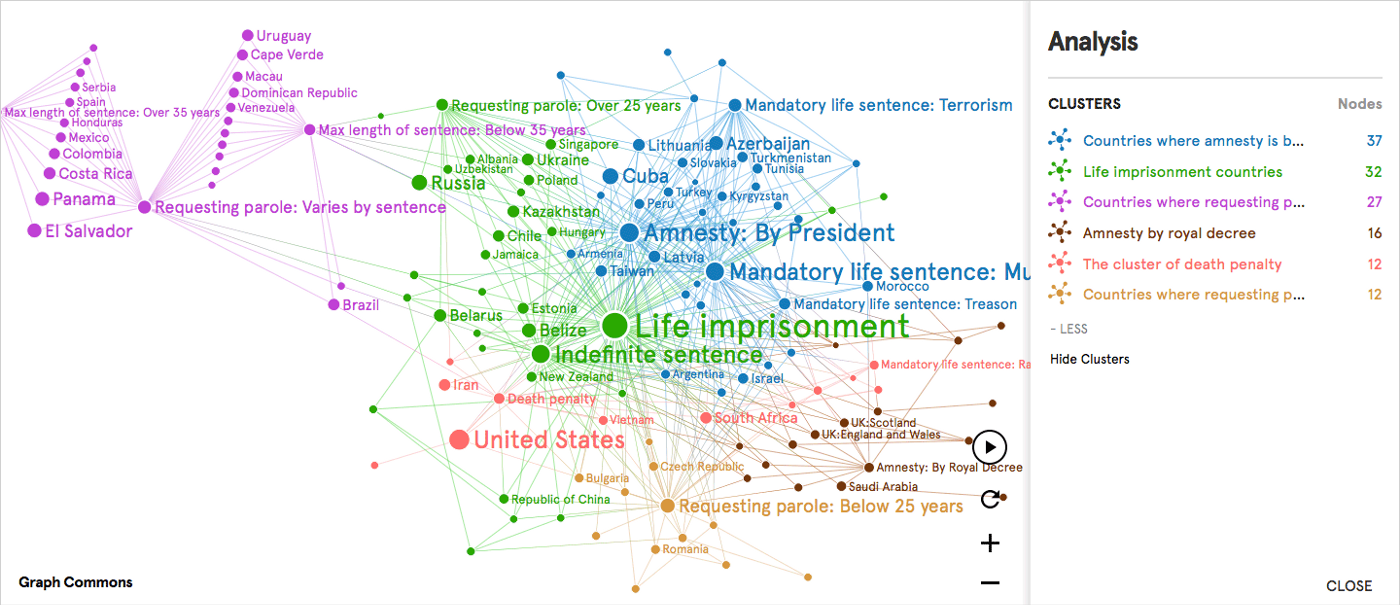
Tendencia creciente de los científicos a cambiar de tema
An Zeng, Zhesi Shen, Jianlin Zhou, Ying Fan, Zengru Di, Yougui Wang, H. Eugene Stanley y Shlomo Havlin
Nature Communications
volume 10, Número de artículo: 3439 (2019)
Resumen
A pesar de los esfuerzos persistentes para comprender la creatividad de los científicos durante las diferentes etapas de la carrera, se sabe poco sobre la dinámica subyacente del cambio de tema de investigación que impulsa la innovación. Aquí, analizamos los registros de publicación de científicos individuales, con el objetivo de cuantificar su dinámica de cambio de tema y su influencia. Encontramos que la red conjunta de documentos de un científico exhibe una estructura comunitaria clara donde cada comunidad principal representa un tema de investigación. Nuestro análisis sugiere que los científicos tienen una distribución limitada del número de temas. Sin embargo, los investigadores hoy en día cambian más frecuentemente entre temas que los de los primeros días. También encontramos que la alta probabilidad de cambio al inicio de la carrera se asocia con una baja productividad general, pero con una alta productividad general en la última carrera. Curiosamente, la cita promedio por trabajo, sin embargo, está correlacionada negativamente en todas las etapas de la carrera con la probabilidad de cambio. Proponemos un modelo que puede explicar las principales características observadas.
Introducción
Descubrir los mecanismos que rigen las actividades de investigación de los científicos individuales y su evolución con el tiempo es fundamental para comprender y gestionar una amplia gama de cuestiones en la ciencia, desde la formación de científicos hasta el descubrimiento colectivo de nuevos conocimientos1,2,3,4,5. La mayor disponibilidad de grandes conjuntos de datos que capturan actividades de investigación crea una oportunidad sin precedentes para explorar los patrones dinámicos de producción científica y recompensas utilizando herramientas matemáticas y computacionales de vanguardia6,7,8. Además de los primeros trabajos destinados a evaluar el impacto científico con citas de científicos9, índice h10 y variantes relacionadas11, hay una ola reciente de estudios centrados en cuantificar y modelar la evolución de la creatividad investigadora a lo largo de las carreras de los científicos12,13,14,15. 16,17,18,19. Se ha demostrado que la producción acumulada de los científicos medida por el número de artículos exhibe un crecimiento persistente con el tiempo12, que está asociado con el conocido efecto Matthew20. Al asociar cada publicación con sus citas, se ha revelado que el trabajo más influyente de un científico aparece al azar dentro de la secuencia de sus publicaciones13. Un trabajo de seguimiento revela que la carrera de los científicos puede involucrar un período de rachas calientes durante el cual el desempeño de un individuo es sustancialmente más alto que su desempeño típico14. También se han investigado otras cuestiones, como la evolución de la creatividad de los científicos15, la reputación16, los lazos sociales17 y la movilidad18,19 a lo largo de sus carreras.
