Ouseful,.info
A través de un vínculo de referencia Check Yo Self: 5 Things You Should Know About Data Science (Author Note) al criticar mapeo de tweets sin más análisis ( "Si estás haciendo grafos en Gephi de tweets, es probable que estés haciendo más análisis de marketing que análisis de ciencia de datos y corténla!. por favor. no lo puedo aguantar más. ... de qué sirve a alguien tener grafos de tweets y no hacerle análisis a ellos? "), me encontré con el blog [sin curso] Analytics Made Skeezy de John Foreman:
Analytics Made Skeezy es un blog falso. Cada post es parte de una narrativa más grande diseñada para enseñar una variedad de temas de análisis mientras se mantiene interesante. El uso de una sola narrativa me permite contrastar diferentes enfoques dentro del mismo mundo falso. Y en última instancia, eso es lo que este blog es acerca de: enseñar al lector cuándo usar ciertas herramientas analíticas.
Rebotando a través de ejemplos descritos en algunos de los puestos hasta la fecha, Even Wholesale Drug Dealers Can Use a Little Retargeting: Graphing, Clustering & Community Detection in Excel and Gephi no es sorprendente que me haya llamado la atención. Ese puesto se describe, en forma narrativa, cómo utilizar Excel para preparar y dar forma a un conjunto de datos para que pueda ser importado en Gephi como un archivo CSV de imitación y luego ejecutar a través de estadística de la modularidad de Gephi; el conjunto de datos aumentada clase modularidad puede ser exportado de los datos de laboratorio Gephi y re-presentado en Excel, con lo cual el uso juicioso de la columna de clasificación y formato condicional se usa para tratar de generar algún tipo de conocimiento acerca de los racimos / grupos descubiertos en los datos - al parecer, "Gephi puede aspirar un poco por darnos ese tipo de visión a veces. Depende del grafo y lo que estamos tratando de hacer ". Y además:
Si usted tenía un gran conjunto de datos que se preparó en un grafo de vecinos más cercanos recortado, tener en cuenta que visualizándolo en Gephi es sólo por diversión. No es necesario para la penetración real, independientemente de lo que los montones de presentaciones de tweets-extensión-como se visualiza-en-Gephi podrían decirle (amordáceme). Sólo tiene que hacer la pieza de detección de la comunidad. Se puede utilizar para ese Gephi o las bibliotecas que utiliza. R y Python ambos tienen un paquete llamado igraph que hace estas cosas también. Lo que usted utiliza, sólo tiene que obtener las tareas de la comunidad de su gran base de datos para que pueda funcionar cosas como el análisis agregado sobre ellos a la inteligencia brotan de cada grupo.
No estoy necesariamente de acuerdo con la implicación de que a menudo necesitamos hacer algo más que mirar a cuadros bonitos en Gephi para dar sentido a un conjunto de datos; pero sí creo que también podemos utilizar Gephi de una manera activa para mantener una conversación con los datos, generando algún tipo de ideas preliminares a cabo sobre el conjunto de datos que entonces podemos explorar más a fondo el uso de otras técnicas analíticas. Entonces, ¿qué voy a tratar de hacer en el resto de este post es ofrecer algunas sugerencias acerca de una o dos maneras en las que podríamos utilizar Gephi para comenzar a conversar con el mismo conjunto de datos descrito en el puesto Narcotraficante Cambio de destino. Antes de hacerlo, sin embargo, le sugiero que lea el post original y tratar de llegar a algunas de sus propias conclusiones acerca de lo que los datos podrían estar diciéndonos ...
...
¿Listo? En resumen, el conjunto de datos original ( "Inventario") es una lista de "ofertas", con columnas relativas a los dos tipos de cosas: 1) cualidad de un acuerdo; 2) una columna por un distribuidor que señala si ellos tomaron ese trato. entonces se genera una matriz de cliente / cliente y el coseno similitud entre cada cliente calculado (nota: otras métricas de distancia están disponibles ...) indicando la medida en la que participó en acuerdos similares. La selección de los tres vecinos más similares a los de cada cliente crea un "grafo de vecinos más próximos recortado", que se munged en un formato de datos CSV-parecida a la Gephi puede importar. Gephi se utiliza entonces para hacer un análisis visual muy rápida / superficial (y con descuento), y ejecutar el algoritmo de detección de la modularidad / agrupación.
Entonces, ¿cómo iba yo he atacado este conjunto de datos (Nota: IANADS (no soy un científico de datos ;-)
Una forma sería tratarlo desde el principio como definir un grafo en el que los distribuidores están conectados a los oficios. Utilizando una versión ligeramente ordenado de la ficha de inventario 'del conjunto de datos original en el que me quita la primera filas (metadatos) y la última (totales), y ajustado uno de los nombres de columna para eliminar los corchetes (no creo que le gusta Gephi soportes en los nombres de atributo?), he utilizado la siguiente secuencia de comandos para generar una versión GraphML con formato de sólo un grafo de este tipo.
