Características de la estructura de correlación de los índices de precios
Xiangyun Gao, Haizhong An y Weiqiong Zhong
 PLoS One
PLoS One. 2013; 8(4): e61091.
Published online 2013 Apr 8. doi:
10.1371/journal.pone.0061091
Resumen
¿Cuáles son las características de la estructura de correlación de los índices de precios? Para responder a esta pregunta, se seleccionaron como datos de muestra 5 tipos de índices de precios, incluyendo 195 índices de precios específicos de 2003 a 2011. Para construir una red ponderada de índices de precios cada índice de precios está representado por un vértice, y una correlación positiva entre dos índices de precios está representada por una arista. Estudiamos las características de la estructura de red ponderada aplicando la teoría económica al análisis de parámetros de red complejos. Se encontró que la frecuencia de los índices de precios sigue una distribución normal contando los grados ponderados de los nodos e identificamos los índices de precios que tienen un impacto importante en la estructura de la red. Encontramos grupos pequeños en la red ponderada por los métodos de k-core y k-plex. Descubrimos huecos de estructura en la red calculando la jerarquía de los nodos. Finalmente, encontramos que la red ponderada de índices de precios tiene un efecto de pequeño mundo calculando el camino más corto. Estos resultados proporcionan una base científica para las políticas de control macroeconómico.
Introducción
Los índices de precios son indicadores importantes para medir la inflación y el desarrollo económico. El gobierno influye en los precios de los productos básicos por una variedad de políticas reguladoras para mantener la estabilidad del mercado. Los índices de precios incluyen el índice de precios al consumidor (IPC) de los residentes, el índice de precios al productor (IPP), el índice de precios al por menor (RPI), el índice de precios de la producción agrícola y del material de producción agrícola y las materias primas, Índice de precios de compra (RFPPI) [1] - [9]. Estos 5 tipos de índices de precios se dividen en muchos índices de precios específicos. Por ejemplo, en China, el IPC se clasifica en ocho categorías: alimentos, tabaco y licor, ropa, equipo y servicios domésticos, productos de salud y personales, transporte y comunicaciones, entretenimiento y productos educativos y servicios y vivienda. Estos 5 tipos de índices de precios se obtienen calculando índices de precios específicos con pesos. Por lo tanto, en comparación con el IPC, PPI, RPI, API y RFPPI, los índices de precios específicos reflejan más directamente los cambios en los precios de los productos básicos. Por esta razón, estudiamos índices de precios específicos en lugar de estos 5 tipos de índices de precios.
Hay relaciones entre los índices de precios que se han encontrado en la investigación anterior. Modelos y métodos de econometría se aplican para probar que hay relaciones causales [4], relaciones de cointegración [5], relaciones interactivas [10] y relaciones de transmisión [11] - [13] entre los 5 índices de precios. Estas relaciones se basan en la correlación entre los índices de precios [14]. Sin embargo, hay muchos índices de precios específicos para cada tipo, entre los que las relaciones desconcertantes forman una red complicada [15] - [17]. En esta red de índices de precios, ¿cuáles índices de precios tienen un mayor impacto? ¿Cómo se afectan entre sí? Cuando uno de ellos cambia, ¿cuáles son los índices de precios que transmitirán el impacto de la fluctuación? ¿Hasta dónde puede llegar el proceso de transmisión y cuál es el camino de transmisión? Debido a que los modelos econométricos tradicionales no pueden incluir tantos índices de precios, si lo hacemos, el modelo será demasiado difícil de usar [14]. Para responder a las 4 preguntas anteriores, primero debemos averiguar las características de la estructura de relación entre los índices de precios. La teoría de la red compleja puede resolver eficazmente los problemas relativos a las características de la estructura de la relación. El concepto central de teoría de red compleja es ver la relación entre las variables en el sistema real como una red compleja, describir la relación entre las variables en el sistema complejo real en forma de red y obtener una mejor comprensión de Su naturaleza analizando la estructura del sistema [18] - [20]. Esta teoría proporciona un enfoque adecuado para analizar cuantitativamente el comportamiento de las redes complejas en el sistema económico, como el fenómeno del mundo pequeño [16], [21]. La diversidad de las relaciones de los individuos está fuertemente correlacionada con el desarrollo económico de las comunidades [22]. Los investigadores han analizado las relaciones de los individuos entre los índices bursátiles basados en la red de correlación. Descubrieron las características de la volatilidad y las existencias dominantes en los índices bursátiles [23], [24], [25]. En el sistema económico, cientos de índices de precios interactúan y se afectan entre sí, y la estructura de correlación forma una red compleja. Así, podemos analizar la estructura de correlación por la teoría de la red compleja.
Materiales y métodos
Materiales
En el presente estudio se recopilaron datos sobre índices de precios específicos de 2003 a 2011 del país en desarrollo China (Anuario Estadístico de China, 2003-2011). Se utilizaron los datos de los cinco tipos de índices de precios siguientes: IPC, RPI, API, PPI y RFPPI. Cada índice de precios se divide en índices de precios específicos, con un total de 195 índices. Los principales elementos de los diversos tipos de índices de precios se muestran en el cuadro 1, por ejemplo, el índice de precios de los alimentos incluye un índice de precios de los alimentos, un índice de precios del petróleo, un índice de precios de carne y aves, Índices de precios.
Tabla 1
Principales elementos de los índices de precios.
| Tipo de índice de precios | | Elementos principales |
| Índice de Precios al Consumidor (CPI) | Alimentos, Tabaco, Licor y Artículos, Vestuario, Instalaciones Domésticas, Artículos y Servicios, Cuidado de la Salud y Artículos Personales, Transporte y Comunicación, Recreación, Educación y Cultura Artículos, Residencia, et al. |
| Índice de precios al por menor (RPI) | Bebidas, Tabaco y Licor, Ropa, Calzado y Sombreros, Textiles, Electrodomésticos, Equipo de Música y Video, Instrumentos Musicales y de Oficina, Artículos de Uso Diario, Artículos de Deportes y Recreación, Plata y Joyería, Medicina Tradicional China y Occidental y Artículos de Salud, Libros, Periódicos, Revistas y Publicaciones Electrónicas, Combustibles, Materiales de Construcción y Ferretería, et al. |
| Índice de precios al productor de bienes manufacturados (PPI) | Industria metalúrgica, industria del petróleo, electrodomésticos, equipo de música y video, industria de fabricación de máquinas, industria de materiales de construcción, industria maderera, industria alimentaria, industria textil, industria de la confección, industria del cuero, industria del papel, Artículos Educativos y Artesanales, et al. |
| Índice de Precios de Productos Agrícolas y Índice de Precios de Material Productivo Agrícola (API) | Fertilizantes Químicos, Fertilizantes Químicos, Plaguicidas y sus Aparatos, Petróleo para Maquinaria Agrícola, Otros Productos de la Ganadería, Productos de la Pesca, Productos Farmacéuticos Medios de Producción Agrícola, Servicio de Producción Agrícola, et al. |
| Índice de precios de compra de materias primas, combustible y energía (RFPPI) | Combustible y energía, Metales ferrosos, Metales no ferrosos, Materias primas químicas, Electrodomésticos, Equipo de música y video, Materiales de construcción, Productos agrícolas, Materiales textiles, et al. |
Redes ponderadas de índices de precios
Para estudiar las características de la estructura de correlación de índices de precios específicos, primero debemos establecer la red ponderada por el índice de precios (
PIWN) por la teoría de redes complejas. Una red es una colección de nodos y enlaces,
N = (
V,
E). Representamos cada índice de precios como un vértice, y representamos la relación entre dos índices de precios como un borde en la red; Por lo tanto, volvimos el estudio de la estructura de correlación de los índices de precios en un estudio de una compleja red de correlaciones de precios.
El conjunto de vértices
V en la red compleja de correlaciones de índices de precios se expresa como

