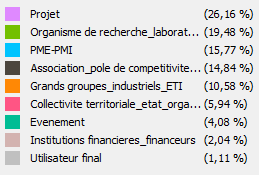
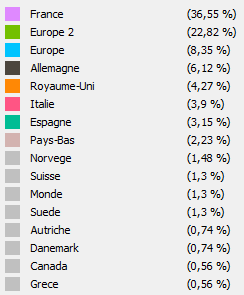
Un estándar para presentar visualizaciones de red.
Mathieu Jacomy |
Reticular

Acabo de asistir a un examen sobre mapeo de controversias en la Universidad de Aalborg, donde, entre otras cosas, los estudiantes interpretaron visualizaciones de Gephi de diferentes tipos (relacionadas con la imagen de arriba). Había redes de páginas de Wikipedia sobre la crianza de los hijos. Los estudiantes fueron bastante buenos a pesar de los problemas comunes sobre cómo hablar de redes. El ejercicio es difícil, y no esperamos que la mayoría de los estudiantes lo dominen en el momento del curso (en este caso, 3 semanas a tiempo completo). Sin embargo, es cierto que, en mi opinión, existe una forma estándar de presentar la visualización de su red. Me di cuenta de que sería útil compartir mi opinión informada sobre cómo presentar su red.
Permítanme primero abordar dos posibles malentendidos.
- No se trata de tu método. Hay infinitas cantidades de diseños de investigación válidos que involucran la visualización de redes. No soy la policía divertida. No voy a discutir cuáles son buenas o malas.
- No se trata de evaluar la calidad del diseño. Ese es un tema muy válido, tengo mucho que decir al respecto y es algo crucial que me viene a la mente al leer algo como "el estándar de oro para la visualización de redes". Sin embargo, no es lo que quiero decir aquí.
Lo que quiero abordar en esta publicación es qué aspectos debe cubrir, en qué orden y, lo que es más importante, cómo debe cubrirlos. Si alguna vez se sintió perdido en un laberinto argumentativo al presentar su red, quédese conmigo.
Pero antes de comenzar a sugerir lo que debe decir y cómo, debo presentar lo que considero las cuatro capas clave de cualquier discurso en una visualización de red. Me tomaré el tiempo de detallarlos, por el momento solo mencionaré su existencia con la imagen de abajo. Si está familiarizado con el trabajo de Bruno Latour, puede reconocer una
cadena de referencia. De lo contrario, comprenderá en el camino: la clave es reconocer las traducciones entre las capas.
Que deberias decir
Asumimos la situación clásica: estás presentando mapas de red hechos por ti mismo. Usted sabe todo lo que hay que saber sobre el proceso, desde la recolección hasta el refinado y la visualización. Tienes alguna experiencia en el tema. Su audiencia comienza con una pregunta muy abierta como "¿Puede decirnos de qué se trata?".
1. Declarar el propósito del trabajo.
Indique el tema primero, sus preguntas de investigación, si tiene alguna, y / o lo que intentó lograr.
Puede ser muy corto pero sigue siendo importante.
Nunca visualizamos una red por el simple hecho de visualizar una red. Siempre hay un motivo subyacente. Interpretar una red nunca es simple y usted y su público corren el riesgo de perderse en el proceso. Indicar hacia dónde te diriges proporciona una ayuda de bienvenida para orientarte.
2. Describe lo que traduce la visualización.
Explique de manera concisa el proceso que ha llevado a la visualización. Es una cadena con muchos pasos que requiere claridad. Use los términos apropiados y haga que cada paso lleve al siguiente explícito.
Hay dos estrategias válidas para narrar esto, dependiendo de la situación:
- Describa el proceso en un orden pseudo cronológico, desde la recolección hasta la visualización.
- Comience con el objeto físico (la hoja impresa, la pantalla ...) y vaya hacia su origen.
Elige lo que te haga sentir cómodo. Es posible que desee aprovechar esta ocasión para explicar el proceso, o lo ha hecho antes y desea ir directo al punto. En ambos casos hay una serie de elementos que debe proporcionar.
Debe explicar los pasos clave del proceso y usar los términos apropiados para hablar sobre cada uno de ellos. Aquí usaré la estrategia número 2, es decir. para narrar los pasos a partir del objeto físico y de ir hacia arriba a través del proceso. Habría variaciones dependiendo de su diseño de investigación, solo asumiré la situación común descrita en la mayoría de los tutoriales de Gephi.
