El grafo: una parte del "dataviz" explotable para mapear y explorar un sector de actividad
Mathieu BOYER | Cell'IE
"Un buen boceto es mejor que un discurso largo", Napoleón Bonaparte.
En la era de "Big Data" y "Open Data", estas bases de datos masivas presentadas en forma de tabla, se ha vuelto esencial para aplicar consultas, procesos y dispositivos de cálculo para extraer información relevante y nuevos conocimientos. De hecho, sin estas diferentes etapas, es imposible extraer cualquier valor agregado de estas tablas de valores, imponente y nebuloso.
Es entonces cuando tiene lugar la visualización de datos o "dataviz", lo que hace posible traducir una base de datos no digerible e indigestible en una serie de grafos o imágenes interpretables. Finalmente, es un pasaje "de complejidad a simplicidad" que ocurre cuando organizamos los datos en forma gráfica. Esta disciplina no es nueva y se utiliza en varios campos de actividad: inteligencia económica, geografía, marketing, periodismo, inteligencia, comunicación ... Existen cuatro formas de modelos visuales: gráficos cartesianos, cartografía, diagramas de redes. y modelos experimentales. Deseamos abordar aquí una imagen específica de la visualización de datos que se entrega al lector: el grafo.
El propósito de este artículo es visualizar en forma de grafos, la red formada por los enlaces de hipertexto de sitios alrededor de un tema: el sector del hidrógeno en Francia y en Europa. Nuestro objetivo será mapear el paisaje sectorial del hidrógeno para determinar qué actores forman parte de él. Este tema se toma como ejemplo y el enfoque es replicable para otros sectores de actividad.
Un punto metodológico sobre la construcción de un grafo.
Para entender completamente de qué estamos hablando, es importante volver sobre lo que es una grafo y algunos conceptos que extraen información relevante de ella. Puede ir directamente a la parte de explotación del grafo si ya conoce los principios generales.Un grafo es un conjunto de nodos interconectados y enlaces entre ellos. Aplicados a la web, los nodos representan un sitio web, un actor (tomamos la sociología de la traducción, o teoría de actores de red, en la definición que tenemos de un actor), es decir, un proyecto, una empresa, una asociación, una agencia estatal, una unión ... Los arcos entre los nodos representan los enlaces de hipertexto presentes en los sitios web que rastreamos y que se refieren a otra entidad web del corpus (ellos son sitios web de la red).
La metodología del mapeo web es relativamente simple. Se puede resumir en cinco pasos principales: extracción, procesamiento, análisis, producción y presentación.
Aquí hay algunos elementos para entender la construcción de nuestros grafos.
La elección del crawler
Es necesario elegir un crawler o rastreador al hacer un mapa de la web. Elegimos utilizar Hyphe, una herramienta gratuita desarrollada por Science Po Medialab. Esta opción es la más relevante en nuestra opinión porque es una herramienta gratuita que, a diferencia de otros rastreadores del mismo tipo, ofrece un margen muy grande de Maniobra al usuario. Además, la herramienta tiene características interesantes como agregar etiquetas a sitios o convertir a archivos .xls o .gexf. Sin embargo, tenga en cuenta que se necesitan algunas horas para que Hyphe se apropie completamente Comprender los mecanismos latentes.Puntos de entrada
El tema tratado con las geográficas: Francia y Europa. Enthesi es necesario dejar dos web sites (puntos de inicio del rastreo): Afhypac y el sitio de FCH JU. El primer sitio es una asociación de referencia en Francia para el sector del hidrógeno. Restaura a los miembros que son sus principales actores del sector del hexágono. FCH JU es una organización europea que financia proyectos europeos de colaboración en torno al hidrógeno. La idea es la de la página "Miembros" de Afhypac para obtener todos los actores principales (su sitio web). En cumplimiento de la FCH JU, la página "Proyecto" incluye todos los proyectos que han sido financiados por la organización desde 2008. Además, hace referencia a los miembros de los diferentes consorcios. Estos vuelven a sitios sus puntos de partida de la cartografía. El rastreador se ha lanzado para aspirar a los bucles de hipertexto de estos sitios.Recuperar eso, mar y sector de actividad, existen asociaciones, grupos de profesionales, gremios, etc. que tienen un espacio miembro. Estos espacios son muy buenos puntos de partida para captar un sector de actividad que desconocemos o muy poco (el uso de una consulta simple que combina los operadores booleanos en un motor de búsqueda permite encontrar estos actores). También hay que tener en cuenta que para iniciar un rastreo, es necesario definir para cada sitio una página de inicio. Es recomendable iniciar páginas socios / miembros / miembro / etc. donde sea posible
