cinco atributos numéricos que
codifican los valores de las funciones de los atributos del enlace en el
momento de la instantánea. Estos
atributos de enlace permiten calcular, por ejemplo, la cantidad total
de conflicto o cooperación recibidos o inicializados por los actores
(calcular el grado de entrada o salida con la fuerza del enlace
establecida en conflicto o cooperación o cualquier otro atributo de enlace). Estos grados pueden, por ejemplo, usarse para filtrado visual mediante mapeolos valores de centralidad al tamaño o color de los nodos o seleccionando nodos por importancia. Se pueden encontrar ejemplos de visualización de redes de eventos en el tutorial sobre redes de edición de Wikipedia . Tenga
en cuenta que todas las tareas de análisis y visualización se pueden
realizar en paralelo para todas las pestañas de red abiertas y tenga en
cuenta que visone también ofrece calcular un diseño dinámico que se puede animar; esto se ilustra en el tutorial sobre colecciones de red . La
imagen a continuación es un ejemplo que coloca a los actores más
involucrados en el centro del dibujo y codifica vínculos más bien
cooperativos en azul y más conflictivos en rojo.

Modelado estadístico del tipo o peso del evento condicional
Al
importar redes de eventos, es posible calcular y guardar estadísticas
de red asociadas con eventos diádicos que se pueden usar para construir y
estimar un modelo estadístico para el tipo de evento condicional . Dichos modelos han sido propuestos en Ulrik Brandes, Jürgen Lerner y Tom AB Snijders (2009): Networks Evolving Step by Step: Statistical Analysis of Dyadic Event Data . Estos
modelos se pueden usar para probar si la red de eventos pasados
explica la probabilidad de que los eventos futuros entre un par dado
de actores sean más bien cooperativos o más bien conflictivos, por
ejemplo
- ¿Tienen los actores una tendencia a pelear con aquellos que los atacaron en el pasado? (Tendencia a tomar represalias.)
- ¿Los actores tienen tendencia a cooperar con los enemigos de sus enemigos, a luchar contra los amigos de sus enemigos, etc.?
Las
estadísticas de la red de eventos se pueden calcular durante la
importación de datos, se guardan en un archivo y luego se pueden
analizar con cualquier software estadístico, como R .
Es importante entender que con la tabla de estadísticas computada por visone se puede estimar un modelo para el tipo de evento condicional , dado que ocurre un evento, tal como lo ha definido Brandes et al. (2009). Con la salida de visone, no puede modelar la probabilidad de que dos actores interactúen en absoluto. (Dichos modelos se pueden especificar y ajustar, por ejemplo, con el paquete R relevante o con el analizador de redes de eventos de software (eventnet)
, donde en este último puede elegir si condicionar o no las fuentes,
los objetivos o los eventos). Más sobre la diferencia entre modelar el
tipo de evento condicional y el tipo de evento marginal (incondicional)
se puede encontrar en las diapositivas Modelado de frecuencia y tipo de interacción en redes de eventos(.pdf) .
Para
que el análisis sea comparable con el presentado en Brandes et al.
(2009), modificamos ligeramente los atributos de enlace en la pestaña de
la red de eventos (ver más abajo). Concretamente fijamos el medio tiempo en 30 días e incluimos únicamente los atributos conflicto y cooperación . (La
configuración en el formato del evento sigue siendo la misma y en las
pestañas del iterador de eventos puede establecer el retraso entre las
instantáneas en 7291 para crear solo una instantánea).

Estadísticas de eventos
Las
estadísticas que se calcularán se definen en la pestaña de estadísticas
de eventnet del cuadro de diálogo de importación (ver más abajo). Primero debe especificar si se debe crear una tabla de estadísticas; en caso afirmativo, se debe elegir un archivo de salida y se deben definir una o más estadísticas.