En pocas palabras, cada paso del proceso es una de las cuatro capas que introduje anteriormente. Cada capa está traduciendo la capa justo debajo, y el objetivo es hacer que cada traducción sea explícita.
Describe cómo la imagen traduce la red.
La imagen o mapa es el objeto físico que ofrece empíricamente a su audiencia para comprender su trabajo (junto con sus explicaciones, por supuesto). Debes explicar de dónde viene todo lo visible en la imagen. En un escenario típico esto sería, por ejemplo:
- La imagen ha sido producida mediante la visualización de una red.
- Los círculos están representando los nodos. Todos los nodos han sido representados.
- Las líneas representan los enlaces. Todos los enlaces también han sido representados.
- Los textos son etiquetas de nodos, solo mostramos los más importantes.
- El tamaño de cada círculo representa el grado del nodo.
- El color de cada ronda representa la categoría del nodo.
- El grosor de una línea representa el ponderador del enlace.
- El color de las líneas se ha establecido en un gris claro para evitar el exceso de saturación visual.
- La colocación de los nodos se ha decidido mediante un algoritmo que analiza sus conexiones, sin considerar otros atributos como su categoría.
- La leyenda precisa el código de color de las categorías de nodos y la escala del grosor del enlace.
Explica cómo funciona el diseño
El algoritmo de diseño debe ser explicado. En el caso de
Force Atlas 2 y muchos otros, los puntos importantes son:
- El diseño coloca los nodos solo en función de sus enlaces, ignora todos los atributos.
- Funciona de forma iterativa al hacer que todos los nodos se rechacen entre sí y los nodos conectados se atraigan entre sí. Por diseño converge a un equilibrio que depende de las posiciones de inicio aleatorias.
- La proyección resultante se dice isotópica: no tiene ejes específicos y se puede girar o voltear sin perder sus características. Se supone que se debe interpretar en términos de distancias relativas.
En caso de que se utilicen dichos ajustes, también merecen ser mencionados:
- Gravedad: una fuerza adicional limita la propagación de los nodos, lo que genera un sesgo menor, pero permite optimizar el espacio durante la visualización.
- Prevenga la superposición: la ubicación de los nodos se ha ajustado para que no se superpongan, lo que genera un sesgo menor pero optimiza la legibilidad durante la visualización.
Nota: no creo que valga la pena formalizar una capa adicional, aquí una proyección matemática a un espacio 2D, aunque sea lo que realmente hacemos.
Describe cómo la red traduce los datos de origen.
La red o grafo es la lista de nodos y la lista de enlaces utilizados como una estructura de datos en un software como Gephi. La red se traduce visualmente por la imagen, pero no es la imagen. De manera similar, a menudo traduce datos menos refinados, pero no es esa información.
Debes explicar qué representan los nodos y los enlaces. En otros términos, debe describir cómo se relacionan con los datos sin procesar (ver más abajo). Por ejemplo:
- Los nodos representan palabras mencionadas al menos 10 veces, excluyendo una lista de palabras de parada (stop words).
- Los enlaces representan co-ocurrencia, es decir, cuando aparecen dos palabras en el mismo documento.
- El peso de los enlaces representa en cuántos documentos aparecen las palabras juntas.
Explicar cómo los datos de origen se refieren al mundo empírico.
Debe explicar de dónde provienen los datos de origen y cómo se seleccionaron. La elección de los datos para estudiar a menudo se deriva de un interés en algo preciso en el mundo empírico. Puede ser la paternidad, #blacklivesmatter, diseño nórdico ... Sea cual sea su tema o sus preguntas de investigación, proporcionó un marco interpretativo de los datos de origen, por ejemplo, porque ciertos elementos se utilizan como representantes para obtener información sobre su objeto de interés original.
Podría ser, por ejemplo, mencionar que estaba interesado en un tema relacionado con cuestiones de género, pero por razones prácticas tenía que ser lo suficientemente específico, lo que lo llevó a elegir el tema de la crianza de los hijos que ya se ha descrito en Wikipedia.
3. Interpreta tu mapa de red
Ahora que su audiencia sabe de qué se trata todo esto, puede analizar el contenido de su mapa de red. Su interpretación consistirá en una serie de afirmaciones que se basarán primero en la imagen y atravesarán las capas hasta el mundo empírico, si es posible.