.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| #Python script to generate GraphML fileimport csv#We're going to use the really handy networkx graph library: easy_install networkximport networkx as nximport urllib#Create a directed graph objectDG=nx.DiGraph()#Open data file in universal newline modereader=csv.DictReader(open("inventory.csv","rU"))#Define a variable to act as a deal node ID counterdcid=0#The graph is a bimodal/bipartite graph containing two sorts of node - deals and customers#An identifier is minted for each row, identifying the deal#Deal attributes are used to annotate deal nodes#Identify columns used to annotate nodes taking string valuesnodeColsStr=['Offer date', 'Product', 'Origin', 'Ready for use']#Identify columns used to annotate nodes taking numeric valuesnodeColsInt=['Minimum Qty kg', 'Discount']#The customers are treated as nodes in their own right, rather than as deal attributes#Identify columns used to identify customers - each of these will define a customer nodecustomerCols=['Smith', 'Johnson', 'Williams', 'Brown', 'Jones', 'Miller', 'Davis', 'Garcia', 'Rodriguez', 'Wilson', 'Martinez', 'Anderson', 'Taylor', 'Thomas', 'Hernandez', 'Moore', 'Martin', 'Jackson', 'Thompson', 'White' ,'Lopez', 'Lee', 'Gonzalez','Harris', 'Clark', 'Lewis', 'Robinson', 'Walker', 'Perez', 'Hall', 'Young', 'Allen', 'Sanchez', 'Wright', 'King', 'Scott','Green','Baker', 'Adams', 'Nelson','Hill', 'Ramirez', 'Campbell', 'Mitchell', 'Roberts', 'Carter', 'Phillips', 'Evans', 'Turner', 'Torres', 'Parker', 'Collins', 'Edwards', 'Stewart', 'Flores', 'Morris', 'Nguyen', 'Murphy', 'Rivera', 'Cook', 'Rogers', 'Morgan', 'Peterson', 'Cooper', 'Reed', 'Bailey', 'Bell', 'Gomez', 'Kelly', 'Howard', 'Ward', 'Cox', 'Diaz', 'Richardson', 'Wood', 'Watson', 'Brooks', 'Bennett', 'Gray', 'James', 'Reyes', 'Cruz', 'Hughes', 'Price', 'Myers', 'Long', 'Foster', 'Sanders', 'Ross', 'Morales', 'Powell', 'Sullivan', 'Russell', 'Ortiz', 'Jenkins', 'Gutierrez', 'Perry', 'Butler', 'Barnes', 'Fisher']#Create a node for each customer, and classify it as a 'customer' node typefor customer in customerCols: DG.add_node(customer,typ="customer")#Each row defines a dealfor row in reader: #Mint an ID for the deal dealID='deal'+str(dcid) #Add a node for the deal, and classify it as a 'deal' node type DG.add_node(dealID,typ='deal') #Annotate the deal node with string based deal attributes for deal in nodeColsStr: DG.node[dealID][deal]=row[deal] #Annotate the deal node with numeric based deal attributes for deal in nodeColsInt: DG.node[dealID][deal]=int(row[deal]) #If the cell in a customer column is set to 1, ## draw an edge between that customer and the corresponding deal for customer in customerCols: if str(row[customer])=='1': DG.add_edge(dealID,customer) #Increment the node ID counter dcid=dcid+1#write graphnx.write_graphml(DG,"inventory.graphml") |
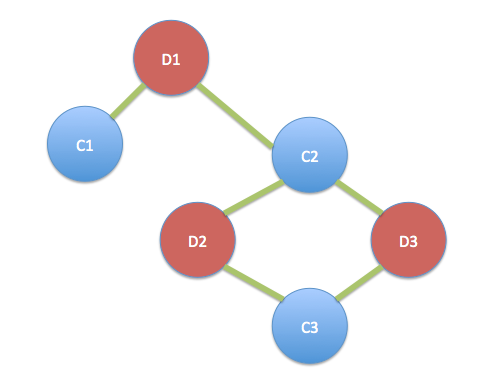
Lo que quiere decir, en este ejemplo cliente C1 efectúe un único acuerdo, D1; el cliente C2 participó en cada trato, D1, D2 y D3; y el cliente C3 participó de ofertas D2 y D3.