Tratamiento post-rastreo
Uniendo que la herramienta finaliza el primer rastreo, es necesario tratar como lo que Hyphe denomina "la salida", es decir, los nuevos sitios descubiertos. Este tratamiento implica la eliminación de los sitios que pertenecen a la llamada "alta" de la Web (la capa más visible). De este modo, podemos eliminar los sitios web como Amazon, Twitter, YouTube, Apple, Facebook ... De hecho, estas entidades, se han expandido en popularidad, se concentran una gran cantidad de abrazos y se convertirán en nodos centrales de nuestra cartografía. que No tienen nada que ver con el sector del hidrógeno francés o europeo. Solo se complicarían la comprensión del grafo. En general, si hay una tendencia a sufrir cuando se rastrea un conjunto de sitios. Será necesario asegurar sistemáticamente la eliminación de aquellos que no correspondan al tema observado.Finalización del corpus
Después de definir los sitios que se inclinarán en el corpus, de reiniciar un Rapeo desnudo, es decir, ver solo va a las estacas recién incluidas. Además, es necesario un centro de formación para eliminar la situación. En total, se realiza muy rastreos para constituir el corpus. El rastreo de la última "salida" obtenida de Hyphe hizo posible completar los temibles abrazos. Después de algunos toques finales de los sitios que serán inclinados, el corpus final contiene 539 nodos y 2.885 entrelazados.Categorización de sitios
El análisis del grafo pasa por una doble categorización de los sitios web presentados en el corpus. Este paso esencial nos permite entender cómo cuidar la web. También disponible, durante la explotación del grafo, divulgar información de otro modo no habría estado disponible. Por lo tanto, hemos optado por clasificar los sitios web según el tipo de actor (categoría 1) y según el país o área geográfica (categoría 2)..| Categoría 1: Tipo de actor | Categoría 2: País o zona geográfica |
| El sitio es un proyecto. En este caso, en su mayoría proyectos europeos para nosotros. | El sitio es un proyecto y no tiene ninguna aplicación exclusivamente francesa y se llamará Europe 2. |
| El sitio es una organización de investigación, laboratorio, universidad, escuela, centro técnico o instituto. | El sitio es un proyecto y tiene una aplicación exclusivamente francesa (France 2 en el grafo). |
| El sitio es una PYME SMI. | Clasificamos como Europa cualquier sitio cuyo objeto no se refiera a una entidad que pertenezca a un país. Ejemplo: El Instituto Eifer, nacido de la colaboración entre EDF y el Instituto Karlsruher de Alemania, se identifica como Europa porque nació de la colaboración de dos países. |
| El sitio de un gran grupo industrial de una ETI. | |
| El sitio representa una institución financiera o un financiero. | |
| El sitio representa una asociación, un grupo de competitividad o un grupo diverso de actores. | Otros tipos de sitios para los cuales un país es claramente identificable serán nombrados como tales. Por ejemplo, la Universidad de Poitiers se llamará Francia. Tenemos varios países que están representados y todos tendrán sus propios colores cuando los vean. |
| El sitio es una comunidad territorial, un estado, una agencia / servicio nacional. | |
| El sitio representa a un usuario final de aplicaciones de hidrógeno. | |
| El sitio destaca un evento específico. |
En general, debemos pensar en la información que queremos obtener cuando construimos su categorización. Optar por una representación por tipo de actor y país proporciona una visión general del sector. Por estas categorizaciones, emerge una visión relevante del paisaje sectorial (ver explotación del grafo).
