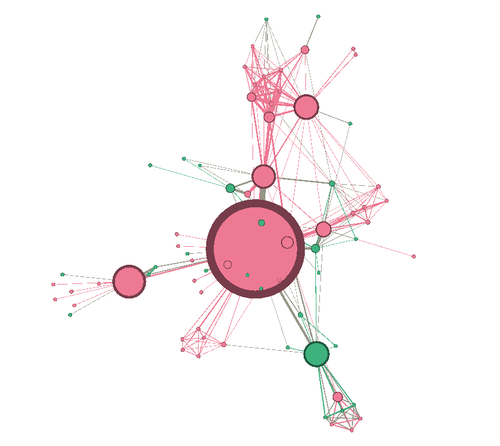
Google y Apple son empresas hiper-exitosas, pero trazando sus patentes uno tiene firmas de innovación completamente diferentes.
Mark Wilson - Fast CoDesign

Steve Jobs se ha concedido 347 patentes en la última década, muchos concedidos póstumamente. Por el contrario, Google Sergey Brin y Larry Page sólo tienen un 27 combinado en el mismo período.
Es una estadística reveladora sobre cómo Apple y Google funcionan de manera diferente. Apple está impulsado principalmente por una estructura de desarrollo centralizada, derivada de su fabuloso estudio de diseño, mientras que Google tiene un enfoque más distribuido y de código abierto para los nuevos productos. Y para obtener una imagen real de cómo esto funciona de manera organizativa, el Periscopic, un estudio de visualización de datos con sede en Portland, creó una serie de visualizaciones personalizadas para Co.Design, que compara las "firmas de innovación" en los últimos 10 años de patentes presentadas en Apple y Google .

Izquierda: Apple, Derecha: Google
Para entender lo que estás viendo, sé que cada gota es un inventor de patentes, y como muchas patentes tienen múltiples inventores, cada línea es un enlace entre un inventor y los co-inventores.
Desde este punto de vista, Apple se parece a una gran bola de juguete redondos, mientras que Google es una red celular monótona más parecido a los Borg. Y mientras que usted puede decir tan mucho de la estructura de una compañía de apenas sus patentes, Periscopic cree que ha manchado una narración clara en las imágenes.
"En los últimos 10 años Apple ha producido 10.975 patentes con un equipo de 5.232 inventores, y Google ha producido 12.386 con un equipo de 8.888", escribe Wes Bernegger, explorador de datos en Periscopic. Esos números son, francamente, bastante similares en términos de proporción. "La diferencia más notable que vemos es la presencia del grupo de super inventores altamente conectados y experimentados en el núcleo de Apple en comparación con la estructura de innovación más uniformemente dispersa en Google", continúa. "Esto parece indicar un sistema de control centralizado de arriba hacia abajo, en Apple, frente a potencialmente más independencia y empoderamiento en Google".

Apple (detalle)
La teoría tiene mucho sentido. El laboratorio de diseño secreto de Apple, liderado por Jonathan Ive, ha dado a luz a los muy pocos productos de la compañía, muy rentables. Y dentro de la huella de innovación de Apple, verás Ive, junto con los nombres de básicamente todos los diseñadores sub-celebrados en el círculo interno, incluyendo Eugene Whang, Christopher Stringer, Bart Andre y Richard Howarth, que ahora lidera el desarrollo de hardware en Apple y Es en gran parte responsable del diseño de cada iPhone que hayas visto.

Google (detalle)
Google, por otro lado, tiene una estructura organizativa relativamente plana de muchos pequeños equipos llenos de personas con poder. (La compañía incluso intentó borrar toda la gestión en 2002, pero desde que se restableció la idea.) Todo esto se puede ver en su firma de innovación, por supuesto. Por patentes, los Googlers parecen bastante iguales, dispersos relativamente uniformemente.
Dicho esto, Bernegger insiste en que en realidad hay más "conectividad y colaboración" en Apple que en Google. "El número promedio de inventores que figuran en una patente de Apple es de 4.2. En Google, es 2.8", explica. "Estos efectos combinados significan que un inventor en Apple ha producido, en promedio, más del doble de patentes que uno en Google. Nueve contra cuatro".
No podrían parecer más diferentes, pero mirar más de cerca la estructura de la patente, y se puede detectar una gran similitud entre las dos empresas. A saber, tanto Apple y Google tienen un anillo de membrana que rodea toda la estructura. ¿Quiénes son estos fabricantes de patentes que desarrollan cosas en relativo aislamiento? ¿Y cómo están afiliados con las empresas?

En el caso de Google, tenemos una pista. Uno de los inventores más grandes de la compañía vive allí, en la periferia, desconectado de otros productos. Ese inventor es Kia Silverbrook, que vendió la compañía 269 patentes concedidas en cámaras e impresoras en 2013. Obviamente las patentes que se han adquirido recientemente, más bien que desarrolladas en casa, carecerían de las interconexiones con otros empleados que centralizan las burbujas más grandes. Además, estos anillos exteriores podrían representar las contribuciones de cualquier cosa, desde invenciones únicas de un empleado al azar, hasta las contribuciones secretas de los laboratorios de skunkworks y de las compañías de shell, trabajando fuera del equipo principal. Pero eso requeriría más investigación para confirmar.

Apple
Mientras que estos gráficos fueron hechos específicamente para esta historia, provienen de PatentsView, un visualizador Periscopic ayudó a desarrollar para los institutos americanos para la investigación y el USPTO. Es un sistema accesible al público que transforma la base de datos de patentes que hemos tenido durante años -una base de datos de búsqueda de Internet temprana que extrae algunas exploraciones de patentes en formato JPEG- en una red visible de conexiones. Usted puede mirar las patentes dentro de las empresas, como se ha visto anteriormente, o clasificar por creador o tema, también.
"Nuestra intención detrás de PatentsView era crear interfaces que pudieran inspirar al público a explorar datos de patentes", dice el cofundador de Periscopic, Dino Citraro. "Parte de eso fue hacer un acceso simplificado a los datos de patentes para personas como abogados de patentes que necesitan investigarlo, pero queríamos abrazar este esfuerzo de gobierno abierto y decir, 'Esta es información pública, es interesante. '"
De hecho, Apple y Google sólo puede ser un comienzo. Probablemente podría escribir un libro sobre las estructuras organizativas corporativas revelado en PatentsView -información que ha sido pública durante un siglo, pero que sólo ahora es fácilmente transparente ahora.

 .
.