Una fuerza impulsora fundamental de la investigación científica es la evolución del interés de investigación de los científicos5, que se refleja en el cambio de los científicos entre diferentes temas de investigación a lo largo del tiempo. Los sociólogos de la ciencia han hecho un esfuerzo persistente en la comprensión cualitativa de los principios que rigen la selección de temas de los científicos, y señalaron que puede ser el resultado de una compensación entre la producción conservadora y la innovación arriesgada21. También hay modelos ilustrativos ricos propuestos por sociólogos para clasificar las estrategias de investigación adoptadas por los científicos22. Con la creciente disponibilidad de los datos de la publicación científica, el tema de la selección de temas comenzó a analizarse cuantitativamente en los últimos años. Específicamente, se han propuesto varios modelos de temas basados en el lenguaje para detectar campos de investigación de científicos23,24. También se ha revelado empíricamente que la financiación científica puede aumentar el interés en las áreas apoyadas25. Un trabajo reciente señaló que el interés de investigación de los físicos individuales podría cambiar significativamente desde el principio hasta el final de la carrera, con la distancia entre los intereses que se mide en función de los códigos de clasificación de campo en física26. Sin embargo, la variación del cambio de tema durante la carrera individual no se ha estudiado hasta ahora. Aquí preguntamos: ¿cómo identificar los temas en los que está involucrado un científico individual? ¿Con qué frecuencia un científico cambia entre diferentes temas de investigación? ¿Mejora el impacto de los científicos si cambian más frecuentemente entre temas? ¿Cambia el tema el cambio de comportamiento de los científicos durante el siglo pasado?
Para abordar estas preguntas, construimos una red para cada científico que caracteriza las relaciones entre sus documentos. La estructura de esta red revelará de inmediato cómo se encarnan los intereses de investigación de un científico individual. Este marco nos permite, aplicando el análisis de la comunidad, especificar los diversos intereses de investigación y, en consecuencia, investigar la dinámica detallada del cambio de interés de investigación de un científico, así como la evolución de la tendencia de cambio durante el siglo pasado y su relación con el impacto de la investigación. El análisis en este artículo se basa principalmente en físicos e informáticos. Sin embargo, nuestro método es general y no está restringido a la disponibilidad de códigos de clasificación de campo, por lo que puede aplicarse al análisis de científicos de cualquier disciplina.
Resultados
Redes de científicos individuales y sus propiedades estructurales.
En este documento, analizamos los datos de publicación científica de las revistas de la American Physical Society (APS). Datos de nombre de autor desambigados proporcionados en la ref. 13 se utiliza para asignar cada artículo a sus autores, lo que da como resultado los registros de publicación de 236,884 científicos distintos (para estadísticas básicas de estos datos, ver la Figura complementaria 1). Para investigar cómo se relacionan los documentos de un científico individual, construimos para cada científico una red de co-cita (CCN), en la que cada nodo es un documento escrito por este científico y dos documentos están vinculados si comparten al menos uno referencia. Este enfoque de construir enlaces entre nodos (documentos) basados en sus vecinos comunes se llama acoplamiento bibliográfico en Scientometrics27,28 y también se ha utilizado ampliamente en el análisis de otros sistemas reales, como los sistemas de comercio internacional29 y los sistemas sociales en línea30. Las comunidades de cada red co-citadora de un científico se identifican con el algoritmo de despliegue rápido, que detecta comunidades maximizando la función de modularidad31. Por lo general, una red contiene varias comunidades de gran tamaño, así como algunos grupos pequeños y nodos aislados. Las principales comunidades representan los principales temas de investigación de este científico. Como el tamaño de la red debe ser lo suficientemente grande como para garantizar resultados significativos de detección de la comunidad, consideramos en este estudio a todos los científicos que han publicado al menos 50 artículos en las revistas APS (3420 científicos, para la distribución de sus años de carrera iniciados, ver Fig. Suplementaria. 2) Los resultados para los científicos con menos artículos (al menos 20 artículos, 15.373 científicos) son similares y se informan en las Figs suplementarias. 17 y 18. Además, hemos estudiado las comunidades detectadas en la red de citación ponderada, donde los enlaces se ponderan de acuerdo con el número de referencias compartidas. La estructura de la comunidad no se altera significativamente, ya que los pesos grandes tienden a ubicarse en los enlaces dentro de las comunidades (ver Figura 3 complementaria). Nuestro análisis de la comunidad también se ha examinado utilizando una función de modularidad modificada con un parámetro de resolución ajustable (ver Figuras suplementarias 19, 20) y en otro conjunto de datos de la informática (ver Figuras suplementarias 23-25) y para todas las pruebas, las conclusiones principales Se ha encontrado que son similares.
La ilustración del CCN de un científico típico altamente citado se da en la Fig. 1. La matriz de conectividad de la comunidad en la Fig. 1c muestra que los nodos dentro de cada comunidad están bien conectados, sin embargo, los nodos entre comunidades están mucho menos conectados. La serie de tiempo presentada en la figura 1d describe la historia de crecimiento de la red y revela cómo este científico se mueve de un tema de investigación a otro durante su carrera. En la serie de tiempo, cada punto es un papel, y los diferentes colores representan diferentes comunidades en la red de co-cita. La altura del punto es el número de enlaces que tiene el papel en la red.
Figura 1.