(1)
Donde
vi representa el i-ésimo índice de precios.
El conjunto de nodos
E en la red compleja de correlaciones de índices de precios se expresa como

(2)
Donde
e(i, j) representa la relación entre el i-ésimo índice de precios y el j-ésimo índice de precios.
En el curso de este estudio, se intentó definir y cuantificar la relevancia de la red. Cuantificamos el enla ce
e(i, j) y usamos el coeficiente de correlación
rij para representar el grado de correlación entre el i-ésimo índice de precios y el j-ésimo índice de precios. El coeficiente de correlación, también conocido como el coeficiente de correlación de Pearson, es un indicador que mide el grado de correlación entre las tendencias cambiantes de las variables, con un rango de [-1,1]. Cuanto mayor sea el valor absoluto del coeficiente de correlación, mayor será el grado de correlación entre las variables.

(3)
Donde
im es el valor de la serie temporal del i-ésimo índice de precios, un archivo externo que

es el valor promedio de la serie temporal del i-ésimo índice de precios,
jn es el valor de la serie temporal del índice de precios j-th,

es el valor medio de la serie temporal del índice de precios j-ésimo, y
s es el número de elementos de la serie de índices de precios.
Así, la matriz de coeficientes de correlación del índice de precios
R se forma como
 (4)
(4)
Si todos los coeficientes de correlación se reflejan en la red con pesos, entonces la red está completamente conectada y no está disponible para el análisis de topología. Además, para establecer con mayor exactitud la relación y la estructura entre los índices de precios, debemos eliminar las correlaciones débiles y las no correlaciones estableciendo un umbral. El PIWN es una red basada en umbrales, y como todas las redes basadas en umbral, es muy sensible al valor del umbral. Los bordes cuyo peso sea menor que el valor umbral pueden omitirse [23], [24]. A medida que el umbral aumenta, la red se vuelve más informativa sobre la estructura de correlación parcial del sistema, pero la selección de correlación parcial podría verse afectada por la incertidumbre estadística. No se supone que el valor de umbral sea demasiado bajo. En las redes económicas, el umbral suele establecerse por encima de 0,7 [23], [25].
Las propiedades topológicas y métricas del PIWN dependen fuertemente del valor del coeficiente de correlación
r. Para seleccionar un valor adecuado para
r, iterativamente elegir diferentes valores de este coeficiente de correlación y calcular la suma de los pesos de todos los bordes en el PIWN resultante. Representamos esta cantidad como
E (r).
Para
r = 0,7, tenemos
E (0,7) = 3734. Presentamos la fracción

