Data Scientist examina las 6 películas de Star Wars para extraer las redes sociales, dentro de cada película y en todo el universo Star Wars. La estructura de la red revela algunas diferencias sorprendentes entre las películas, y encuentra quién es realmente el carácter central.
Por Evelina Gabasova, U. de Cambridge.
KD Nuggets
Logo de Star WarsAlgunos de nosotros estamos esperando la Navidad, y algunos de nosotros estamos esperando la nueva película en la franquicia de Star Wars, The Force Awakens. Mientras tanto, decidí mirar el ciclo completo de 6 películas desde un punto de vista cuantitativo y extraer las redes sociales de Star Wars, tanto dentro de cada película como en todo el universo Star Wars. Mirar la estructura de la red social revela algunas diferencias sorprendentes entre la trilogía original y las precuelas.
Si está interesado en los detalles técnicos de cómo extraí los datos, diríjase a la sección How I did the analysis. Pero empecemos con algunas visualizaciones.
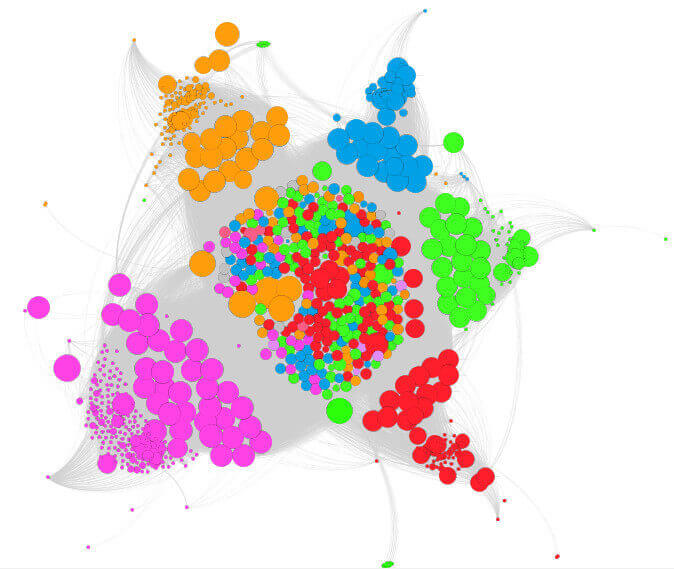
Esta es la red social de las 6 películas combinadas:

Puede abrir la red en una ventana completa que mostrará una visualización interactiva de la red en la que puede arrastrar nodos individuales. Si coloca el cursor sobre los nodos individuales, verá el nombre del carácter correspondiente.
Aquí los nodos representan a los personajes de las películas. Los personajes están conectados por un enlace si ambos hablan en la misma escena. Y cuanto más los personajes hablan juntos, más grueso es el vínculo entre ellos. El tamaño de cada nodo corresponde al número total de escenas en las que aparece el personaje. Hice algunas decisiones discutibles: Anakin y Darth Vader están representados por dos nodos separados, porque esta distinción es importante para la historia. Por otra parte, el nodo Emperador también representa conjuntamente Palpatine y Darth Sidious. También fusioné Amidala con Padme.
La trilogía original (episodios IV, V y VI) de la derecha está mayormente separada en la red de la trilogía prequel a la izquierda porque la mayoría de los personajes aparecen sólo en una de las trilogías. Los nodos cruciales que conectan las dos redes son Obi-Wan Kenobi, R2-D2 y C-3PO. Especialmente los robots parecen jugar una función social importante porque aparecen con frecuencia a través de todas las películas.
Las estructuras de las dos sub-redes son también diferentes. La trilogía original tiene menos nodos importantes (Luke, Han, Leia, Chewbacca, Darth Vader) y están densamente interconectados entre sí. La trilogía prequel tiene más nodos en general, con muchas más conexiones. Voy a ver películas individuales con más detalle más adelante en el post.
Líneas de tiempo del personaje
Muchos de los personajes aparecen en varias películas, por lo que también he creado una comparación de sus líneas de tiempo a través de los episodios individuales. Los siguientes gráficos muestran dónde se mencionan los caracteres individuales en los guiones de película. En orden de aparición, estos son los plazos de algunos de los personajes principales:
Aquí incluí todas las menciones de cada personaje, que incluye otros personajes que discuten su nombre. Es interesante ver cómo Anakin aparece simultáneamente con Darth Vader durante el Episodio III, y luego Darth Vader se hace cargo. Anakin vuelve a aparecer hacia el final del Episodio VI cuando Darth Vader se aleja del lado Oscuro.