Sin embargo, también es posible elegir clasificar por posicionamiento en la cadena de valor del sector (fabricante de baterías, integrador, generador de estaciones, investigación ...). Hay muchas posibilidades que deben ser cuidadosamente pensadas y adaptadas a las especificidades de cada sector / análisis.
Visualización del grafo
Para concluir el grafo, ahora es necesario espacializar los nodos y los enlaces, colorearlos, nombrarlos, aplicarles un tamaño ... Por lo tanto, es necesario crear lo que se puede llamar una interfaz de imagen: es el enriquecimiento de los elementos del grafo que depende de un software de visualización. No es necesario abordar aquí la cuestión de la herramienta que define el universo de posibilidades en la visualización y que puede bloquear o hacer dependiente al usuario. Para diseñar la imagen de la interfaz, usar Gephi, un software de código abierto, parece ser la mejor solución. Este, sin embargo, no es muy intuitivo y sigue siendo relativamente complejo. Aquí hay algunos tutoriales que explican muy bien cómo funciona.Los nodos del grafo están coloreados de acuerdo con las categorizaciones, lo que da 2 grafos diferentes. A esto se agrega un tercer grafo cuyo color de nodo depende de las agrupaciones / comunidades detectadas automáticamente por el algoritmo de modularidad (o método MCL). La teoría subyacente no se desarrollará, pero aquí hay un documento para aprender más. El tamaño de los nodos no es uniforme y está relacionado con el peso asignado a ellos. Está vinculado al número de enlaces de hipertexto salientes o entrantes para un nodo determinado (cuanto más se cita un sitio, más imponente estará en el grafo).
Estas modificaciones aplicadas, debemos agregar una espacialización para completar el grafo. Hay varias opciones disponibles que dependen del tipo de grafo y lo que desea analizar. Respecto a las 3 grafos, se aplicó la misma espacialización y se llevó a cabo en 2 etapas:
- Utilizando el algoritmo de Fruchterman Reingold. La salida del grafo final es más interesante cuando este algoritmo se usa de antemano para "airear" el grafo.
- Utilizando Force Atlas 2, un algoritmo "dirigido por la fuerza" que posiciona cada nodo de acuerdo con los demás. Se aplicó una reducción de la dispersión de los nodos, una gravedad para acercar los nodos, una influencia nula de los enlaces y una prevención de la recuperación (más estética y legible) al grafo.
Así nos dimos cuenta de las 3 grafos siguientes.

Grafo 1: Tipo de categorización del actor.
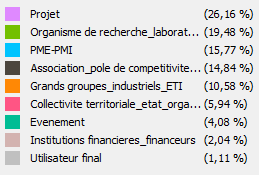
Leyenda del grafo 1

Grafo 2: categorización por país
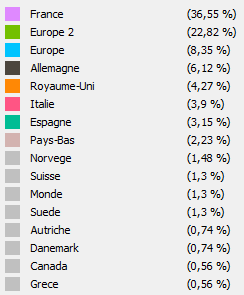
Leyenda del grafo 2

Grafo 3: algoritmo de modularidad de categorización
Explotación del grafo
Un principio básico es latente en un mapa de enlaces de hipertexto. Este es el principio de la homofilia, teorizado por Lazarsfeld y Merton en 1954. Menciona lo siguiente: los individuos tienden a conectarse entre sí según sus similitudes. Así, dos actores estarán más fácilmente en contacto si comparten los mismos valores, la misma cultura, la misma clase social, etc. La cartografía web es una extensión de este razonamiento sociológico. Los enlaces de hipertexto materializan las relaciones sociales y el intercambio del mismo sector de actividad (en este caso) explica la conexión entre estas entidades web.Estas relaciones traducidas por enlaces de hipertexto son proteicas. De hecho, el enlace puede simbolizar una asociación en torno a un proyecto, una relación comercial, una relación accionaria, la pertenencia a una organización, la participación en un evento, etc. Finalmente, es la representación de una conexión que realmente tuvo lugar en algún punto "en tierra". Es sobre la base de este principio que podemos explotar los grafos.