como una función de
r. Además, realizamos un análisis similar para el tamaño del componente conectado más grande de la red, dependiendo del valor de
r. Se indica el número total de vértices en la mayor componente conectada de la PIWN para un
r dado con
V (r). En la figura 1, mostramos la cantidad

, donde
r = 0,82 es el punto de ruptura. Por lo tanto, elegimos 0,82 como nuestro valor umbral para el tamaño de un gran componente conectado y no trivial topológica y métrica propiedades de la red resultante índice de precios [24]. Si el coeficiente de correlación entre dos índices de precios no es inferior a 0,82, entonces hay una ventaja entre ellos. El valor del coeficiente de correlación entre dos índices de precios se establece como el peso del borde. Así, construimos un modelo de estructura de red compleja y ponderada de fuertes correlaciones de índices de precios, como se muestra en la Figura 2.
Dos medidas de conectividad PIWN en función del parámetro r.
El valor r = 0,82 es la medida utilizada en este trabajo.
 Red compleja de correlaciones fuertes de índices de precios.
Red compleja de correlaciones fuertes de índices de precios.
Los 4 nodos azules son nodos aislados que no tienen una fuerte correlación con otros nodos.

Resultados
Las 4 preguntas sobre el PIWN mencionadas anteriormente son manejadas por el método de análisis paramétrico de red compleja, incluyendo el grado ponderado, k-core, k-plex, la jerarquía de los agujeros estructurales y el camino más corto.
Índices de precios clave
¿Qué índices de precios tienen un mayor impacto? Para responder a esta pregunta, debemos encontrar los índices clave de precios en el PIWN. Los índices clave de precios son los indicadores que tienen un impacto muy alto en el PIWN; Cuanto mayor sea el grado ponderado de un nodo, más amplio será su impacto. En los sistemas económicos, cuanto más amplio es el impacto de un índice, más importante es en la red. Por lo tanto, podemos encontrar índices clave de precios en el PIWN calculando el grado ponderado de los nodos. El grado ponderado de un nodo es la suma de todos los valores ponderados de sus bordes. Esta suma no sólo incluye el número de índices de precios relacionados con el nodo sino que también considera el grado de sus correlaciones. El grado ponderado
WDi de un índice de precios (vértice)
i se define como

(5)
Donde
r es el valor del coeficiente de correlación entre los vértices
i y los vértices
j. En la figura 2, cuanto mayor sea el valor, mayor será el nodo en la red.
Nuestro experimento incluye 191 nodos y 1.795 enlaces en el PIWN. Se calculó el grado ponderado de los 191 nodos, se reflejó a nivel macro, y se encontró que, en toda la estructura de la red de correlación de índices de precios, el grado de influencia del PPI es el más amplio. Así, a nivel macro, PPI es el índice de precios clave. El IPP se refiere al índice de precios al productor en China. En estudios sobre la relación de transmisión de precios en la cadena industrial, muchos estudiosos creen que el PPI puede usarse para representar el nivel de precios en la cadena de transmisión de la industria. En segundo lugar, el grado de influencia del IPC es del 24%, y este índice puede utilizarse en lugar del precio descendente en la cadena de transmisión de la industria. Los resultados muestran que el IBP tiene un mayor impacto en la tasa de inflación que el IPC. Los resultados de otros estudios también apoyan esta conclusión. Utilizando el análisis empírico, el mecanismo de transmisión del precio de producción al precio al consumidor es más importante que el mecanismo de transmisión del precio al consumidor al precio de producción [11]. En general, las fluctuaciones del nivel general de precios aparecen en primer lugar en la zona de producción y, a partir de ahí, se extienden por las cadenas industriales hasta las industrias posteriores y, finalmente, a los bienes de consumo [12]. Por lo tanto, para controlar la tasa de inflación en China, el primero de la cadena industrial se puede considerar en primer lugar. Los resultados también muestran que el grado de influencia de la API es hasta un 15%. China es un país agrícola; Por lo tanto, no debe subestimarse el impacto del nivel de precios de la producción agrícola y su impacto en otras industrias. Especialmente en los países en desarrollo, el aumento de los costos básicos de vida de las personas a menudo tiene una serie de consecuencias, como la reciente "inflación porcina" en China. Tres tipos de índices de precios, el IPP, el IPC y el API, cubren el 80% del grado de influencia. Las estadísticas de la correlación entre los índices de precios macro se muestran en la Tabla 2, y la proporción de cada índice se muestra en la Figura 3.
Proporciones de índices de precios macro con relaciones de correlación.