Las estadísticas se utilizan para modelar eventos de la siguiente manera: cada vez que ocurre un evento iniciado por un nodo de origen y dirigido a un nodo de destino , entonces la díada (origen, destino) se integra en la red de eventos pasados, es decir, todos eventos que ocurrieron antes del evento actual. Las
estadísticas de la red de eventos describen aspectos relevantes de esta
red de eventos pasados con respecto a la díada específica. visone
ofrece tres tipos diferentes de estadísticas: estadísticas de díadas,
estadísticas de grados y estadísticas de triángulos, que se pueden
variar con respecto a la dirección del borde y/o los atributos del
enlace. Después de definir las estadísticas, deben agregarse a la red de eventos haciendo clic en el botón Agregar / actualizar .
Estadísticas de parejas
Las estadísticas de díada codifican aspectos de los eventos pasados desde el origen hasta el destino o en la otra dirección. Esas son las estadísticas de díada que codifican cómo la fuente interactuó con el objetivo en el pasado o cómo el objetivo interactuó con la fuente . En nuestro ejemplo, definimos cuatro estadísticas diadas diferentes que se obtienen al cambiar la dirección (la inercia si se consideran los eventos de SALIDA , del origen al destino , y la reciprocidad si se consideran los eventos de ENTRADA, del destino al origen ) .- se consideran) y el atributo de vínculo ( positivo para cooperación pasada y negativo para conflicto pasado).
Intuitivamente, si los actores tienden a tomar represalias, entonces esperamos que la estadística de reciprocidad negativa esté negativamente relacionada con el peso del próximo evento.
Estadísticas de grado
Las estadísticas de grado resumen los eventos pasados alrededor de la díada (fuente, objetivo) por el grado ponderado (fuera/entrada) de fuente u objetivo . Los enlaces pueden ser ponderados por cualquier atributo. Por ejemplo, la estadística neg_outdeg_source suma los valores del atributo de conflicto en todos los enlaces que comienzan en el nodo de origen (no solo aquellos que se dirigen al destino ).
Intuitivamente,
si los actores que iniciaron muchos eventos conflictivos en el pasado
tienden a hacerlo en el futuro, entonces esperamos una relación negativa
entre el estadístico neg_outdeg_source y el peso de los eventos.
Estadísticas del triángulo
Las estadísticas triangulares resumen la red de eventos pasados alrededor de la díada (fuente, objetivo) mediante relaciones indirectas tipificadas y ponderadas desde la fuente sobre cualquier tercer nodo hasta el objetivo o al revés. Puede seleccionar los atributos de los enlaces adjuntos al origen y al destino y la dirección que puede ser OUT (solo enlaces salientes con respecto al origen / destino ), IN (solo enlaces entrantes) o SYM (sumando los atributos de los lazos entrantes y salientes).
Por ejemplo, la estadística enemigo_de_amigo itera sobre todos los actores A en la red, multiplica el valor del atributo de cooperación en los enlaces que conectan la fuente y A (en ambas direcciones) con el valor del atributo de conflicto en los enlaces que conectan el objetivo y A (en ambas direcciones ). ), suma estos productos para todo A y devuelve la raíz cuadrada de esta suma. Intuitivamente, el valor de la estadística enemigo_de_amigo en la díada (fuente, objetivo) es alto si hay muchos otros actores A que cooperaron con la fuentey estaban en conflicto con el objetivo ; la teoría del equilibrio estructural predice que entonces es más probable que la fuente luche contra el objetivo .
Comenzando el cómputo
Una vez que se especifican el archivo de salida y las estadísticas, haga clic en la red de eventos de proceso. botón. Las
instantáneas se crean como se define en la pestaña del iterador de
eventos y las estadísticas se calculan como se define en la pestaña de
estadísticas de eventnet.
Tenga en cuenta que las estadísticas asociadas con un evento que ocurre en el tiempo t son solo una función de los eventos que ocurrieron antes (estrictamente antes de t ), y no dependen de los eventos que ocurren en la misma unidad de tiempo.
El archivo de estadísticas de eventnet calculado ( gulf_events_stats.csv en nuestro ejemplo) es una tabla en formato CSV en la que cada fila corresponde a un evento del archivo de entrada. Primero
se repiten los componentes del evento (origen, destino, tiempo, tipo y
peso), seguidos por los valores de todas las estadísticas.