Al analizar el grafo número 1 que clasifica los tipos de estructura, se descubre información sobre la organización del sector y el posicionamiento de los actores:
- Las organizaciones de investigación son numerosas y muy conectadas. Vienen de un grupo (ubicado a la derecha del grafo). La colaboración europea parece manifestarse en torno al sector del hidrógeno y el surgimiento del sector (aún en fase de desarrollo) puede justificar la omnipresencia de estos actores. Sería interesante realizar este trabajo de mapeo en unos pocos años; La sospecha de un hallazgo de una disminución neta puede ser de estos organismos para el beneficio de grandes grupos o de SME-SMI.
- Algunas pymes están mal conectadas. Esto puede explicar el surgimiento del sector y la actividad de las empresas que aún tienen que encontrar su lugar (grupo de sitios alrededor de Afhypac).
- Alrededor de los proyectos europeos (ubicados alrededor del FCH) giran en torno a diferentes organizaciones: SME-SMI, grandes grupos, ETI, asociaciones, organizaciones de investigación ... Después de una breve investigación, esto se explica por los métodos de financiamiento de este tipo de proyecto. De hecho, cuando los diferentes tamaños de estructuras están presentes en un consorcio, la financiación puede ser mayor o más fácilmente aceptada.
- Las organizaciones de financiamiento están fuertemente conectadas y están en el corazón de grupos como ADEME o FCH JU. Esto parece reflejar una necesidad exógena de financiamiento para los actores involucrados en el sector del hidrógeno. Esta idea refuerza un análisis inicial que muestra que este sector está en pleno desarrollo.
Si ahora tomamos la cartografía número 2 clasificando los países, podemos deducir ciertas tendencias:
- Los actores franceses están muy interconectados, pero en su mayor parte están aislados de los actores y proyectos europeos. ¿Es este el signo del retraso en este asunto de Francia en comparación con otros países europeos? Tenga en cuenta que el grafo 3 que colorea los nodos de acuerdo con el algoritmo de modularidad ha identificado muy bien a la comunidad francesa.
- La mitad del grafo (donde la concentración es menor) presenta a los actores franceses que cierran la brecha entre Europa y Francia (ejemplo: CEA, Airliquide, Symbio, Areva H2, McPhy, CNRS entre otros). Por lo tanto, estos jugadores ocupan un lugar importante y estratégico en la escena francesa y europea para el sector del hidrógeno. Estos actores por lo tanto tienen mucho poder. Recuerde que en un mapeo, los actores que hacen el enlace entre 2 o más redes deben considerarse estratégicos. Una empresa tiene mucho interés en acercarse a estos actores si desea estar presente en el panorama del hidrógeno francés y europeo.
Una tendencia importante surge en el grafo número 3:
El clúster europeo alrededor del FCH se puede dividir en 2. Esto es lo que ha presentado el algoritmo de modularidad. Una parte contiene actores más diversos (en verde en el grafo 3) y la otra parte consiste principalmente en proyectos (en púrpura). La parte verde contiene grupos más grandes y ETI, cluster competitivo, SME-SMI (que se superpone con el grafo 1) que puede explicar la división. Por el contrario, el grupo púrpura está fuertemente conectado con las organizaciones de investigación. Sigue siendo bastante complicado explicar esta distinción, pero eso es lo que podemos asumir.