Tabla 2
Grado ponderado de los índice de precios macro.
| Tipo de índide de precios | Grado ponderado |
| PPI | 1286.29 |
| CPI | 787.21 |
| API | 496.98 |
| RPI | 463.55 |
| RFPPI | 182.89 |
En la Tabla S1, proporcionamos todos los valores del grado ponderado del índice de precios. Hay sólo un pequeño número de índices de precios clave en el PIWN. Sólo 3 índices clave de precios tienen grados de ponderación superiores a 40. En el cuadro 3 se muestra el valor del grado ponderado del índice de precios (top 10). Este cuadro muestra que, en el sistema de índices de precios, sólo unos pocos índices de precios Tienen impactos mayores de 40. Los cambios en estos índices clave de precios darán lugar a fluctuaciones en los otros índices de precios y conducirán a algún fenómeno económico de todo el sistema. Por ejemplo, China es el país más poblado del mundo. El costo de vida del pueblo ocupa un lugar central en su desarrollo económico; Como resultado, las fluctuaciones en la vida cotidiana y la venta al por menor, los índices de precios al consumidor son a menudo la causa de la inflación [26].
Tabla 3
El valor del grado ponderado del índice de precios (top 10).
| Rango | Tipo de índice de precios | Grado ponderado |
| 1 | RPI(Rural Household) | 42.19 |
| 2 | PPI(Articles for Daily Use) | 41.70 |
| 3 | RPI | 40.59 |
| 4 | PPI(Manufacture of General Purpose Machinery) | 39.92 |
| 5 | RPI(Urban Household) | 39.64 |
| 6 | CPI(Rural Household) | 39.14 |
| 7 | PPI(Manufacture of Special Purpose Machinery) | 39.00 |
| 8 | PPI(Manufacture of Artwork and Other Manufacturing) | 38.63 |
| 9 | RPI(Building Materials and Hardware) | 38.58 |
| 10 | PPI(Consumer Goods) | 37.62 |
Encontramos que hay hasta 41 grados ponderados cuyo valor es inferior a 4,8. En la figura 2, los nodos en la parte escasa de la estructura de la red son pequeños, lo que significa que tienen menos impacto en comparación con otros índices de precios y permanecen en estados relativamente independientes. Al analizar los índices de precios con grados ponderados entre 4,8 y 44,8, encontramos que siguen una distribución normal, como se muestra en la Figura 4. Los papeles principales del sistema de índices de precios están ocupados por los índices medios, índices de precios con grados ponderados entre 8,8 y 32,8. Estos resultados pueden usarse como una referencia para decidir las direcciones claves para la regulación de la inflación en China. Sin embargo, en el PIWN general, hay algunos grupos de grupos relativamente independientes y un medio de transmisión entre los índices de precios que deben estudiarse más.
Figura 4
Distribución del índice de precios