Hay muchas formas de organizar tu interpretación. Puede consultar las sugerencias que Tommaso Venturini, Debora Pereira y yo hemos propuesto para el análisis visual de la red. No abriré esa discusión aquí. Lo único importante es la esencia de cualquier argumento de ese tipo: expone las características de la red que son visibles en la imagen y argumenta que estas características se originan en los datos de origen de una manera que permite decir algo sobre el mundo empírico. Este camino interpretativo es largo, lo sé. Lamentablemente, tal es la situación a la que te enfrentas. La ciencia es dura.
Siempre debe ser claro acerca de las traducciones cuando hace sus puntos. Este es el único truco. Ten éxito en esto, y dominarás la interpretación de la red. Hacer un buen punto tiene que ver con encontrar su camino a través de las capas. Aunque es difícil. Dedicaré el resto de este post a desglosar esa pregunta.
Como deberias decirlo
Pon atención al vocabulario.
El pan y la mantequilla de tus argumentos son las conexiones lógicas entre los muchos elementos que convocarás. Hay tanto que decir que ni siquiera lo intentaré. Sin embargo, siempre comienza con el uso del vocabulario adecuado. Esta pregunta es crítica aquí porque, como veremos, usar los términos apropiados es su mejor defensa contra las líneas argumentativas traicioneras que lo llevarán a un laberinto de falacias.
Cada capa tiene su vocabulario específico, comencemos revisando esto.
Imagen / mapa
El siguiente vocabulario es apto para describir la imagen:
- Círculo, forma, línea, texto
- Colores, claros, oscuros.
- Gran pequeño
- Cerca, lejos
- Ocupado / denso / lleno / áreas ocupadas, agujeros, espacios en blanco
- Centro, periferia (de la imagen, de una zona…).
NO LO USE para describir la imagen en sí: nodo, enlace, hipervínculo, página web ...
Red / grafo
El siguiente vocabulario es apto para describir la red:
- Nodo, vértice
- Arista, enlace, conexión
- Peso del nodo / enlace, atributo, modalidad de un atributo
- Grado, grado, grado superior, métricas de centralidad
- Densidad (de un conjunto de nodos)
- Vecinos, hojas (nodos con 1 vecino), huérfanos (0 vecinos)
- Equivalencia estructural (tener los mismos vecinos)
- Distancia geodésica (longitud del camino más corto)
- Clusters (como el resultado de un algoritmo de clustering)
- Modularidad (de un clustering)
- ...
NO LO USE para describir la red: estar cerca o lejos, estar agrupado ...
A menudo querrá hacer conteos simples, como decir que un conjunto de nodos es grande, pequeño o mayor que ... Un conjunto de nodos puede ser un clúster, nodos donde el atributo X toma la modalidad Y, nodos de un grado de X o Más, vecinos de X ...
Fuente de datos
Este paso no siempre es solo un paso en el proceso y puede tomar muchas formas. El punto importante es que los datos siempre se han transformado: se han limpiado, filtrado, refinado ... Hay tantas posibilidades que no puedo ofrecer una visión general. Voy a elegir algunos ejemplos.
Si sus datos en bruto son páginas de Wikipedia, se aplica el siguiente vocabulario:
- página web
- Hipervínculo, enlace de hipertexto
- En enlaces de texto, ver también enlaces.
- ...
Si sus datos en bruto eran un conjunto de documentos en un análisis de co-ocurrencia:
- Documento de texto
- Párrafo, expresión, n-grama, palabra
- Co-ocurrencia
- Frecuencia de término
- ...
Sus datos pueden provenir de una base de datos de patentes, de Twitter o Facebook, de una fuente cualitativa ... Cada uno de estos casos tiene sus propios tipos de objetos, relaciones y vocabulario.
NO LO USE para describir los datos en bruto: nodo, enlace, estar conectado, estar cerca, estar agrupado ...
Mundo empírico
El vocabulario que utiliza cuando se refiere al mundo empírico puede ser:
- Personas, instituciones, actores,…
- Libros, proyectos, ideas,…
- Temas, ámbitos académicos, intereses,…
- Amistad, apuntes, afinidades, ...
- Grupos de pueblos, comunidad, cultura,…
- Notoriedad, influencia, autoridad, relevancia, ...