Los personajes que aparecen más consistentemente en todas las películas son los mismos que están en el centro de la red social - Obi-Wan, C-3PO y R2-D2. Yoda y el emperador también aparecen en todas las películas, pero no hablan directamente con muchas personas en la trilogía original, lo que les mueve fuera del centro en la red social.
Redes en películas individuales
Ahora veamos las redes en películas individuales. Observe cómo el número de nodos y la complejidad de las redes cambian entre los prequels y las películas originales. De nuevo, aparece un enlace entre caracteres si hablan dentro de la misma escena.
Episodio I: La amenaza fantasma

Episodio II: El ataque de los clones

Episodio III: La venganza de los Sith

Episodio IV: Una nueva esperanza

Episodio V: El Imperio Contraataca

Episodio VI: El retorno del Jedi

Importancia de los caracteres
Las redes individuales muestran nuevamente que la trilogía precuela tiene más caracteres y más interacciones en general. Los episodios originales tienen menos personajes, pero interactúan más entre sí.George Lucas dijo:
Realmente es la historia de la tragedia de Darth Vader, y comienza cuando tiene nueve años, y termina cuando está muerto.
(fuente)
Pero, ¿es Darth Vader / Anakin realmente el personaje central? Vamos a utilizar algunos métodos de análisis de redes para ver quién es realmente importante en las historias y sus estructuras sociales.
Calculé dos medidas de importancia en las redes para cada una de las películas:
- Centralidad de grado - esto es simplemente el número de conexiones que tiene el nodo en la red. En las películas de Star Wars, esto corresponde al número total de escenas en las que cada personaje habla.
- Intermediación - esta medida mira cuántos caminos más cortos en la red conducen a través del nodo. Por ejemplo, imagina que eres Leia y quieres enviar un mensaje a Greedo - el camino más corto para enviarlo es a través de Han Solo, porque interactuó tanto con Leia como con Greedo. Por otro lado, si quieres enviar un mensaje a Luke, no tienes que pasar por Han porque Leia conoce a Luke directamente. La centralidad intermedia para Han se calcula usando el número de caminos más cortos entre todos los otros caracteres que pasan a través de él.
Las dos medidas muestran la importancia de un personaje en la red. La centralidad del grado muestra cuánta gente interactúa cada personaje directamente. El intermedio se refiere más a la forma integral de cada uno de los personajes es a la historia. Los personajes con alta interrelación conectan diferentes áreas de la red social.
Para ambas medidas, los valores más altos significan más importancia. Aquí están los 5 primeros caracteres para cada película:
Episodio I
|
| ||||||||||||||||||||||||||||||||||||
Episodio II
|
|
Episodio III
|
|
Episodio IV
| Nombre | Grado | |
|---|---|---|
| 1. | LUKE | 15 |
| 2. | LEIA | 12 |
| 3. | C-3PO | 10 |
| 4. | CHEWBACCA | 9 |
| 5. | HAN | 8 |
| Nombre | Intermediación | |
|---|---|---|
| 1. | LUKE | 32.7 |
| 2. | LEIA | 19.7 |
| 3. | HAN | 15.0 |
| 4. | C-3PO | 13.2 |
| 5. | CHEWBACCA | 8.0 |
Episodio V
| Nombre | Grado | |
|---|---|---|
| 1. | LUKE | 12 |
| 2. | DARTH VADER | 12 |
| 3. | HAN | 11 |
| 4. | R2-D2 | 11 |
| 5. | C-3PO | 10 |
| Nombre | Intermediación | |
|---|---|---|
| 1. | LUKE | 25.2 |
| 2. | DARTH VADER | 11.3 |
| 3. | LEIA | 9.7 |
| 4. | HAN | 6.7 |
| 5. | R2-D2 | 4.5 |
Episodio VI
| Nombre | Grado | |
|---|---|---|
| 1. | LUKE | 15 |
| 2. | R2-D2 | 12 |
| 3. | C-3PO | 11 |
| 4. | LEIA | 9 |
| 5. | HAN | 9 |
| Nombre | Intermediación | |
|---|---|---|
| 1. | LUKE | 24.3 |
| 2. | C-3PO | 23.0 |
| 3. | DARTH VADER | 18.5 |
| 4. | CHEWBACCA | 16.0 |
| 5. | LANDO | 5.5 |
El análisis de centralidad cuantifica algunas de las cosas que pudimos ver en las redes sociales. La trilogía precuela tiene estructuras sociales más complejas, con más personajes interconectados. Esto también lleva al hecho de que Anakin no es tan central para la historia - algunas de las historias suceden junto con la historia de Anakin, o involucrar a Anakin sólo en el lado. Por otro lado, la trilogía original tiene una estructura más ajustada. Hay un menor número de personajes centrales y vinculan la historia juntos - esto resulta en el acuerdo entre el grado y las medidas de centralidad entremedias.