Ilustración de la red de citas compartidas (CCN) de un científico típico altamente citado y su historia de crecimiento. a Los datos y el método utilizados para construir la red de conexión. Los documentos escritos por el científico están marcados en verde, y las referencias de estos documentos están marcadas en rojo. b La red de citas consta de todos los artículos publicados por este científico. Cada documento está representado por un nodo, y dos documentos están conectados si comparten al menos una referencia. Las comunidades de esta red se identifican con el algoritmo de despliegue rápido, que detecta comunidades maximizando la función de modularidad. La red contiene varias comunidades de gran tamaño, así como algunos grupos pequeños y nodos aislados. Cada comunidad importante representa un tema de investigación principal de este científico. c La matriz de conectividad de la comunidad muestra que los nodos dentro de cada comunidad están bien conectados, sin embargo, los nodos de diferentes comunidades están mucho menos conectados. Aquí, la conectividad entre dos comunidades se calcula como el número real de enlaces entre ellas sobre el número máximo posible de enlaces entre ellas. d La serie de tiempo presentada en la parte inferior describe la historia de crecimiento de la red y, mientras tanto, revela cómo esta científica se mueve de un tema de investigación a otro durante su carrera. En la subfigura de series de tiempo, cada punto es un papel, y el color corresponde a la comunidad en la red de co-cita. La altura del punto es el número de enlaces (es decir, conectividad) que tiene el papel en la red
Primero nos centramos en las propiedades estructurales de las redes de co-cita (CCN). Para el CCN de cada científico, calculamos el tamaño de su componente gigante (GC) y estudiamos su correlación con el tamaño de la red, como se muestra en el diagrama de dispersión presentado en la Fig. 2a. Se ve que la mayoría de los puntos están ubicados cerca de la línea diagonal, lo que indica que los CCN generalmente están bien conectados y tienen GC relativamente grandes (consulte la Figura complementaria 4 para ver los resultados con las redes, incluidas las relaciones también citadas). Esto también se ve en el recuadro donde se observa una distribución significativa sesgada a la derecha del tamaño relativo de GC. La Figura 1c sugiere que un CCN tiene una estructura comunitaria. Como soporte estadístico para este fenómeno, graficamos en la Fig. 2b la modularidad maximizada, Qreal, en CCN reales y la modularidad maximizada, Qrand, en sus contrapartes reorganizadas conservadas en grados. Para cada CCN de cada científico, generamos 100 contrapartes aleatorias, y Qrand se obtiene promediando la modularidad maximizada de estas contrapartes. Todos los puntos en la Fig. 2b se encuentran debajo de la línea diagonal, lo que indica que Qrand es más pequeño que Qreal. Para medir la importancia de la diferencia entre Qreal y Qrand, realizamos la prueba t de una muestra de la modularidad de la CCN de cada científico y sus contrapartes aleatorias. Todos los valores p obtenidos son significativamente más pequeños que 0.01, lo que indica que la modularidad de los CCN es significativamente más grande que sus contrapartes aleatorias (ver una ilustración de la diferencia significativa entre Qreal y Qrand en la figura complementaria 5).
Figura 2

Propiedades estructurales de redes de citación. a El tamaño de la red de co-cita (CCN) versus el tamaño del componente gigante (GC) de CCN. Cada punto representa un científico. La mayoría de los puntos se encuentran debajo pero cerca de la línea diagonal, lo que indica que los CCN están en general conectados y tienen GC relativamente grandes. Esto está respaldado por el recuadro donde se presenta la distribución del tamaño relativo de GC. b La modularidad maximizada en CCN reales (Qreal) y la modularidad maximizada en sus contrapartes reorganizadas conservadas en grado (Qrand). Todos los puntos se encuentran debajo de la línea diagonal, lo que indica que la estructura de la comunidad en las redes reales es realmente significativa. c La distribución del número de comunidades (nc) para todos los científicos. Se presentan tres curvas donde se tienen en cuenta todas las comunidades (leyenda como todas las comunidades), se eliminan las comunidades pequeñas con menos de 3 nodos (leyenda como tamaño> 2) y se eliminan las comunidades pequeñas con menos de 6 nodos (leyenda como tamaño> 5) d Fracción de papeles en diferentes comunidades. e Probabilidad acumulada inversa de fracción de nodos en la comunidad más grande (la leyenda como la principal), las dos comunidades más grandes (la leyenda como las dos principales) y las tres comunidades más grandes (la leyenda como las tres principales), respectivamente. f El coeficiente de Gini de la distribución de códigos PACS en diferentes comunidades. Las comunidades se clasifican por tamaño en orden descendente. Un coeficiente de Gini más grande corresponde a una distribución más heterogénea, lo que sugiere que una mayor fracción de documentos en una comunidad comparte los mismos códigos PACS. Los datos reales se comparan con una contraparte aleatoria, donde los códigos PACS se reorganizan entre los documentos de cada científico individual mientras se preserva la estructura de la comunidad. Las barras de error en esta figura representan desviaciones estándar
Dado que los documentos tienden a agruparse en comunidades en CCN, una pregunta interesante es cuál es el número típico de comunidades que tiene un científico. Mostramos en la figura 2c, la distribución del número de comunidades para todos los científicos. El número de comunidades aparentemente está ampliamente distribuido. Sin embargo, como los CCN pueden consistir en nodos aislados o grupos muy pequeños, usamos un umbral para eliminar comunidades que son demasiado pequeñas para ser consideradas como un campo de investigación de un investigador. Después de filtrar, las distribuciones del número de comunidades que un científico se ha vuelto muy estrecho, alcanzan un máximo de 4 y 3 si solo se consideran comunidades con tamaños mayores que 2 y 5, respectivamente. En el siguiente análisis, definimos las comunidades principales como tales de más de dos nodos. Para comprender mejor el tamaño de la comunidad en las CCN, mostramos en la figura 2d la fracción de documentos en cada comunidad ordenados por tamaño en orden descendente. La fuerte disminución de la curva indica que varias comunidades principales comprenden la mayoría de los nodos. Una investigación adicional de la probabilidad acumulada inversa de fracción de nodos en varias comunidades más grandes indica que para la mitad de los científicos, las tres comunidades más grandes incluyen más del 70% de sus documentos, como se ve en la figura 2e.
En cada CCN, una comunidad importante contiene documentos que están topológicamente cerca uno del otro. Para validar si los documentos de una comunidad están realmente en temas de investigación similares32,33, analizamos el código PACS (un código de clasificación de campo en física) de los documentos que pertenecen a la misma comunidad. Mostramos en la Fig. 2f, el coeficiente de Gini34 de la distribución de códigos PACS en diferentes comunidades. Un coeficiente de Gini mayor corresponde a una distribución más heterogénea de los códigos PACS en una comunidad. Los datos reales se comparan con una contraparte aleatoria, donde los códigos PACS se reorganizan entre los documentos de cada científico individual mientras se preserva la estructura de la comunidad. Encontramos que el coeficiente de Gini promedio en datos reales es mayor que el de la contraparte aleatoria, con un valor de p menor que 0.01 en la prueba de Kolmogorov-Smirnov de las distribuciones de coeficientes de Gini correspondientes. Por lo tanto, nuestros resultados sugieren que los documentos en una comunidad tienden a compartir los mismos códigos PACS, y las comunidades detectadas reflejan distintos campos de investigación de un científico.
Evolución de la probabilidad de cambio y su influencia.