Cuidado con las metonimias
En la práctica, usted quiere decir "el tamaño de los nodos" y no "el tamaño de las rondas". Bien, pero estás jugando con fuego. Si dominas el ejercicio, puedes usar todo tipo de atajos porque conoces los límites. Un oyente ingenuo puede tener la impresión de que la mayoría de los conceptos son intercambiables y que puede decir indistintamente línea, enlace, lazo o hipervínculo. Está muy mal. Los problemas son reales y puede que te engañes con argumentos falaces y con lógica circular.
 "Esto no es un pipa"... Sea claro sobre lo que representa y lo que se representa
"Esto no es un pipa"... Sea claro sobre lo que representa y lo que se representa
La línea para no cruzar se aclara al ver cómo entendemos una metonimia, una forma de hablar en la que nos referimos a algo utilizando un concepto diferente pero estrechamente relacionado. Por ejemplo, "jurar lealtad a la corona" se refiere al soberano y no al objeto físico, por supuesto. Podemos obtener el significado correcto porque no tendría sentido jurar lealtad a una corona literal. El contexto indica si la palabra es metafórica o literal, si hay una metonimia o no. Lo mismo se aplica a nuestros conceptos. En la medida en que los nodos no tienen un tamaño (son entidades de red abstractas), está claro que los "tamaños de nodo" se refieren a "el tamaño de las formas que representan los nodos". En ese sentido, el acceso directo es válido, pero sigue siendo complicado porque usamos la palabra nodo para referirnos a las formas, y este cambio peligroso es la forma en que ocurren los accidentes. La línea de no cruzar es cuando las metonimias se vuelven ambiguas.
Cómo te atrapas en el laberinto de la lógica circular
Primero dice "
esos nodos están cerca", que solo puede entenderse como una metonimia para "
aquellas formas que representan nodos están cerca", luego dice "
por lo que forman un grupo" y ya está pisando el límite prohibido. Como profesor, a menudo le pediré que aclare la ambigüedad, por ejemplo: “
¿Puede precisar por qué forman un grupo?”. Ya que conoce el proceso, comprende que la colocación de nodos se debe al algoritmo de diseño, que es de hecho lo que espero. Sin embargo, en este punto, la confusión puede hacer que te adentres en el laberinto de la lógica circular, al responder algo como: "Es un grupo porque el algoritmo de diseño coloca los nodos cerca uno del otro". Bien podría explicar cómo funciona el algoritmo, pero no importa, ya es demasiado tarde. Te has atrapado en una falacia, ¿puedes ver por qué?
El argumento es circular porque establece que los nodos cerrados hacen que los clústeres y los clústeres hagan los nodos cercanos. Desafortunadamente, ser consciente de la circularidad realmente no ayuda. Por mi experiencia, sé que solo te das cuenta de que estás perdido cuando ya es demasiado tarde, si es que alguna vez lo haces. Evitar la falacia no se trata de reconocer la zona prohibida, se trata de no entrar en el laberinto. Se trata de tener una práctica que nunca te ponga en riesgo.
¿Cuál es la práctica segura? En primer lugar, es utilizar el vocabulario adecuado. Pero no puedo ganar la lucha contra la naturaleza humana y hacer que dejes de usar atajos. Así que la práctica segura es sobre el uso de protecciones. Siempre revise la capa donde su argumento es válido. La entrada al laberinto de la lógica circular es donde las metonimias confusas dan lugar a argumentos con desajuste de capas. Pero el desajuste de capas también puede llevar a formas menos dramáticas de malos argumentos que pueden ser muy perjudiciales para usted a pesar de su bajo perfil. Veremos cómo el control de capas ayuda a desacreditarlas.
Malos argumentos
Hay diferentes grados de argumentos erróneos, correspondientes a las diferentes formas en que puede fallar en hacer circular la cadena de referencia de una capa a la siguiente.
Tautología: atrapado en una capa.
El peor tipo de argumento es cuando no hay argumento. Una descripción simple que plantea como un punto. El pintalabios de la retórica sobre el cerdo de la trivialidad. Por ejemplo: "El clúster pro-vida se separa del clúster pro-elección manteniendo una distancia sensible". El argumento es circular: los grupos son distantes porque son distantes. Diagnóstico de este mal argumento como una falla completa para circular fuera de las dos capas superiores, la imagen y la red.

Puede desacreditar dicha declaración comprobando las capas. Hacer un punto implica varios pasos donde las características de una capa están relacionadas con la siguiente. Un argumento apropiado sería algo como esto:
- Los nodos pro-vida y pro-elección aparecen distantes en la imagen.