Agrupamientos de grupos de precios
¿Cómo se afectan los índices de precios entre ellos? Para responder a esta pregunta, debemos estudiar los grupos de grupo en el PIWN. Los clusters de grupos son sub-redes en las que los índices de precios tienen fuertes correlaciones. En un sistema económico real, muchos índices de precios de los productos básicos interactúan entre sí. Los cambios en un índice de precios tienden a impulsar cambios en otro índice de precios; Existe una relación mutuamente fuerte entre estos índices de precios. Como se observa en la Figura 2, toda la red incluye algunos pequeños grupos de grupos de red, que están en un estado relativamente independiente. Descubrimos que los grupos de índices de precios pueden ayudarnos a comprender las características de la estructura de correlación de los índices de precios y proporcionar mejores referencias para el control de las políticas. El k-plex y el método k-core se basan en el descubrimiento de grados de vértice en subgrupos; Son útiles para identificar pequeños grupos de clusters en la estructura de red del índice de precios. Utilizando el método de descubrimiento de subgrupos, se aprovechan los clústeres de grupos en el índice de precios, lo que puede ayudar al intentar comprender qué otros índices cambian cuando cambia un índice de precios específico.
El método k-plex requiere que cada vértice de los g vértices que están incluidos en un subgrupo mantiene al menos g-k enlaces con otros vértices en el mismo subgrupo, donde k es un coeficiente de ajuste; Cuanto menor sea el valor de k, mayor será el valor de g. Además, cuanto más exigentes sean las condiciones, más estrecha será la relación entre los vértices. El método k-core se refiere a un subgrafo con las siguientes condiciones: los puntos en el subgrafo son al menos adyacentes a k otros puntos en el subgrafo. El método k-plex requiere que, además del punto k, los puntos estén conectados con al menos un punto fuera de los k puntos, mientras que el método k-core requiere que cada punto esté conectado a al menos k puntos.
Primero, use el método k-core para encontrar k-core en el PIWN. Los resultados experimentales muestran que hay 18 grupos de grupos (Figura 5 muestra diferentes colores que representan diferentes k-núcleos). Hay siete grupos con escalas de vértices de no menos de 10 (la escala de vértices representa el número de índices de precios en un grupo de grupos), como se muestra en la Figura 6. Los clusters de grupos más grandes contienen 42 índices de precios. Como se muestra en la Figura 5, hay 3 agrupaciones de grupos grandes en el PIWN, incluyendo el 43% de los índices de precios y el 54% de las correlaciones. Estos grupos de 3 grupos están en posiciones significativas; Cualquier índice de precios en los cambios del grupo de clusters despertará cambios en los otros y dará lugar a cambios en el conjunto. Así, el gobierno podría controlar la fluctuación en los índices de precios mediante una regulación dispersa para mantener la estabilidad de todo el sistema.
Figura 5
El k-núcleo en la estructura de redes de correlación del índice de precios.
La clase de agrupamiento de grupo es mostrado en la Tabla S2.
Figura 6
Un archivo externo que contiene una imagen, ilustración, etc.
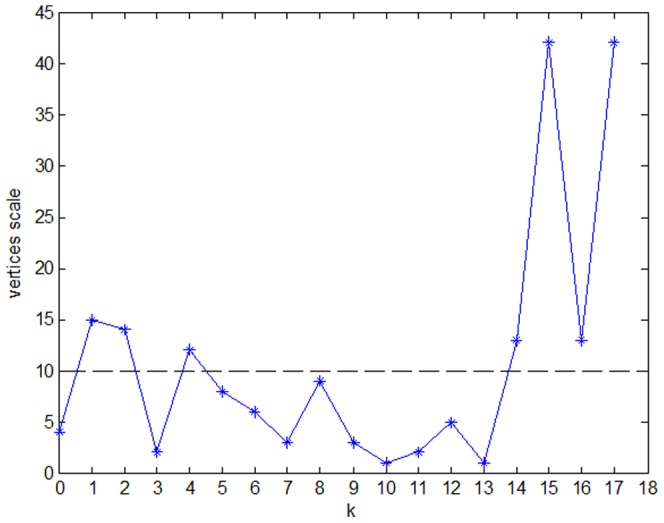 La escala de vértices k-núcleo en la estructura de la red de correlación de índices de precios.
La escala de vértices k-núcleo en la estructura de la red de correlación de índices de precios.
Posteriormente, el método k-plex se utiliza para buscar clusters de grupo en el PIWN bajo las condiciones más exigentes ajustando el valor de k y la escala de vértices. En el experimento, ponemos la escala de vértices a
g = 17 y el coeficiente de ajuste a
k = 2, y solo se encuentran 2 grupos de grupos. Los grupos de 2 grupos son colecciones de índices de precios que tienen las correlaciones más estrechas en toda la estructura de la red, como se muestra en la Figura 7. Los vértices rojos y los vértices azules representan dos grupos de racimos y los vértices negros son los índices comunes de precios para estos dos grupos de grupos . Como se observa en la Figura 7, los índices comunes de precios son todos los índices de precios macroeconómicos que se componen del IPC, el IPR y el API. De los elementos constitutivos de los 2 grupos de grupos, podemos encontrar que, en el PIWN, hay 2 grupos de grupos con estrechas correlaciones; Un grupo comprende los índices de precios de los alimentos y el otro grupo comprende los índices de precios de los bienes de consumo del PPI. Estos dos grupos de clusters tienen fuertes relaciones positivas con los índices de precios macro, lo que significa que es eficaz para China para regular y estabilizar los mercados de precios a través de los alimentos y los índices de precios aguas arriba en la red.
Figura 7
Agrupamientos de grupos de precios.
 g
g = 17,
k = 2.
Medio de transmisión
Cuando cambia uno de los índices de precios, ¿cuáles son los índices de precios que transmitirán el impacto de la fluctuación? Para responder a esta pregunta, debemos analizar el intermediario de cada índice de precios en el PIWN. En los sistemas económicos, la fluctuación de cualquier precio de las materias primas puede causar cambios en los precios de otras materias primas, y esta fluctuación es transitiva. Este efecto de transmisión se basa en las correlaciones entre los precios de los productos básicos. Al igual que controlar la propagación de un virus, no sólo debemos controlar la fuente del virus sino también detener la transmisión eliminando el medio de masa. En un sistema económico, el índice de precios en la estructura de la red actúa no sólo como fuente y receptor del proceso de transmisión sino también como medio. Diferentes índices de precios tienen diferentes niveles de efectos medios. Podríamos controlar la transmisión de fluctuaciones entre índices de precios mediante el control de los medios, para evitar la influencia de todo el sistema.
Para buscar el índice de precios que desempeña el papel de intermediario, debemos analizar la jerarquía de los agujeros estructurales para cada índice de precios en el PIWN. La presencia de agujeros estructurales hace que el índice de precios que ocupa la posición intermedia sea un enlace importante. Los agujeros estructurales controlan en gran medida la transferencia de fluctuaciones en el índice de precios. Al medir el nivel de los agujeros estructurales y calcular la jerarquía de los agujeros estructurales para cada índice de precios en la estructura de la red, una jerarquía más alta significa que el índice de precios es más importante en el proceso de transferencia. La formulación de índices de precios
i en el cálculo de la jerarquía de estructuras de red es