Una vez que las comunidades detectadas están marcadas en la serie de tiempo (Fig. 1d), se puede investigar la dinámica del interés de los científicos en diferentes temas de investigación. Con este fin, mostramos primero en la Fig. 3a, el número medio de comunidades principales involucradas anualmente para cada científico. Se puede ver que los científicos tienden a involucrarse en un pequeño número de comunidades durante sus primeros años de carrera. Luego, el número de comunidades involucradas anualmente aumenta hasta alcanzar su punto máximo alrededor del vigésimo año de la carrera, y luego disminuye gradualmente. Sin embargo, cuando un científico publica más artículos en un año, podría tener un mayor número de comunidades involucradas anualmente por pura casualidad. Para eliminar este efecto (ver la figura complementaria 6), proponemos otra métrica llamada probabilidad de cambio que calcula la probabilidad de que un científico cambie de una comunidad principal a otra comunidad principal entre dos publicaciones adyacentes. La Figura 3b muestra la evolución de la probabilidad de cambio promedio en diferentes años de carrera. El pico de probabilidad de cambio también es alrededor del vigésimo año de carrera, lo que indica que los científicos tienden a cambiar menos durante su carrera inicial, mientras que cambian más en la etapa posterior de su carrera. Para eliminar aún más la variada intensidad de productividad a lo largo de una carrera, mostramos en el recuadro de la Fig. 3b la probabilidad media de cambio en función del número de artículos publicados en una carrera. Se ve que la decadencia de la probabilidad de cambio en la carrera posterior se vuelve aún menos obvia, formando un patrón de aumento y nivelación de la probabilidad de cambio. Estos resultados sugieren que los científicos no están siguiendo el comportamiento óptimo de alimentación35, es decir, explorar al principio y luego volverse significativamente más explotadores al final. El cambio de comportamiento de los científicos probablemente se deba a otros factores. Específicamente, los científicos probablemente apuntan a minimizar la probabilidad de fracaso al comienzo de la carrera, por lo que cambian menos en este período. Luego se vuelven más riesgosos al cambiar con más frecuencia en su carrera posterior.
Figura 3

Evolución de las comunidades involucradas anualmente y probabilidad de cambio. a El número medio de comunidades principales involucradas anualmente para científicos individuales en diferentes años de carrera. b La probabilidad de cambio entre dos publicaciones adyacentes de una comunidad principal a otra comunidad importante de científicos en diferentes años de carrera. El recuadro muestra la probabilidad de cambio en función del número de artículos publicados en una carrera. c Comparación de la probabilidad de cambio general (todos los científicos) con la probabilidad de cambio del 10% de los científicos más productivos en diferentes años de carrera. Los resultados sugieren que la alta productividad está asociada con una baja probabilidad de cambio en la carrera inicial, pero con una alta probabilidad de cambio en la carrera posterior. d Comparación de la probabilidad de cambio general (todos los científicos) con la probabilidad de cambio del 10% de científicos que tiene la cita media más alta por artículo. Para cada artículo, solo consideramos el número de citas 10 años después de su publicación (c10) 13. Los resultados sugieren que el alto promedio de citas por trabajo en todos los períodos de carrera se correlaciona con una baja probabilidad de cambio. En los recuadros de (c, d), presentamos el valor p de la prueba de Kolmogorov-Smirnov que distingue entre las dos distribuciones de probabilidad de cambio en cada año de carrera
Además preguntamos, ¿aumentar la conmutación ayuda o no al rendimiento de la investigación? Con este fin, investigamos la correlación entre la probabilidad de cambio y el rendimiento de la investigación. Aquí, medimos el rendimiento de la investigación de un científico utilizando dos métricas casi sin correlación (ver la figura complementaria 7), es decir, el número de artículos publicados y la cita media por artículo. De acuerdo con la ref. 13, solo consideramos el número de citas 10 años después de la publicación de un artículo, es decir, c10. Primero comparamos en la figura 3c, la probabilidad de cambio general con la probabilidad de cambio del 10% de los científicos más productivos en diferentes años de carrera. Encontramos sorprendentemente dos comportamientos opuestos. En la etapa inicial de la carrera (<12 años), la alta productividad general se asocia con una baja probabilidad de cambio, pero en la etapa posterior de la carrera, la alta productividad se asocia con una alta probabilidad de cambio. El patrón todavía existe si eliminamos a aquellos con bajas citas de los científicos productivos (ver la figura complementaria 8). Puede haber múltiples razones que conducen a este patrón. Una posible causa de la correlación negativa entre la productividad y la probabilidad de cambio al comienzo de la carrera es que un científico frecuentemente cambia los temas porque el área de investigación no es interesante o es demasiado difícil hacer algo productivo en ella. Además, comparamos en la Fig. 3d, la probabilidad de cambio general con la probabilidad de cambio del 10% de los científicos que tienen la cita media más alta por papel. La figura muestra que el alto promedio de citas por trabajo en todos los períodos de carrera está asociado con una baja probabilidad de cambio. Este hallazgo interesante podría deberse al hecho de que una mayor probabilidad de cambio reduce la impresión de liderazgo en un campo específico, produciendo menos citas. Este resultado está respaldado por una prueba adicional en la que se encuentra que la probabilidad de cambio está correlacionada negativamente con la cita media por papel, especialmente para los científicos productivos (ver la figura complementaria 9). Para examinar la importancia de estos hallazgos, realizamos la prueba de Kolmogorov-Smirnov de la distribución de probabilidad de cambio en cada año de carrera. El pequeño valor p que se muestra en los recuadros de la Fig. 3c, d (en su mayoría <0.05) sugiere que la probabilidad de cambio general (población total) sigue una distribución distinta de cada uno de los dos subgrupos de científicos (es decir, 10% más productivo y 10% más citado por trabajo) en cada año profesional. También examinamos los resultados de 2% y 5% de científicos con la mayoría de los trabajos más productivos y mejor citados por artículo (ver la Figura 10 complementaria), y controlamos las áreas temáticas de acuerdo con los códigos PACS al calcular los percentiles (ver Figura 11 complementaria). Los patrones observados son consistentes con los presentados en la Fig. 3c, d. Además, calculamos la correlación de Pearson entre la probabilidad de cambio de los científicos en diferentes años de carrera y su rendimiento general (productividad o citación media por artículo). Las correlaciones presentadas en la Fig. Suplementaria 12 también respaldan los hallazgos revelados en la Fig. 3c, d.