Quizás esto es parte de la razón por la cual la trilogía original es más popular - las tramas son más consistentes y conducidas por los personajes principales. Las precuelas tienen una estructura más descentralizada y no hay un héroe claro. Aunque las historias están unidas por Anakin, no vincula a los otros personajes.
¿Cómo se ven las medidas cuando miramos la red social completa de todos los episodios juntos? Miré dos variantes de la red. En el primero Anakin y Darth Vader aparecen como dos individuos separados, en el segundo los uní en una sola persona.
Red conjunta 1
Anakin y Darth Vader separados
| Nombre | Grado | |
|---|---|---|
| 1. | ANAKIN | 42 |
| 2. | R2-D2 | 41 |
| 3. | OBI-WAN | 37 |
| 4. | PADME | 34 |
| 5. | C-3PO | 31 |
| Nombre | Intermediación | |
|---|---|---|
| 1. | OBI-WAN | 370.4 |
| 2. | PADME | 237.3 |
| 3. | R2-D2 | 236.7 |
| 4. | C-3PO | 222.9 |
| 5. | LUKE | 194.4 |
Red conjunta 2
Anakin y Darth Vader fusionados| Nombre | Grado | |
|---|---|---|
| 1. | DARTH VADER | 59 |
| 2. | R2-D2 | 41 |
| 3. | OBI-WAN | 37 |
| 4. | PADME | 34 |
| 5. | C-3PO | 31 |
| Nombre | Intermediación | |
|---|---|---|
| 1. | OBI-WAN | 348.7 |
| 2. | C-3PO | 303.1 |
| 3. | DARTH VADER | 241.5 |
| 4. | R2-D2 | 227.6 |
| 5. | PADME | 226.2 |
Cómo hice el análisis
Como esto es parte del calendario F# Advent calendar, usé F# para la mayor parte del análisis. Lo combiné con D3.js para las visualizaciones de redes sociales, y con R para el análisis de centralidad de red. Puedes encontrar todo el código fuente en mi GitHub. Debido a que el código completo resultó ser relativamente largo, aquí sólo veo algunas de las partes más interesantes.
Analizando los guiones
Empecé descargando todos los guiones para las 6 películas de Star Wars. Están disponibles gratuitamente en la The Internet Movie Script Database (IMSDb), por ejemplo aquí está el guión para el episodio IV: The New Hope. Los guiones son sólo en forma de borradores que a veces difieren de las películas reales - las diferencias, sin embargo, no son muy grandes.
El primer paso fue analizar los guiones. Para complicar las cosas, cada uno de ellos utiliza un formato ligeramente diferente. Los guiones estaban en HTML, dentro de las etiquetas <td class = "srctext"> </ td> o dentro de las etiquetas <pre> </ pre>. Para extraer el contenido de cada secuencia de comandos, he utilizado el analizador Html de F # biblioteca de datos que permite el acceso a las etiquetas individuales en un documento HTML utilizando declaraciones como
open FSharp.Data
let url = "http://www.imsdb.com/scripts/Star-Wars-A-New-Hope.html"
HtmlDocument.Load(url).Descendants("pre")
The full code for this part is available in the parseScripts.fs file.
The next step was to extract relevant information from the scripts. In general, a script looks like this:
INT. GANTRY - OUTSIDE CONTROL ROOM - REACTOR SHAFT
Luke moves along the railing and up to the control room.
[...]
LUKE
He told me enough! It was you
who killed him.
VADER
No. I am your father.
Shocked, Luke looks at Vader in utter disbelief.
LUKE
No. No. That's not true!
That's impossible!
Each scene starts with its setting:
INT. (interior) or EXT. (exterior) and the location of the scene. Then there can be some free text describing what is happening and how does the scene look. In the dialogues, the names of characters are written in capital letters (sometimes also in bold), followed by what they are saying.