Calcular
las estadísticas de los 300.000 eventos puede llevar de cinco a diez
minutos en una computadora portátil estándar actual. Una vez que finaliza el cálculo, verá que el mensaje se procesa correctamente en el cuadro de diálogo eventnet. Si recibe un mensaje de error, puede echar un vistazo a la consola de Visone, donde puede obtener más información.
Modelado del peso del evento condicional
El archivo de estadísticas ahora se puede analizar con cualquier software estadístico: describimos lo siguiente para el entorno R para la computación estadística (consulte también el tutorial de visone en la consola R ).
Primero configure el directorio de trabajo R en el directorio donde se encuentra el archivo de estadísticas, por ejemplo
setwd("c:/juergen/proyectos/event_data/keds/Gulf/")
Para leer el archivo en una tabla y ver algunas estadísticas de resumen, escriba
eventnet.stats <- read.csv("gulf_events_stats.csv", sep=";")
resumen (eventnet.stats)
Modelamos
solo aquellos eventos que no son bucles automáticos (los bucles ya
podrían haberse eliminado mientras se preprocesaba la lista de eventos
de entrada; estos dos procedimientos no son equivalentes ya que en
nuestro caso las estadísticas también son funciones de bucles).
eventnet.stats <- eventnet.stats[como.personaje(eventnet.stats$FUENTE) != como.personaje(eventnet.stats$OBJETIVO),]
resumen (eventnet.stats)
Un primer modelo muy simple es un modelo lineal para el peso del evento (desde el origen hasta el destino ), explicado por los eventos conflictivos pasados en la otra dirección (es decir, desde el destino dirigido al nodo de origen ).
modelo.1 <- lm(PESO ~ 1 + reciprocidad_negativa, datos = eventnet.stats)
resumen (modelo.1)
Un resumen del modelo estimado produce (entre otros) el siguiente resultado:
Coeficientes:
Estimación estándar Error valor t Pr(>|t|)
(Intersección) -5.730e-01 8.866e-03 -64.63 <2e-16 ***
reciprocidad_negativa -2.629e-03 2.829e-05 -92.92 <2e-16 ***
---
signif. códigos: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
La interpretación es que parece haber un hábito de represalias: si el objetivo ha iniciado eventos conflictivos hacia la fuente , entonces el peso de los eventos de la fuente al objetivo tiende a ser menor (coeficiente significativamente negativo para la estadística de reciprocidad negativa ), lo que significa que el tipo de evento se siente atraído hacia el conflicto. El valor del coeficiente (alrededor de -0,003) parece ser muy pequeño. Sin embargo, este parámetro resume el cambio en el peso del evento cuando la reciprocidad negativa aumenta en uno. Mecanografía
sd(eventnet.stats$negative_reciprocity)
vemos que la desviación estándar de esta estadística es de alrededor de 290, lo que significa que el indicador de reciprocidad negativa generalmente varía en cientos.
Un
modelo más complejo prueba los efectos del balance estructural,
controlando la variación en grados y la interacción pasada directa. (Este es el modelo tomado de Brandes et al. (2009).)
modelo.2 <- lm(PESO ~ 1 + inercia_positiva + inercia_negativa +
reciprocidad_positiva + reciprocidad_negativa +
pos_outdeg_source + neg_outdeg_source +
pos_indeg_source + neg_indeg_source +
pos_outdeg_target + neg_outdeg_target +
pos_indeg_objetivo + neg_indeg_objetivo +
amigo_de_amigo + amigo_de_enemigo +
enemigo_de_amigo + enemigo_de_enemigo,
datos = eventnet.stats)
Obtenemos los siguientes resultados.