A continuación, estudiamos cómo evolucionan las propiedades estructurales y dinámicas de los CCN a medida que se desarrolla la ciencia en los últimos 100 años. A medida que nuestros datos terminan en 2010, las carreras de algunos científicos no se completan. Por lo tanto, tenemos que fijar la duración de la carrera de los científicos de diferentes años para garantizar una comparación equitativa entre sus CCN. Específicamente, solo consideramos los primeros años de carrera de los científicos y eliminamos (i) a todos los científicos que aún no alcanzaron sus años de carrera y (ii) aquellos que publicaron menos de 30 artículos en sus primeros años de carrera. En nuestro análisis, presentamos resultados de y = 10, 20, 30. Primero seleccionamos a los científicos que comenzaron sus carreras en un año determinado, y promediamos el número de comunidades principales en las que estos científicos han participado en sus carreras. Mostramos en la Fig. 4a, el número medio de comunidades para los científicos que comenzaron su carrera en diferentes años. Los resultados indican que a medida que la ciencia evoluciona, el número de comunidades principales de científicos individuales se mantiene casi sin cambios. La evolución de otras propiedades estructurales de los CCN se presenta en la figura complementaria 13. Calculamos además la probabilidad de cambio promedio de cada científico a lo largo de su carrera, y en consecuencia calculamos la probabilidad de cambio promedio por año promediando la probabilidad de cambio de todos los científicos que comenzaron su carrera en este año. Los resultados en la figura 4b indican sorprendentemente que, aunque el número de comunidades es estable durante años, los científicos tienden a aumentar el cambio entre comunidades, es decir, temas, durante el siglo pasado. Más específicamente, los científicos en los primeros días tienden a trabajar en un tema durante un período más largo antes de cambiar a otro tema. Por el contrario, los científicos hoy en día tienden a trabajar en múltiples temas casi simultáneamente, lo que resulta en un cambio más frecuente entre comunidades en publicaciones adyacentes. Las barras de error en la Fig. 4b representan desviaciones estándar. Las grandes barras de error en la figura 4a, b se deben a la heterogeneidad de los científicos en la probabilidad de cambio. Para respaldar aún más la tendencia creciente de la probabilidad de cambio, calculamos en la Fig. 14 suplementaria el error estándar de la probabilidad de cambio, que estima la desviación estándar del error en la media muestral con respecto a la media real. Se ha encontrado un pequeño error estándar de la media en la Fig. 14 suplementaria, lo que indica una incertidumbre muy pequeña en estos valores medios.
Figura 4.

Evolución de la tendencia del número de comunidades y probabilidad de cambio como el desarrollo de la ciencia. a El número medio de comunidades de científicos que comenzaron su carrera en diferentes años. b La probabilidad de cambio promedio de los científicos que comenzaron su carrera en diferentes años. Las barras de error aquí representan desviaciones estándar. A medida que nuestros datos finalizan en 2010, no pueden capturar la carrera completa de los científicos que comenzaron sus carreras en los últimos años. Filtramos así a algunos científicos cuando estudiamos la evolución de la ciencia aquí. Solo consideramos los primeros años de carrera de los científicos y eliminamos (i) todos los científicos que aún no alcanzaron sus años de carrera (para una comparación temporal justa), y (ii) aquellos que publicaron menos de 30 artículos en su primera carrera años (para una detección significativa de la comunidad). Los resultados de y = 10,20,30 se presentan en esta figura. A medida que la ciencia evoluciona (durante los años), el número de comunidades principales que tiene cada científico permanece casi sin cambios, mientras que la frecuencia con que los científicos cambian entre comunidades aumenta durante los años. c Distribuciones del número de comunidades (para y = 30) para los científicos que comenzaron su carrera entre 1940 y 1950, y para aquellos que comenzaron su carrera entre 1970 y 1980. El valor p de la prueba de Kolmogorov-Smirnov es 0.961, lo que sugiere Una similitud significativa entre estas dos distribuciones. d Distribuciones de la probabilidad de cambio (para y = 30) de los científicos que comenzaron su carrera entre 1940 y 1950, y de aquellos que comenzaron su carrera entre 1970 y 1980. El valor p de la prueba de Kolmogorov-Smirnov es 2.34 × 10− 8, lo que sugiere una diferencia significativa entre estas dos distribuciones (es decir, aumento de la probabilidad de cambio)
Luego probamos la importancia de nuestras tendencias observadas mediante el estudio directo de las distribuciones del número de comunidades y la probabilidad de cambio para dos grupos de científicos. El primer grupo incluye a los científicos que comenzaron sus carreras entre 1950 y 1960, mientras que el segundo grupo contiene los científicos que comenzaron sus carreras entre 1970 y 1980. La Figura 4c muestra que las distribuciones del número de comunidades para estos dos grupos de científicos se superponen en gran medida . Sin embargo, las distribuciones de la probabilidad de cambio para estos dos grupos de científicos en la figura 4d muestran una diferencia significativa. Además, consideramos a los científicos que comenzaron sus carreras en cada 10 años adyacentes, por ejemplo, 1940–1950, 1950–1960, 1960–1970 y 1970–1980. Realizamos la prueba de Kolmogorov-Smirnov de la distribución del número de comunidad de científicos, así como la distribución de la probabilidad de cambio de los científicos. Como se muestra en la Tabla 1 suplementaria, los valores p son todos mayores que 0.2 cuando se compara la distribución del número de comunidad de científicos en diferentes períodos de año, lo que respalda el supuesto de que estos datos siguen distribuciones similares. Sin embargo, los valores p son todos menores que 0.04 cuando se comparan las distribuciones de la probabilidad de cambio de los científicos en diferentes períodos del año, lo que sugiere diferencias significativas entre estas distribuciones.