The main signposts in the screenplay are the
INT. and EXT. statements which serve as scene separators. These were written consistently in bold in all the 6 scripts and I used them to split them into individual scenes:// split the script by scene // each scene starts with either INT. or EXT. let recsplitByScene (script : string[]) scenes = let scenePattern = "<b>[0-9]*(INT.|EXT.)" let idx = onmouseover="showTip(event, 'fs4', 10)" onmouseout="hideTip(event, 'fs4', 10)">script |> Seq.tryFindIndex (fun line -> Regex.Match(line, scenePattern).Success) match idx with | Some i -> let remainingScenes = script.[i+1 ..] let currentScene = script.[0..i-1] splitByScene remainingScenes (currentScene :: scenes) | None -> script :: scenes
This is a recursive function that takes the full screenplay and looks for the specific pattern, which is
EXT. or INT. in bold, optionally preceded by a scene number. The function goes through the string and when it encounters the scene break, it splits the string into the current scene and the remaining text. Then it runs recursively until all the scenes are extracted, using the scenes variable as an accumulator.Getting list of characters
The previous function gave me a list of scenes for each of the movies. Extracting the characters out of them turned out to be more difficult. Some of the scenes followed the format that I showed in the example above, some of the scenes only used character names followed by a colon and their dialogue, all within the same line in the text. The only common property between the different formats was that the names were always written in capital letters.
I resorted to regular expressions, one for each screenplay format:
// Extract names of characters that speak in scenes. // A) Extract names of characters in the format "[name]:" let getFormat1Names text = let matches = Regex.Matches(text, "[/A-Z0-9-]+*:") let names = seq { for m in matches -> m.Value } |> Seq.map (fun name -> name.Trim([|' '; ':'|])) |> Array.ofSeq names // B) Extract names of characters in the format "<b> [name] </b>" let getFormat2Names text = let m = Regex.Match(text, "<b>[]*[/A-Z0-9-]+[]*</b>") if m.Success then let name = m.Value.Replace("<b>","").Replace("</b>","").Trim() [| name |] else [||]
Cada una de las expresiones regulares coincide no sólo con mayúsculas, sino también con números, hypens, espacios y barras. Todo porque los personajes de Star Wars usan nombres como "R2-D2" o incluso "FODE / BEED".
Para extraer realmente la lista de caracteres que aparecen a través de las películas, también tuve que tener en cuenta el hecho de que muchos personajes usan varios nombres. El senador Palpatine se convierte en Darth Sidious y luego en The Emperor, Amidala se disfraza de Padme (o al revés?).
Debido a esto, he creado manualmente un archivo simple aliases.csv donde especificé qué nombres considero que son los mismos. Utilicé éstos como asignación en un nombre único para cada carácter (excepto Anakin y Darth Vader).
let aliasFile = __SOURCE_DIRECTORY__ + "/data/aliases.csv" // Use csv type provider to access the csv file with aliases type Aliases = CsvProvider<aliasFile> /// Dictionary for translating character names between aliases let aliasDict = Aliases.Load(aliasFile).Rows |> Seq.map (fun row -> row.Alias, row.Name) |> dict /// Map character names onto unique set of names let mapName name = if aliasDict.ContainsKey(name) then aliasDict.[name] else name /// Extract character names from the given scene let getCharacterNames (scene: string []) = let names1 = scene |> Seq.collect getFormat1Names let names2 = scene |> Seq.collect getFormat2Names Seq.append names1 names2 |> Seq.map mapName |> Seq.distinct
Now I could finally extract names of characters from the individual scenes! The following function extracts all the names of characters from all the screenplay urls.
let allNames = scriptUrls |> List.map (fun (episode, url) -> let script = getScript url let scriptParts = script.Elements() let mainScript = scriptParts |> Seq.map (fun element -> element.ToString()) |> Seq.toArray // Now every element of the list is a single scene let scenes = splitByScene mainScript [] // Extract names appearing in each scene scenes |> List.map getCharacterNames |> Array.concat ) |> Array.concat |> Seq.countBy id |> Seq.filter (snd >> (<) 1) // filter out characters that speak in only one scene
The only remaining problem was that many of the names were not actual names. The list was full of people called “PILOT” or “OFFICER” or “CAPTAIN”. After this I manually went through the results and filtered out the names that were actual names. This resulted in the characters.csv file.