- Son distantes porque tienen pocas conexiones. Así es como funciona el algoritmo de diseño, pero también podemos ver que hay menos enlaces entre grupos que dentro de cada uno.
- La mayor cantidad de aristas dentro de los grupos muestra que los actores tienden a conectarse con aquellos que son similares a ellos e ignoran a los que son diferentes.
- Este comportamiento revela una oposición entre las dos comunidades.
Naturalización: saltando a conclusiones.
Un tipo de argumento malo pero menos malo es saltar sobre las traducciones, haciendo un punto incompleto. Llamo a esto "naturalización" porque saltar a conclusiones a menudo usa la retórica de la evidencia, como si la visualización fuera una manifestación natural del mundo empírico. Por ejemplo: "los pro-elección se agrupan, mostrando que comparten valores comunes". La conclusión es a veces cierta, pero la argumentación es pobre. Como profesor, me preguntaría de inmediato: "¿puede explicar por qué cree que un grupo de nodos implica compartir valores comunes?", Lo que le brinda la oportunidad de mostrar su capacidad para circular entre las capas o hacer que se dé cuenta de que está perdido. En el laberinto de la argumentación. Algunos estudiantes simplemente usan atajos, y cuando se les pide que descompriman su razonamiento, pueden hacerlo.
Una vez más, la práctica segura es verificar las capas involucradas. En este ejemplo, la proximidad pertenece a la capa de imagen (número 1). Compartir valores comunes pertenece al mundo empírico (número 4). Debes avanzar de capa en capa sin saltar sobre ninguna. Respetar el vocabulario ayuda a no confundir las capas:
- La proximidad de la pro-elección en la visualización ...
- ... proviene de la importante cantidad de enlaces entre los nodos ...
- ... lo que revela que estos actores se conocen y se vinculan entre sí en la web.
- Nuestra hipótesis es que podría ser porque comparten valores comunes.
En este ejemplo, el último punto no es muy convincente, y probablemente es simplemente falso. El formulario es válido pero no el contenido. Eso fue solo un ejemplo, pero sigue siendo cierto que la última traducción, desde los datos de origen al mundo empírico, es la más difícil. Desafortunadamente, también es el más importante.
Correr la ultima milla
Mi último consejo es correr siempre la última milla: sus argumentos deben llevar a conclusiones sobre el mundo empírico, aunque solo sea de manera hipotética. La razón por la que analiza los datos es porque quiere entender algo sobre el mundo y debe demostrar su capacidad para hacerlo.
No correr la última milla es el escollo más trágico porque solo le sucede a los buenos estudiantes, aquellos que llegaron lejos pero no pudieron derrotar al último jefe. La mala argumentación no lo lleva a la última milla, pero puede tener todos sus argumentos válidos y aun así no alcanzar la línea final.
No correr la última milla produce declaraciones analíticamente válidas pero solo sobre los datos. Por ejemplo, no mencionando la argumentación sino solo la conclusión:
- … Por lo tanto, los sitios web gubernamentales ocupan los puestos centrales en el corpus de las ONG.
- … Todas las ONG se citan en la web, excepto las asociaciones humanitarias.
- ... los sitios web de la izquierda radical están bien conectados dentro de la esfera web de la izquierda, pero no forman un grupo, al estar mal conectados entre sí.
Esas afirmaciones pueden ser técnicamente válidas, no explican bien cómo se relaciona con el mundo empírico. El tipo de argumento que espero va un poco más allá, aunque solo sea en forma de hipótesis, por ejemplo:
- ... posiblemente porque muchas ONG dependen de la financiación gubernamental, que a menudo requiere vincularse con las instituciones de financiación.
- ... porque las asociaciones humanitarias compiten por las donaciones, lo que puede llevarlas a no citar a sus competidores.
- ... a pesar de estar reunidos bajo la etiqueta común de "izquierda radical", estos actores no se reconocen entre sí y no forman una comunidad, posiblemente debido a divergencias ideológicas.

 .
.

 es
es  si k es impar y
si k es impar y  si k es par. Estos límites generalizan el teorema de Turán sobre el número de bordes en un gráfico sin triángulos, y son los mejores límites posibles para este problema, ya que para un número menor de bordes existen gráficos que no contienen k-fan.
si k es par. Estos límites generalizan el teorema de Turán sobre el número de bordes en un gráfico sin triángulos, y son los mejores límites posibles para este problema, ya que para un número menor de bordes existen gráficos que no contienen k-fan.