Para respaldar los hallazgos empíricos anteriores, realizamos varias pruebas adicionales. Primero, para eliminar el efecto de aumentar el número de artículos y científicos durante los años, construimos un modelo nulo en el que conservamos los documentos publicados para cada científico, pero reorganizamos el orden de tiempo de estos documentos. Por lo tanto, las comunidades detectadas en el CCN de cada científico se mantienen sin cambios, mientras que la probabilidad de cambio a lo largo de su carrera se verá alterada. Encontramos que la probabilidad de cambio promedio en este modelo nulo es estable a lo largo de los años (ver Figura 15 suplementaria), lo que sugiere que la tendencia creciente de probabilidad de cambio en datos reales no es causada por el aumento del número de artículos y científicos. En segundo lugar, probamos si nuestros resultados se ven afectados por los efectos de colaboración y en qué medida. Asignamos un impacto en el papel entre los autores en el caso de los documentos de varios autores, utilizando el enfoque de asignación de crédito colectivo36. Filtramos los documentos de un científico, en los cuales la participación crediticia del científico es inferior a un cierto valor. Después de filtrar estos documentos, no encontramos diferencias cualitativas en los patrones de cambio individuales y colectivos resultantes de los científicos (ver la Figura complementaria 16), lo que sugiere que nuestros hallazgos son sólidos para los efectos de coautoría. Además, examinamos los datos de APS utilizando dos métodos adicionales. El primero es un algoritmo de detección de la comunidad llamado Infomap37, que es independiente de la maximización de la modularidad. Elegimos este método porque se ha encontrado que su límite de resolución son órdenes de magnitud más pequeños que la maximización de la modularidad38. El segundo método se basa en los códigos PACS, que son códigos de clasificación archivados aplicados por APS de 1985 a 2015. Elegimos este método porque es completamente independiente de la detección comunitaria. Por lo general, un documento puede tener varios códigos PACS (generalmente 3). Aquí, seleccionamos los primeros cuatro dígitos de los códigos PACS primarios (el primer código PACS en un documento) para identificar el campo (tema) de un documento. Si bien el primer método es aplicable a todos los científicos considerados anteriormente, el segundo método está restringido a los científicos que publicaron su primer artículo en APS después de 1985. Los resultados detallados basados en los códigos Infomap y PACS se resumen, respectivamente, en las Figs complementarias. 21 y 22, que exhiben los mismos patrones que los revelados por la maximización de la modularidad.
El modelo de explotación-exploración
Finalmente, proponemos un modelo que podría ayudar a comprender los principales mecanismos que conducen a los patrones observados de la dinámica de investigación de los científicos. Las actividades de investigación de los científicos pueden modelarse como un proceso de descubrimiento en el espacio de conocimiento (es decir, una red que caracteriza las conexiones entre diferentes conocimientos) 4,39. Cuando un científico publica un artículo, activa un nodo (es decir, un nuevo conocimiento) en el espacio de conocimiento. La subred activada por este científico durante su carrera forma una red personal que registra todos sus documentos, así como los enlaces, es decir, las relaciones entre ellos. El modelo más simple para el proceso de activación del nodo es el modelo de caminata aleatoria estándar (RWM), suponiendo que un científico activa aleatoriamente un nodo vecino del antiguo nodo activado. Aquí, proponemos un modelo de explotación-exploración (EEM) mediante la introducción de un proceso de explotación (controlado por una probabilidad p) y un proceso de exploración (controlado por una probabilidad q) al modelo de caminata aleatoria. Se ha señalado que ambos procesos son fundamentales para la innovación en varios sistemas adaptativos40. En nuestro modelo, estos dos procesos se realizan de forma secuencial. En lugar de comenzar siempre desde el último nodo activado en cada paso, el científico tiene la probabilidad p de reiniciar aleatoriamente desde (volver a explotar) uno de los nodos activados previamente. Una vez que se determina el nodo reexplotado, el científico tiene la probabilidad q de explorar nodos más allá de los vecinos más cercanos (un vecino más cercano por simplicidad). Tenga en cuenta que la EEM se reduce a la RWM cuando p = 0 y q = 0. Para una demostración ilustrativa de la RWM y la EEM, consulte la Fig. 5a. En nuestra simulación, el espacio de conocimiento se representa como una red que consta de todos los documentos APS, con dos nodos (documentos) vinculados si comparten al menos una referencia. El primer nodo activado para cada científico está configurado para ser su primer artículo. El resto de los documentos de cada científico se generan siguiendo el EEM en la red APS hasta que el número de nodos activados sea igual al número real de documentos de cada científico.
Figura 5.

Desempeño del modelo de explotación-exploración (EEM). Una ilustración del EEM. La actividad de investigación se modela como un proceso de activación de nodos en el espacio de conocimiento. Cuando un científico publica un artículo, activa un nodo (es decir, un nuevo conocimiento) en el espacio de conocimiento. La red activada por este científico al final forma su red personal registrando todos sus documentos y las relaciones entre ellos. La red de juguetes subyacente es una demostración del espacio de conocimiento, y los nodos rojos son los nodos ya activados por un científico, con un número que registra el paso en el que se activa el nodo. El modelo más simple para el proceso de activación del nodo es la caminata aleatoria estándar, suponiendo que un científico activa aleatoriamente un nodo vecino del último nodo activado. Por lo tanto, uno de los nodos vecinos (marcado en verde con un tamaño más grande) del nodo rojo 4 se seleccionará y activará aleatoriamente. En el EEM, presentamos un proceso de explotación y un proceso de exploración. Con probabilidad p, el científico vuelve a explotar aleatoriamente la vecindad de uno de los nodos activados previamente. En la figura, el científico explota saltando de regreso al nodo rojo 1 y activando aleatoriamente a uno de sus vecinos. Con probabilidad q, el científico explora los nodos más allá de los vecinos más cercanos del nodo 4. Por simplicidad, suponemos que el científico activa aleatoriamente en el paso de exploración al próximo vecino más cercano. b Comparación de las redes de citas compartidas (CCN), así como las series de tiempo de publicación en papel generadas por el modelo de caminata aleatoria y por el EEM. Los parámetros que incluyen el trabajo inicial y el número de trabajos en cada año se establecen de la misma manera que en la Fig. 1. En (c, d), estos parámetros son de todos los autores analizados. c El número de comunidades involucradas anualmente para diferentes p, mientras q = 0. d La distribución del número de comunidades en las que cada científico participa durante su carrera para diferentes q. e, f Estimación de la probabilidad pyq de cada científico basada en los datos reales, graficados como sus funciones de densidad de probabilidad