Coeficientes:
Estimación estándar Error valor t Pr(>|t|)
(Intersección) -7.707e-01 1.127e-02 -68.371 < 2e-16 ***
inercia_positiva 5.814e-03 2.723e-04 21.347 < 2e-16 ***
inercia_negativa -2.145e-03 7.214e-05 -29.730 < 2e-16 ***
reciprocidad_positiva 3.071e-03 3.125e-04 9.827 < 2e-16 ***
reciprocidad_negativa -2.188e-03 8.175e-05 -26.768 < 2e-16 ***
pos_outdeg_source 1.391e-03 6.853e-05 20.295 < 2e-16 ***
neg_outdeg_source -2.426e-04 3.250e-05 -7.463 8.48e-14 ***
pos_indeg_source -6.058e-04 1.022e-04 -5.930 3.02e-09 ***
neg_indeg_source 1.028e-04 3.259e-05 3.153 0.001615 **
pos_outdeg_target 9.800e-04 7.372e-05 13.293 < 2e-16 ***
neg_outdeg_target 2.142e-05 3.192e-05 0.671 0.502180
pos_indeg_target -6.572e-04 9.495e-05 -6.922 4.48e-12 ***
neg_indeg_target 6.988e-05 3.051e-05 2.290 0.022014 *
amigo_de_amigo 1.884e-03 5.349e-04 3.523 0.000427 ***
amigo_del_enemigo -8.913e-04 2.912e-04 -3.061 0.002205 **
enemigo_de_amigo -1.308e-03 2.874e-04 -4.553 5.30e-06 ***
enemigo_del_enemigo -1.935e-04 1.532e-04 -1.263 0.206593
---
signif. códigos: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Entre
otros resultados, este modelo proporciona evidencia para algunas, pero
no todas, las hipótesis derivadas de la teoría del equilibrio
estructural: los amigos de los amigos tienden a interactuar de manera
más cooperativa, mientras que los amigos de los enemigos y los enemigos
de los amigos tienden a pelear entre sí. Por otro lado, el parámetro asociado a la estadística enemigo_del_enemigo no es significativo. Tenga en cuenta que el conjunto de datos para ajustar este modelo es diferente del tomado en Brandes et al. (2009),
ya que aquí también incluimos bucles automáticos para calcular las
estadísticas (aunque los eventos que conectan a un actor consigo mismo
no se han utilizado al ajustar el modelo lineal).
Obviamente,
modelar el tipo de evento o el peso del evento como una función
estocástica de las estadísticas de la red de eventos no está restringido
a modelos lineales. Además,
si el modelo debe controlar las covariables a nivel de actor o díada
(como el tamaño de la población de un país o un indicador de si dos
países tienen una frontera común), estas se pueden fusionar en la tabla
de estadísticas después del procesamiento de la red de eventos
Referencias
----------------------------------------------------------------
Diferencia de grafos (tutorial)
Este
tutorial muestra cómo se puede usar la consola R para manipular y
comparar gráficos más allá de la funcionalidad que proporciona Visone.
Guión
Supondremos a continuación que tiene dos redes en el mismo conjunto de nodos y desea averiguar cuál de sus bordes difiere. Una condición previa importante es que exista un atributo de identificación que:
- da a cada nodo un valor
- tiene el mismo valor para cada nodo en ambas redes
- tiene dentro de una red un valor diferente para cada nodo.
Este atributo se utilizará a continuación para establecer la relación entre las dos redes. Para este tutorial asumimos que se llama nodeid y es de tipo text .
Creando la red de diferencias
Seleccione la pestaña que contiene su primera red y abra la consola R. Asigne un nombre a su red en el campo de entrada junto al botón Enviar y presione "enviar". Para este tutorial, asumiremos que se llama g1 .
Ahora el comando ls() debería mostrar g1 . ls() siempre se puede usar para enumerar todos los objetos en el entorno R actual.
Envíe su segunda red a la consola R: selecciónela en la ventana principal, asígnele el nombre ( g2 en este tutorial) y presione "enviar". El comando ls() ahora debería mostrar las dos redes.
La idea de este tutorial es crear la red de diferencias mediante la resta de las matrices de adyacencia de las redes. Por lo tanto, en primer lugar es necesario obtenerlos en el orden de nodo correcto. Lo lograremos derivando un orden de nodos del atributo que identifica los nodos ( nodeid ).
El orden de los nodos en g1 se deriva de: order1<-sort(V(g1)$nodeid,index.return=T)$ix .