(6)
Donde
N es el número de vértices en la red individual de vértices (índice de precios)
i,
C/
N es el valor medio de la restricción en cada nodo y la restricción de nodos
Cij es el grado en que los nodos de la red tienen la capacidad de uso de huecos estructurales. La ecuación relevante puede expresarse como

(7)
Donde
piq es la parte de las relaciones de los vértices
j en comparación con todas las relaciones de los vértices
i.
Mediante el cálculo de la jerarquía de los agujeros estructurales de cada índice de precios (véase el cuadro S3), la jerarquía de los agujeros estructurales de los índices de precios con un grado de influencia no inferior a 10 (grado ponderado> = 10) Los principales índices de precios son índices de tipo PPI, lo que significa que, en el PIWN, el PPI tiene fuertes efectos de transmisión; Sin embargo, los índices de precios de los alimentos y los medios impresos en el índice de precios al productor tienen efectos de transmisión más fuertes, con un grado de influencia de más de 25. Por lo tanto, para moderar la fluctuación de los índices de precios de los productos básicos es importante regular y controlar estos precios Con fuertes efectos de transmisión. Los resultados del experimento muestran que los índices de precios con una jerarquía de agujeros estructurales de más de 0,02 tienen un grado de influencia inferior a 8. Estos resultados muestran que, aunque algunos índices de precios en la estructura de la red tienen un pequeño grado de influencia, Desempeñan un papel importante en la transmisión de las fluctuaciones de los precios. Al mismo tiempo, encontramos que las fluctuaciones de precios entre grupos de clusters se llevan a cabo por sus índices de precios mutuos. Como se muestra en la Figura 6, los nodos negros son medios conductores de 2 grupos de grupos.
Tabla 4
Jerarquía de los hoyos estructurales de los indices de precios con un grado de influencia no menor a 10 (top 10 de los indices de precios).
| Rango | Tipo de índice de precios | Grado ponderado | Jerarquía |
| 1 | CPI(Touring and Outing) | 13.05 | 0.01843 |
| 2 | PPI(Processing of Food from Agricultural Products) | 28.77 | 0.01412 |
| 3 | PPI(Food) | 32.70 | 0.01405 |
| 4 | PPI(Printing, Reproduction of Recording Media) | 27.84 | 0.01378 |
| 5 | RPI(Furniture) | 27.79 | 0.01312 |
| 6 | PPI(Food Industry) | 30.13 | 0.01269 |
| 7 | CPI(Intercity Traffic Fare) | 11.43 | 0.01253 |
| 8 | CPI(Transportation) | 11.38 | 0.01253 |
| 9 | API | 36.18 | 0.01242 |
| 10 | PPI(Raw Materials Industry) | 26.43 | 0.01236 |
Distancia de transmisión y trayectoria
Cuando uno de los índices de precios cambia, hasta dónde puede llegar el proceso de transmisión, y cuál es el camino de transmisión? Para responder a esta pregunta, debemos conocer la distancia de transmisión más corta entre los índices de precios. La distancia de transmisión más corta en el PIWN se puede determinar calculando el trayecto más corto. Esta distancia se puede definir como el número mínimo de bordes a través del cual pasan los dos índices de precios en la estructura de la red. Cuando un índice de precios cambia, podemos medir la distancia de impacto más larga calculando el trayecto más corto entre este índice de precios y otros. Además, podríamos conocer la distancia de impacto de todo el sistema de índices de precios al encontrar la trayectoria media más corta del PIWN. Por lo tanto, cuando un índice de precios cambia, podríamos saber qué índice de precios se verá afectado a continuación.
Como se muestra en la Figura 8, las distancias de transmisión de los índices de precios siguen una distribución normal. Una distancia de 1 significa que los dos índices de precios en el PIWN están conectados directamente. Los cambios en cualquiera de los índices de precios afectarán al otro. Se considera que la distancia de impacto es 1. Una distancia de 2 significa que los dos índices de precios están conectados por otro índice de precios (conectado indirectamente). Así, la distancia de impacto se expande a 2. Después de continuar de esta manera, la Figura 8 muestra que las distancias de transmisión de los índices de precios se concentran entre 2 y 4. Así, generalmente las distancias de transmisión de la mayoría de los índices de precios son 2-4 , Lo que significa que, cuando un índice de precios cambia, sólo 2-4 distancias son necesarias para afectar a la mayoría. La distancia de transmisión de fluctuación más larga es de 9 en el PIWN, lo que significa que, cuando cambia un determinado índice de precios, el sistema de índice de precios se verá afectado a una distancia de 9. La longitud de trayecto más corta promedio es 2,55. El índice de cohesión de la estructura de red basado en "distancia" es 0.953. Por lo tanto, la transmisión entre los índices de precios en la estructura de la red es relativamente rápida, tiene un efecto de pequeño mundo, y, en promedio, puede ser completado por un índice de precios. Los resultados también muestran que, en la inflación real, un vértice a menudo tiene un impacto en todos los precios de las materias primas antes de tomar medidas de control efectivas.
Figura 8
Distancia más corta y frecuencia entre los índices de precios.