Primero probamos el EEM simulando la dinámica de investigación del científico representativo altamente citado presentado en la Fig. 1. Específicamente, comparamos en la Fig. 5b la red de citas (CCN), así como la serie temporal de artículos publicados generados por ambos , el RWM y el EEM. Se puede ver de inmediato que la red generada aplicando el RWM es muy diferente de la típica real en la Fig. 1b, ya que contiene muchas cadenas largas y carece de comunidades distintas. Además, la serie temporal obtenida de la RWM también es muy diferente de la de un investigador real típico que se muestra en la figura 1d en el sentido de que no se puede observar el cambio entre comunidades en cada año. Por el contrario, tanto la red como las series de tiempo generadas por el EEM reproducen cualitativamente propiedades similares a las que se muestran en la Fig. 1. Además, respaldamos cuantitativamente el EEM al examinar algunas cantidades estadísticas generadas por este modelo. El primero se refiere al número de comunidades involucradas anualmente bajo diferentes p, como se presenta en la Fig. 5c. Cuando p = 0, cada científico trabaja aproximadamente en una sola comunidad cada año. A medida que aumenta p, el número de comunidades involucradas anualmente aumenta, con p = 0.6 alcanzando un máximo de 1.8, que es el valor observado en datos reales. Aquí, q se establece en 0, ya que tiene poco efecto en las comunidades involucradas anualmente. Otra cantidad estadística es el número de comunidades en las que cada científico participa durante su carrera. Cuando q = 0, la subred generada no tiene comunidades distintas y, por lo tanto, el número de comunidades está muy estrechamente distribuido (incluso para el caso de tamaño> 0 donde todos los grupos detectados se consideran comunidades), como se muestra en la figura 5d. A medida que aumenta q, comienzan a surgir pequeñas comunidades, lo que resulta en la separación de las distribuciones de los casos tamaño> 0, tamaño> 2 y tamaño> 5. Cuando q = 0.2, las distribuciones de tamaño> 0, tamaño> 2 y tamaño> 5 casos, respectivamente, alcanzan su punto máximo alrededor de 11, 8 y 5, similar al de los datos reales, ver Fig. 2c. Aquí, el otro parámetro p se establece en 0, ya que tiene poco efecto en la distribución de los números de la comunidad. Además, estimamos la probabilidad pyq para cada científico con base en datos reales (vea la sección Métodos). Las distribuciones de la p y q estimada a partir de datos reales se muestran en la Fig. 5e, f, respectivamente. Se puede ver que las distribuciones de p y q alcanzan picos alrededor de 0.6 y 0.2, respectivamente, que son los valores en la Fig. 5c, d que generan propiedades estadísticas consistentes con datos reales.
Finalmente, estudiamos en la Fig. 6 otras estadísticas estructurales de los CCN de los científicos generados basados en el EEM con los parámetros p = 0.6 y q = 0.2. A pesar de algunas diferencias cuantitativas, encontramos que estas cantidades estructurales medidas en la Fig. 2 son cualitativamente similares en los datos reales y los datos del modelo. En particular, los CCN generados por EEM están bien conectados y tienen una estructura comunitaria, con documentos en una comunidad que comparten los mismos códigos PACS. También se encuentra una gran heterogeneidad de tamaño entre las comunidades, lo que indica que los científicos se involucran desproporcionadamente en diferentes temas. Estos resultados son realmente predecibles a partir del mecanismo de EEM. Modelamos las actividades de investigación de los científicos como un proceso de descubrimiento en el espacio de conocimiento que se representa como la red de citas de todos los documentos de APS. La red subyacente ya tiene una estructura comunitaria con un tamaño heterogéneo y una representación significativa de los temas. La subred muestreada por el EEM de esta red completa tendrá naturalmente estas propiedades. La principal contribución del EEM es que captura los mecanismos principales (es decir, reinicio y salto de longitud) que conducen al comportamiento de cambio de tema observado en datos reales, incluida la alta probabilidad de cambio (cambio a temas antiguos), así como pequeños aislados comunidades (cambiando a temas muy diferentes).
Figura 6.

Propiedades estructurales de los CCN de los científicos generados basados en el EEM. a El tamaño de la red modelada de co-cita (CCN) versus el tamaño del componente gigante (GC) de CCN. Cada punto representa un científico modelado. b La modularidad maximizada en los CCN modelados (Qmodel) y la modularidad maximizada en sus contrapartes reorganizadas conservadas en grado (Qrand). c El coeficiente de Gini de la distribución de códigos PACS en diferentes comunidades. Las comunidades se clasifican por tamaño en orden descendente. Los datos del modelo se comparan con una contraparte aleatoria, donde se reorganizan los códigos PACS. d La fracción de documentos en diferentes comunidades de datos reales y datos modelo. e La probabilidad acumulada inversa de fracción de nodos en las tres comunidades más grandes para datos reales y datos de modelo. f La distribución del grado máximo en CCN reales de los científicos y CCN modelados. En esta figura, los parámetros de EEM se eligen como p = 0.6 y q = 0.2, y las barras de error representan desviaciones estándar
Discusión
Para resumir, estudiamos la dinámica de investigación de los científicos mediante la construcción de una red de publicaciones de cada científico individual que caracteriza sus relaciones de co-cita. Encontramos que típicamente cada red parece tener una estructura comunitaria clara. Los documentos en una comunidad tienden a compartir el mismo código PACS, lo que indica que cada comunidad representa un área de investigación. Al filtrar las pequeñas comunidades de <3 nodos, obtenemos las principales comunidades de científicos. Encontramos que el número de comunidades importantes de científicos está distribuido de manera limitada. Además, las tres comunidades más grandes ya comprenden más del 70% de los documentos de un científico. Comparamos las propiedades estadísticas de los CCN de los científicos que comenzaron su carrera en diferentes años. Encontramos que aunque el número total de comunidades se mantiene casi sin cambios, el cambio entre comunidades tiende a aumentar y se vuelve más frecuente durante los años. Además, encontramos que el alto promedio de citas por trabajo en todas las etapas de la carrera se correlaciona con una baja probabilidad de cambio. En marcado contraste, la alta probabilidad de cambio en la primera carrera se correlaciona con una baja productividad general, mientras que la alta probabilidad de cambio en la última carrera se asocia con una alta productividad general. Finalmente, proponemos un modelo que capture las características principales de la dinámica de investigación de los científicos individuales.