Este comando combina varias cosas, visitémoslas en detalle:
- V(g1) produce los nodos (vértices) de g1
- V(g1)$nodeid luego proporciona la lista de valores de atributo de nodeid para esos nodos, es decir, proporciona una lista de ID de nodo en el orden de los nodos en el gráfico
- sort() hace lo que dice, ordena.
- Como primer parámetro proporcionamos la lista de valores para ordenar ( V(g1)$nodeid , los id de nodo).
- Como no estamos interesados en la lista ordenada sino en su orden, le decimos a sort() que devuelva este orden con el parámetro index.return=T .
- Sort devolverá una lista con dos campos x nuestra lista ordenada y ix los índices de la lista original en orden ordenado. De esos, solo necesitamos el segundo y, en consecuencia, lo almacenamos en order1 .
Hacemos lo mismo para la segunda red con order2<-sort(V(g2)$nodeid,index.return=T)$ix . Las dos listas order1 y order2
ahora se pueden usar como orden de permutación en los conjuntos de
nodos de las dos redes, es decir, colocan los nodos de las dos redes en
el mismo orden. Como ejemplo , V(g1)$nodeid[order1] enumera los ID de nodo en el orden recién establecido y debe ser exactamente igual que V(g2)$nodeid[order2] , es decir, los ID de nodo de la segunda red en el orden correcto.
Para obtener la matriz de adyacencia de una red, usaríamos el comando a1<-get.adjacency(g1) . Aquí queremos estas matrices en nuestro orden de nodos y, por lo tanto, las reordenamos en consecuencia por a1<-get.adjacency(g1)[order1,order1] . La parte " [order1,order1] " simplemente reordena filas y columnas de la matriz. Use los dos comandos a1<-get.adjacency(g1)[order1,order1] y a2<-get.adjacency(g2)[order2,order2] para crear a1 y a2 , las dos matrices de adyacencia de sus redes en el orden de nodo correcto .
La diferencia entre ellos se puede derivar fácilmente como la diferencia de matriz de entrada: diff<-a2-a1 . diff es la matriz con entrada -1 para un borde que se eliminó, 1 para un borde agregado y 0 si el borde no cambió.
Ahora podemos crear la red solo con los bordes modificados: diffnetwork<-graph.adjacency(diff,weighted="change") . La función graph.adjacency() crea un gráfico a partir de una matriz de adyacencia con un borde para cada entrada que no es igual a cero. En que el parámetro ponderado="cambio" almacena los valores correspondientes en un atributo de borde con el nombre "cambio". Antes de volver a cargarlo en Visone, queremos volver a adjuntar los ID de nodo con: V(diffnetwork)$nodeid<-V(g1)$nodeid[order1]
Finalmente,
puede seleccionar la red recién creada "diffnetwork" en el cuadro
combinado del cuadro de diálogo (junto al botón "cargar red") y cargarla
en visone usando el botón "cargar red".
Visualizando la diferencia
Cierre la consola y debería ver su red de bordes modificados. Suponiendo que sus redes no estén dirigidas, cada borde se mostrará como bordes opuestos dirigidos. Use
la pestaña "transformación" y los "enlaces" y "fusionar" con la opción
"dirigido al contrario" para fusionarlos en bordes no dirigidos.
Volviendo al gráfico no dirigido, sabemos qué bordes cambiaron pero no, qué les sucedió. Usando el atributo "cambio" creado en R podemos visualizar fácilmente lo que sucedió:
- Seleccione la pestaña "visualización".
- Vaya a la categoría "mapeo", escriba "color" y propiedad "color de enlace".
- Como atributo elija "cambiar" y método "tabla de colores".
- Ahora puede seleccionar el color para -1 , es decir, los bordes que se eliminaron y 1 (los bordes agregados). Para este ejemplo usaremos rojo y azul.
- Use
el botón "visualizar" para aplicar su configuración de color y debería
obtener un gráfico con un borde rojo para cada borde que estaba presente
en la primera red pero no en la segunda y un borde azul para cada borde
que estaba presente en la segunda. pero no en el primero.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}