Después de una distribución normal con un nivel de confianza de 0,78.
Analizamos los caminos en el PIWN y encontramos la trayectoria de transmisión basada en los pesos de los bordes. Tomando el IPR como ejemplo (el valor de su grado ponderado es el más grande), cuando el IPR cambia, el nodo más correlacionado es CPI, y el nodo más correlacionado con IPC es IPC (Hogar Urbano). Siguiendo este proceso, podríamos encontrar otros nodos. De acuerdo con el camino más corto que hemos obtenido anteriormente, la distancia de transmisión más larga es 9; Como resultado, cuando encontramos el 10mo nodo, el RPI (Casa Rural) ya había afectado a todo el sistema. La trayectoria de transmisión del RPI (Casa Rural) se muestra en la Figura 9, con las correlaciones entre los índices de precios (pesos de los bordes) por encima de 0.96. Por supuesto, sólo habíamos considerado el camino con las correlaciones más fuertes. En realidad, los nodos de la trayectoria de transmisión pasarán la fluctuación a otros nodos. Podríamos utilizar el mismo método para encontrar todos los caminos de transmisión y luego conocer más completamente el proceso de transmisión de los índices de precios.
Figura 9

Senderos de transmisión de RPI (Rural Household) con las correlaciones más fuertes.
Discusiones y conclusiones
Este artículo analiza las características de la estructura de correlación de los índices de precios por los métodos que implican redes complejas. Teóricamente, consideramos las relaciones entre muchos factores y realizamos la investigación con una visión estructurada, mientras que la econometría tradicional sólo puede analizar las relaciones entre algunos factores. En la práctica, este enfoque podría ayudarnos a conocer más sobre las interacciones de los índices de precios analizando las características de la estructura de correlación. Este análisis no sólo nos muestra los principios de las interacciones de los índices de precios en el sistema económico sino que también nos proporciona pruebas efectivas de las políticas de control macroeconómico para el gobierno. Encontrar los índices clave de precios podría hacernos conscientes de qué objeto de control es el objetivo clave; El análisis de los grupos de grupos podría mostrarnos las influencias entre los índices de precios, y luego, podríamos sugerir al gobierno cómo estabilizar el precio de mercado regulando escasamente. Analizar el medio de transmisión nos muestra el nivel medio de cada índice de precios, y el gobierno podría evitar la expansión de las fluctuaciones mediante el control de los medios. Medir la distancia de transmisión y descubrir el camino nos indica la escala de impacto y su trayectoria de transmisión cuando hay fluctuaciones en los índices de precios; Estas rutas de transmisión proporcionan referencias cuando se hacen políticas de advertencia.
Un tema que debe investigarse más es cómo estudiar las relaciones que involucran muchas variables si el número de factores que afectan en un sistema económico continúa aumentando; Hay cientos o incluso miles de factores que interactúan entre sí. Como se muestra en la revisión bibliográfica, la mayoría de los estudios sobre la relación entre variables usan teorías y métodos de econometría como regresiones lineales, pruebas de causalidad y pruebas de cointegración. Sin embargo, el propósito de estos modelos econométricos no es incluir todas las variables; En cambio, el propósito es incluir sólo los factores más significativos. Si se introducen demasiadas variables, entonces el modelo será demasiado complejo y la investigación perderá sentido. El número de objetos incluidos en los métodos econométricos tradicionales es dos; Incluso si hay múltiples variables, el análisis se realiza con sólo dos variables. Además, muchos de los objetos incluidos son macroscópicos. Por lo tanto, es fácil ignorar las variables de nivel micro. Estas variables tienen correlaciones e influencia, e interactúan entre sí para formar un complicado sistema de relaciones. Los cambios macroscópicos son causados por cambios en la complejidad de estas variables. Las investigaciones existentes rara vez abordan estas cuestiones. La teoría de red compleja proporciona una buena base para abordar el problema de la complejidad. Las relaciones entre las variables se resumen en los vértices y los bordes de la red, aplicando la investigación sobre la relación entre las numerosas variables en la red. El complejo método de análisis de red proporciona una gama de parámetros y puede combinarse con teorías económicas y métodos analíticos para estudiar problemas complejos en el sistema de índices de precios y el sistema financiero e incluso en el sistema económico.