Entre la literatura existente, ref. 26 dieron un paso importante hacia la comprensión de los patrones macroscópicos que subyacen a la evolución del interés de la investigación a lo largo de las carreras de los científicos. El hallazgo clave en la ref. 26 es que la distancia de interés de la investigación medida en base a los códigos PACS entre la primera y la última etapa de la carrera de los científicos sigue una distribución exponencial. Se propuso un modelo de paseo marítimo para reproducir esta observación empírica. Algunos de nuestros hallazgos empíricos son consistentes con los presentados en la ref. 26. Sin embargo, como el análisis en la ref. 26 se centra en el cambio general de los intereses de investigación sobre las carreras completas de los científicos, aún se sabe muy poco sobre la dinámica microscópica del cambio de tema de poco tiempo (papel por papel) dentro de la carrera individual. Las principales contribuciones de nuestro trabajo son (i) proponer una metodología general basada en el método de detección comunitaria para analizar esta dinámica de cambio de tema microscópico, (ii) revelar empíricamente las tendencias de evolución de esta dinámica microscópica en las carreras de los científicos en los últimos 100 años año de desarrollo de la física, y (iii) modelar el dramático comportamiento de cambio de tema en esta dinámica microscópica.
Uno de los principales hallazgos en este documento es que el cambio frecuente de temas al principio de la carrera puede ser adverso al éxito de la carrera de un científico. Por lo tanto, nuestros resultados sugieren que quienes financian y toman decisiones deben alentar a los jóvenes científicos a concentrarse en sus temas actuales. Por ejemplo, se pueden otorgar más subvenciones de seguimiento a jóvenes científicos para estudiar temas que ya han estudiado. Otra posibilidad es introducir una evaluación del desempeño a largo plazo para los jóvenes científicos para que puedan dedicarse más tiempo a un tema. Nuestro trabajo proporciona un marco general para incorporar herramientas de red en el análisis temporal de registros de publicación de individuos. Se pueden construir varias extensiones prometedoras sobre este trabajo. Una sencilla es aplicar nuestro marco para analizar las dinámicas de investigación en el nivel superior (por ejemplo, en departamentos o institutos), lo que profundizará sustancialmente nuestra comprensión de cómo se organizan colectivamente las actividades de investigación. Además, se pueden construir CCN de artículos publicados bajo el apoyo de becas de investigación cooperativas o individuales. Por lo tanto, el resultado de una subvención de investigación puede evaluarse en función no solo de la productividad sino también de las direcciones de investigación reales y la cooperación entre los científicos. Finalmente, observamos que la actividad de investigación es un comportamiento complejo, impulsado por múltiples factores. A pesar de la simplicidad de nuestro modelo, captura muchas propiedades básicas. Sin embargo, observamos que podría capturar características más reales de la investigación científica al incorporar otros mecanismos, como las señales de recompensa o refuerzo después del cambio de tema41.
Datos
En este documento, analizamos los datos de publicación de todas las revistas de APS. Los datos contienen 482.566 artículos, que van desde el año 1893 hasta el año 2010. En aras de la desambiguación del nombre del autor, utilizamos el conjunto de datos del nombre del autor proporcionado por Sinatra et al. que se obtiene con un proceso integral de desambiguación en los datos de APS13. Finalmente, se compara un número total de 236.884 autores distintos. Encontramos y analizamos 3420 autores con al menos 50 artículos y 15,373 autores con al menos 20 artículos. Otro conjunto de datos que analizamos en los Materiales complementarios son los datos informáticos obtenidos al extraer los perfiles de los científicos de las bases de datos web en línea42. Los datos contienen 1.712.433 autores y 2.092.356 artículos, que van desde el año 1948 hasta el año 2014. Los nombres de los autores en estos datos ya están desambigados. Encontramos y analizamos 9818 autores en estos datos con al menos 50 artículos.
Detección de comunidades
La red de co-cita de un científico se construye uniendo dos documentos si comparten al menos una referencia. Para simplificar, no consideramos los enlaces y solo consideramos la topología de la red. La estructura comunitaria de la red se detecta con el algoritmo de despliegue rápido31, que es un método heurístico basado en la optimización de la modularidad. La función de modularidad considerada en este documento se define como
Q=12m∑i,j[Aij−γkikj2m]δ(ci,cj),
(1)
donde
Aij es un elemento de la matriz de adyacencia de la red de conexión,
ki es el grado del nodo
i, m es el número total de enlaces en la red,
ci es la comunidad a la que está asignado el nodo
i, la función
δ del tipo
δ(
ci,
cj) es 1 si
ci =
cj, y 0 en caso contrario. Las comunidades se obtienen cuando la función Q se maximiza. Tenga en cuenta que γ es un parámetro de resolución en
Q, con
γ = 1 en la función de modularidad estándar. Un
γ más grande resulta en la detección de comunidades pequeñas pero más, mientras que un γ más pequeño produce comunidades más grandes pero menos. Los resultados con
γ ≠ 1 se presentan en los Materiales suplementarios. Aunque la distribución del número de comunidades está influenciada por el parámetro
γ (véase la figura complementaria 19), se muestra que las propiedades dinámicas son casi independientes de la resolución de las comunidades (véase la figura complementaria 20). Por esta razón, consideramos la función de modularidad estándar, es decir,
γ = 1, en este documento.
Estimación de p y q a partir de datos reales.
Podemos estimar la probabilidad pyq en el EMM para cada científico con base en los datos reales. Denotamos el número de artículos publicados por un científico i como ni. En la secuencia de los trabajos de i, si un trabajo no comparte ninguna referencia con ninguno de los trabajos publicados antes, se considera una exploración. Denotamos ui como el número total de tales documentos de i. Entonces qi puede estimarse fácilmente como qi = ui/ni. En la secuencia de los documentos de i, si un documento comparte al menos una referencia con el documento justo antes, se considera como no explotación. Denotamos vi como el número total de tales documentos de i. De esta manera, podemos estimar pi como pi = (ni − ui − vi)/(ni − ui)..