Uso de Filtros en Gephi
- DESCARGAR UN ARCHIVO DE RED PARA PRACTICAR
Descargue este
archivo zip y descomprímalo en su computadora.
O utilice este enlace directo:
https://tinyurl.com/gephi-tuto-3
Debe encontrar el archivo miserables.gexf en él. Guárdelo en una carpeta que recordará (o cree una carpeta especialmente para este pequeño proyecto).
- DESCRIPCIÓN DEL ARCHIVO / DE LA RED
Este archivo contiene una red que representa "quién aparece junto a quién" en la novela del siglo XIX Les Misérables de Victor Hugo [
1].
Un enlace entre los caracteres A y B significa que aparecen en la misma página o párrafo de la novela.
El nombre del archivo termina con ".gexf", lo que significa que es un archivo de texto donde se almacena la información de la red (nombre de los personajes, sus relaciones, etc.) siguiendo algunas convenciones.
- ABRIR LA RED EN GEPHI
- Abra Gephi. En la pantalla de bienvenida que aparece, haga clic en Abrir archivo de grafo (Open Graph File)
- Encuentra miserables.gexf en tu computadora y ábrala
 Figura 1. pantalla de bienvenida --> abrir gráfico
Figura 1. pantalla de bienvenida --> abrir gráfico
Se abrirá una ventana de informe que le dará información básica sobre la red que abrió:
 Figura 2. ventana de informe
Figura 2. ventana de informe
Esto le dice que la red consta de 74 caracteres, conectados por 248 enlaces.
Los enlaces no están dirigidos, lo que significa que si A está conectado a B, entonces es lo mismo que B conectado a A.
El informe también nos dice que la gráfica no es dinámica: significa que no hay evolución o cronología, que no "se mueve en el tiempo".
Haga clic en Aceptar para ver el gráfico en Gephi.
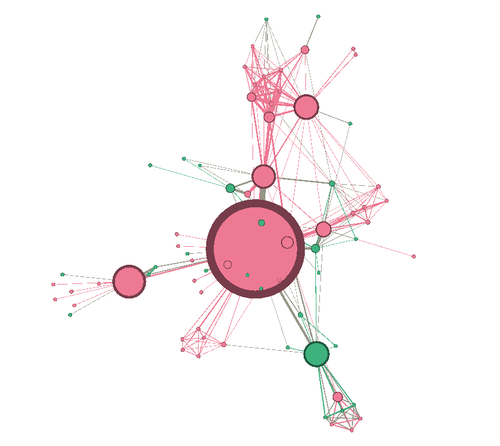 Figura 3. La red que usaremos
Figura 3. La red que usaremos
DANDO UN SENTIDO DE LOS ATRIBUTOS EN EL LABORATORIO DE DATOS
Podemos cambiar al laboratorio de datos para ver los datos subyacentes:
 Figura 4. Cambio al laboratorio de datos
Figura 4. Cambio al laboratorio de datos
Vemos que los nodos de la red tienen muchos atributos. En particular, cada uno tiene un Género y una medida de lo central que son:
 Figura 5. Atributos de nodos.
Figura 5. Atributos de nodos.
Esta es la lista de aristas (relaciones) en la red. Observe que tienen un "peso" (una "fuerza").
 Figura 6. Atributos de bordes
Figura 6. Atributos de bordes
DESCUBRIMIENTO DEL PANEL DEL FILTRO
En la vista general, asegúrese de que se muestre el panel Filtro:
 Figura 7. Visualización del panel Filtro.
Figura 7. Visualización del panel Filtro.
Cómo funciona el panel Filtro:
 Figura 8. Flujo de trabajo de los filtros
Figura 8. Flujo de trabajo de los filtros
Un ejemplo: ocultando enlaces con un peso inferior a 2
 Figura 9. Cómo utilizar los filtros.
Figura 9. Cómo utilizar los filtros.
Cuando haya terminado de usar un filtro en la zona, haga clic derecho en él y seleccione "eliminar".
COMBINANDO 2 FILTROS
Un filtro se aplica DESPUÉS de este otro:
El primer filtro a ser aplicado es ANIDADO (colocado dentro) del segundo como un "subfiltro"
¿Qué filtro debe colocarse dentro de cuál? Echemos un vistazo a diferentes ejemplos:
1. CASO CUANDO LA COLOCACIÓN DE FILTROS NO HACE NINGUNA DIFERENCIA
Objetivo: Mantener en pantalla sólo los personajes femeninos que tienen un empate (un borde, una relación) de al menos fuerza 2.
→ coloque el filtro "peso del borde" dentro del filtro "Género":

Figura 10. Filtro en el atributo Género
 Figura 11. Filtro sobre el peso del enlace
Figura 11. Filtro sobre el peso del enlace
 Figura 12. Mantener sólo personajes femeninos con al menos 2 lazos
Figura 12. Mantener sólo personajes femeninos con al menos 2 lazos
En este caso, era equivalente a:
- Anidar el filtro "Género" dentro del filtro "Peso del borde" o
- Anida el filtro "Peso del borde" dentro del filtro "Género"
→ El resultado fue el mismo (la red en pantalla es idéntica en ambos casos)
2. CASO CUANDO LA COLOCACIÓN DE FILTROS HACE UNA DIFERENCIA
Aquí, queremos visualizar:
- Sólo los nodos que tienen menos de 10 relaciones <1>
- Y entre éstos, sólo aquellos que forman la "isla principal" de la red (queremos esconder pequeños grupos separados de nodos) <2>
- En términos técnicos, nodos con un grado de menos de 10.
- En términos técnicos, estamos buscando el componente gigante
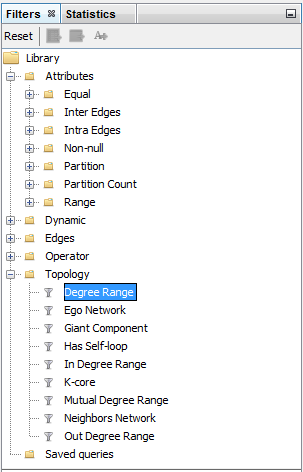 Figura 13. Filtro en grado
Figura 13. Filtro en grado
 Figura 14. Filtro en el componente gigante
Figura 14. Filtro en el componente gigante
Veremos que la colocación en los filtros de la zona marcará la diferencia.
Primero, coloquemos el filtro en el componente gigante dentro del filtro en grado:
 Figura 15. Filtros en una configuración
Figura 15. Filtros en una configuración
En este primer caso,
- Sólo se hizo visible el componente gigante de la red.
→ Puesto que la red era apenas una "isla" conectada grande para comenzar con, no cambió una cosa.
- Entonces, todos los personajes con más de 10 relaciones donde se ocultan
→ esto oculta los nodos que se conectaban con muchos otros, de modo que terminamos con muchos grupos, desconectados unos de otros.
Ahora, en su lugar, colocando el grado de filtro dentro del filtro en el componente gigante:
Orden de filtro 2 es
 Figura 16. Mismos filtros en otra configuración
Figura 16. Mismos filtros en otra configuración
En este segundo caso,
- A partir de la red completa, todos los caracteres con más de 10 relaciones donde se eliminan.
→ esto creó una red hecha de muchos grupos de nodos desconectados
- Entonces se aplica el filtro de componentes gigantes,
→ que tenían por efecto ocultar pequeños grupos, para mantener en la vista solamente el grupo más grande de nodos conectados.
Advertencia
En resumen: tenga cuidado al aplicar varios filtros a la vez, esto podría tener un efecto sobre la lógica del filtrado.