Al construir el modelo de estructura de la red de correlación de índices de precios, el método no sólo puede utilizarse para estudiar la estructura de correlación de los índices de precios, sino también para otros campos, como el análisis de la correlación entre diversos elementos de los mercados de productos básicos, De los vínculos de precios de las acciones en los mercados financieros, de la investigación sobre las relaciones insumo-producto en las cadenas industriales y de la investigación sobre las relaciones de correlación entre los diversos índices económicos nacionales. Estas cuestiones involucran más variables y relaciones más complejas. Otras investigaciones deberían tener como objetivo definir relaciones complejas entre más variables y combinar métodos de análisis cualitativos y cuantitativos.
Referencias
1. Lebow DE, Rudd JB (2006) Inflation measurement. Finance and economics discussion series divisions of research & statistics and monetary affairs.
Federal Reserve Board, Washington, D.C. 1–17
2. Alchian AA, Klein B (1973) On a correct measure of inflation.
Journal of Money, Credit and Banking 5: 173–191
3. Mankiw NG, Reis R (2003) What measure of infaltion should a central bank target?.
Journal of the European Economic Association 1: 1058–1086
4. Silver JL, Wallace D (1980) The lag relationship between wholesale and consumer prices.
Journal of Econometrics 12: 375–387
5. Mahdavi S, Zhou S (1997) Gold and commodity prices as leading indicators of inflation: tests of long-run relationship and predictive performance.
Journal of Economics and Business 49: 475–489
6. Kyrtsou C, Labys W (2006) Evidence for chaotic dependence between US inflation and commodity prices.
Journal of Macroeconomics 28: 256–266
7. Blomberg SB, Harris ES (1995) The commodity-consumer price connection: fact or fable?.
Economic Policy Review 1: 21–38
8. Doroodian K, Boyd R (2003) The linkage between oil price shocks and economic growth with inflation in the presence of technological advances: a CGE model. Energy Policy 31: 989–1006
9. Johnson GD, Song G (1998) Inflation and the Real Price of Grain in China. Chinese Economies Research Center, Working Paper, University of Adelaide.
10. Kadeřábek P (2007) A simple model of interaction between CPI and PPI: Application to monthly data of EU countries.
Politická ekonomie 55: 226–244
11. Cushing MJ (1990) Freedback between Whosale and Consumer Price Inflation: A reexamination of the evidence.
Southern Economic Journal 56: 1059–1072
12. Clark TE (1995) Do producer prices lead consumer prices?.
Economic Review QIII 25–39
13. Weinhagen J (2005) Price transmission within the PPI for intermediate goods.
Monthly Labor Review 5: 41–49
14. Gujarati DN, Porter DC (2010)
Essentials of Econometrics, 4th edition. McGraw Hill Higher Education.
15. Peazzo RPJ, Reich SL, Schvarzer J, Virasoro MA (1995) Inflation and relaxation to equilibrium in a complex economic-system.
Chaos Solitions & Fractals 6: 455–470
16. Schweitzer F, Fagiolo G, Sornette D, Vega-Redondo F, Vespignani A, et al. (2009) Economic Networks: The New Challenges.
Science 325: 422–425 [PubMed]
17. Elgazzar AS (2003) Applications of small-world networks to some socio-economic systems.
Physica A: Statistical Mechanics and its Applications 324: 402–407
18. Watts DJ, Strogatz SH (1998) Collective dynamics of ‘small-world’ networks.
Nature 393: 440–442 [PubMed]
19. Newman MEJ, Watts DJ (1999) Renormalization group analysis of the small-world network model.
Physics Letters A 263: 341–346
20. Barabási AL, Albert R (1999) Emergence of Scaling in Random Networks.
Science 286: 509–512 [PubMed]
21. Latora V, Marchiori M (2003) Economic small-world behavior in weighted networks.
The European Physical Journal B 32: 249–263
22. Eagle N, Macy M, Claxton R (2010) Network Diversity and Economic Development. Science 328: 1029–1031 [PubMed]
23. Liu XF, Tse CK (2012) A complex network perspective of world stock markets : synchronization and volatility.
International Journal of Bifurcation and Chaos 22: 1250142
24. Kenett DY, Tumminello M, Madi A, Gur-Gershgoren G, Mantegna RN, et al. (2010) Dominating clasp of the financial sector revealed by partial correlation analysis of the stock market. PLoS ONE 5: e15032. [PMC free article] [PubMed]
25. Tse CK, Liu J, Lau FC (2010) A network perspective of the stock market.
Journal of Empirical Finance 17: 659–667
26. He LP, Liu QW (2011) Causes of Inflation in China: Inflation Expectations.
China & World Economy 19: 18–32