Al estar en la fase de desarrollo, podemos imaginar que se destacan 2 tipos de proyectos:
- Proyectos de aplicación (demostradores);
- Y más proyectos de investigación básica.
Sin embargo, esta división puede hacernos pensar que los proyectos más aplicativos están más fuertemente conectados con el mundo industrial (cluster verde) y, a la inversa, los proyectos más "fundamentales" están en relación con el mundo de la investigación. Si este es el caso, localizar los proyectos de la aplicación se vuelve fácil.
La explotación del grafo también puede ir a través del uso de las métricas inherentes al software de visualización (puntuación de autoridad, centralidad de intermediación ...). Sabemos que la cartografía materializa un conjunto de relaciones sociales. Al combinar esto con métricas matemáticas, podemos obtener otra información. No desarrollaremos el uso de métricas aquí y lo reservaremos para un artículo futuro.
Al analizar completamente los grafos y verificarlos en forma cruzada, es posible dibujar un panorama del sector, sus actores y tendencias, permitiendo que cualquier organización vea con mayor claridad, extraiga información explotable y se abra. pistas estratégicas.
Algunas limitaciones a considerar
Antes de concluir, queríamos advertir al lector de algunas limitaciones en el uso de un mapa web. Éstos son algunos de ellos:
- Ningún grafo es exhaustiva y ninguna muestra una verdad absoluta;
- La web está cambiando rápidamente (cierre de sitios, enlaces muertos, agregando enlaces ...). Es posible que la asignación utilizada aquí ya no sea completamente precisa y cualquier asignación está destinada a evolucionar;
- El vínculo social del que hablamos, transpuesto por el enlace de hipertexto, es construido y complejo. La simple visualización del grafo no permite comprender completamente la profundidad de un enlace. Por lo tanto, es importante hacer una referencia cruzada del mapeo a través de búsquedas de información;
- La web es imperfecta, algunos enlaces y sitios no funcionan, los actores pueden no aparecer y el mapeo puede estar incompleto;
- Nunca se debe sobreinterpretar el grafo y sacar conclusiones precipitadas. Es por eso que preferimos hablar sobre tendencias y por qué abogamos por el aspecto exploratorio del mapeo.
Por lo tanto, es necesario, en nuestra opinión, redoblar la precaución durante un ejercicio como el que acabamos de presentar.
Lo hemos demostrado: el mapeo de enlaces de hipertexto permite observar la dinámica de los actores que pertenecen a un sector determinado. La punta de lanza de este trabajo es el resaltar las principales tendencias en el entorno observado que se pueden movilizar como un ancla. Este mapeo no debe verse como un fin sino como un punto de partida para que una fase de exploración active otros enfoques; Pensamos en particular en el reloj y las estrategias de influencia.
Por ejemplo, considere una empresa que quiere posicionarse en un sector del que sabe muy poco. Este tipo de mapeo podría guiar la selección de socios y relaciones potenciales (con actores autoritarios e influyentes en el sector). También podría identificar fácilmente a las organizaciones que parecen importantes y ponerlas bajo vigilancia para conocer sus direcciones estratégicas.
En resumen, la cartografía es un activo real para una organización. Ahora estamos dando rienda suelta a la imaginación de todos para implementar los pasos adaptados a las necesidades específicas de su estructura utilizando el grafo como soporte.
Fuentes :
- https://www.cairn.info/revue-i2d-information-donnees-et-documents-2015-2-p-38.htm
- https://7bis.files.wordpress.com/2010/08/thoriedesgraphes-091001023741-phpapp011.pdf
- https://www.cairn.info/revue-i2d-information-donnees-et-documents-2015-2-p-38.htm
- https://www.cairn.info/revue-i2d-information-donnees-et-documents-2015-2-p-68.htm
- https://www.cairn.info/revue-i2d-information-donnees-et-documents-2015-2-p-1.htm




