Interactions between characters
To construct the social networks, I wanted to extract all the occasions when two characters talk to each other. This happens if two characters speak within the same scene (I decided to ignore situations when people talk with each other over a transmitter, and therefore across scenes). Extracting characters that are part of the same dialogue was now similified because I could just look at the list of characters I put together in the previous step.
let characters = File.ReadAllLines(__SOURCE_DIRECTORY__ + "/data/characters.csv") |> Array.append (Seq.append aliasDict.Keys aliasDict.Values |> Array.ofSeq) |> set
Here I created a set of all character names and their aliases to use for lookup and filtering. Then I used it to search through the characters appearing in each scene:
let scenes = splitByScene mainScript [] |> List.rev let namesInScenes = scenes |> List.map getCharacterNames |> List.map (fun names -> names |> Array.filter (fun n -> characters.Contains n))
Then I used the filtered list of characters to define the social network:
// Create weighted network let nodes = namesInScenes |> Seq.collect id |> Seq.countBy id // optional threshold on minimum number of mentions |> Seq.filter (fun (name, count) -> count >= countThreshold) let nodeLookup = nodes |> Seq.map fst |> set let links = namesInScenes |> List.collect (fun names -> [ for i in 0..names.Length - 1 do for j in i+1..names.Length - 1 do let n1 = names.[i] let n2 = names.[j] if nodeLookup.Contains(n1) && nodeLookup.Contains(n2) then // order nodes alphabetically yield min n1 n2, max n1 n2 ]) |> Seq.countBy id
Esto me dio una lista de nodos con el número de veces que hablaron en todo el script, que utilizó para especificar el tamaño de los nodos en las visualizaciones. Entonces creé un enlace para cada vez que dos personajes hablaban dentro de la misma escena, y los contaba para obtener la fuerza de cada relación. Juntos, los nodos y enlaces definieron la red social completa.
Finalmente, exporté los datos al formato JSON. Puedes encontrar todas las redes, tanto globales como individuales, en mi Github.
El código completo para este paso está en el script getInteractions.fsx.
El personaje menciona en el guión
También decidí mirar donde cada uno de los personajes aparece a lo largo del ciclo de seis películas, lo que resulta en el gráfico de líneas de tiempo. Para esto miré todas las veces que el nombre del personaje fue mencionado en los guiones, no limitado al número de veces que el personaje habló. El código para esto era mucho más similar a la extracción de las interacciones en la sección anterior, sólo aquí estaba buscando todas las menciones y no sólo para los diálogos. Para obtener los cronogramas actuales, también mantuve un registro de los números de escena. El fragmento de código siguiente devuelve una lista de números de escena y caracteres que se mencionan en ellos.
let scenes = splitByScene mainScript [] |> List.rev let totalScenes = scenes.Length scenes |> List.mapi (fun sceneIdx scene -> // some names contain typos with lower-case characters let lscene = scene |> Array.map (fun s -> s.ToLower()) characters |> Array.map (fun name -> lscene |> Array.map (fun contents -> if containsName contents name then Some name else None ) |> Array.choose id) |> Array.concat |> Array.map (fun name -> mapName (name.ToUpper())) |> Seq.distinct |> Seq.map (fun name -> sceneIdx, name) |> List.ofSeq) |> List.collect id, totalScenes
Para obtener la línea de tiempo completa, utilicé los números de escena para mapear cada episodio en un intervalo [índice de episodios-1, índice de episodios], dándome una escala relativa de dónde en el episodio apareció el personaje. Los tiempos de escena en intervalos [0,1] son del Episodio I, en [1,2] corresponden al Episodio II, etc.
// extract timelines [0 .. 5] |> List.map (fun episodeIdx -> getSceneAppearances episodeIdx) |> List.mapi (fun episodeIdx (sceneAppearances, total) -> sceneAppearances |> List.map (fun (scene, name) -> float episodeIdx + float scene / float total, name))
Guardé estos datos en un archivo pseudo-csv mal formateado, donde cada fila contiene un nombre de carácter y los tiempos relativos que el carácter apareció a través de las 6 películas, separados por comas.
El código completo está en el archivo getMentions.fsx.
Resumen
Como con la mayoría de las tareas de la ciencia de datos, el paso más difícil aquí era conseguir los datos en una buena forma. Los guiones de Star Wars tenían formatos ligeramente diferentes, así que pasé la mayor parte del tiempo averiguando las propiedades comunes de los documentos HTML para crear una función común para analizarlos y para identificar los nombres de los personajes. Después de eso, fue sólo una pequeña pelea para Wookiee y la igualdad droide cuando decidí combinar fuentes de datos para inferir sus conexiones sociales. Hice las redes extraídas disponibles en JSON en mi GitHub así que usted puede también jugar con ellas.
Enlace
Código fuente: github.com/evelinag/StarWars-social-network
Extracted networks in JSON format: github.com/evelinag/StarWars-social-network/tree/master/networks
Screenplays: imsdb.com