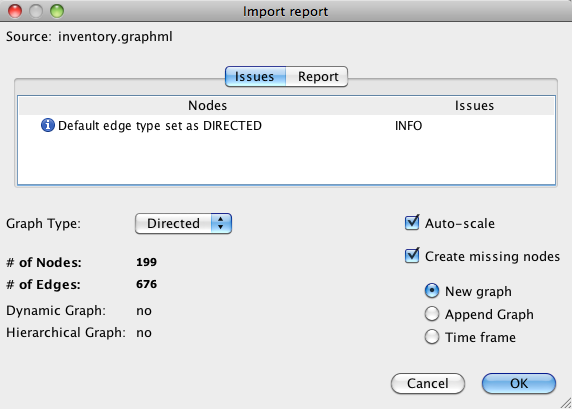
Al abrir el archivo grafo en Gephi como un grafo dirigido, se obtiene un recuento del número de operaciones reales existían a partir del recuento de enlaces:
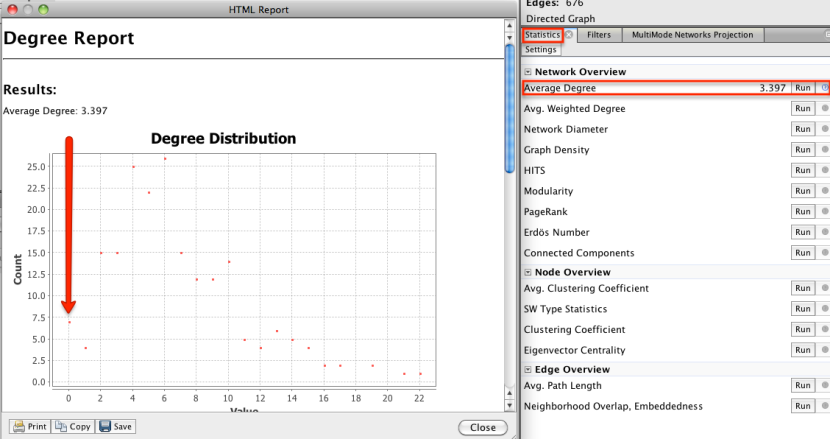
Si se corre la estadística media de grado, podemos ver que hay algunos nodos que no están conectados a otros nodos (es decir, que son o bien se ocupa de ningún comprador o clientes que nunca han participado en un trato):
Podemos ver estos nodos utilizando un filtro:
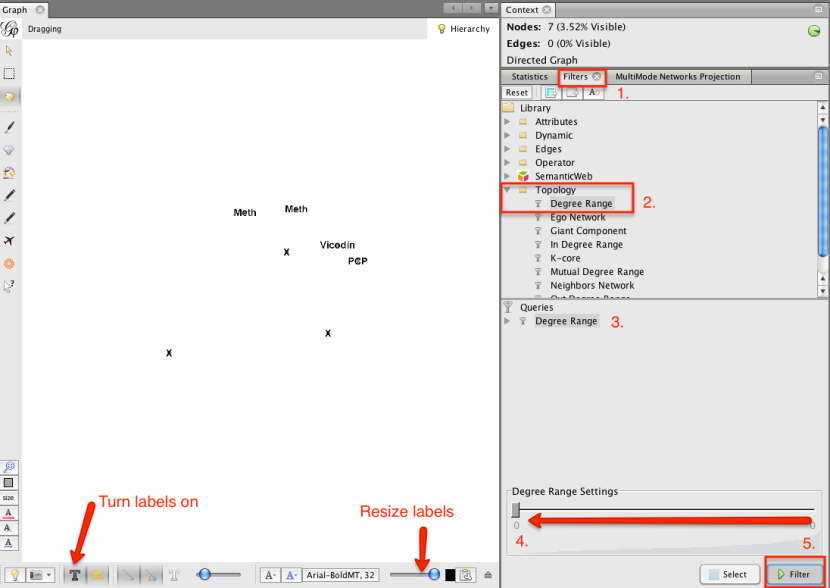
También podemos utilizar el filtro para otro lado, para excluir las ofertas no aceptadas, y luego crear un nuevo espacio de trabajo que contiene sólo las ofertas que fueron tomados, y los clientes que compraron en ellos:
El selector de espacio de trabajo es en la parte inferior de la ventana, en el lado derecho:

(Hmmm ... por alguna razón, el grafo no filtrado se exporta para mí ... todo el grafo era. Un error? Toqueteando con filtro de Componente Gigante, a continuación, exportar, a continuación, ejecutar el filtro de componentes gigante en el grafo exportado y cancelación parecía fijar cosas ... pero algo no está funcionando bien?)
Ahora podemos empezar a probar algunos análisis visual interactiva. En primer lugar, vamos a exponer los nodos utilizando un algoritmo de diseño fuerza dirigida (ForceAtlas2) que trata de situar los nodos de manera que los nodos que están conectados están situados cerca uno del otro, y los nodos que no están conectados se mantienen separados (imaginar cada nodo como tratando de repeler a los otros nodos, con los enlaces tratando de tirar de ellos juntos).
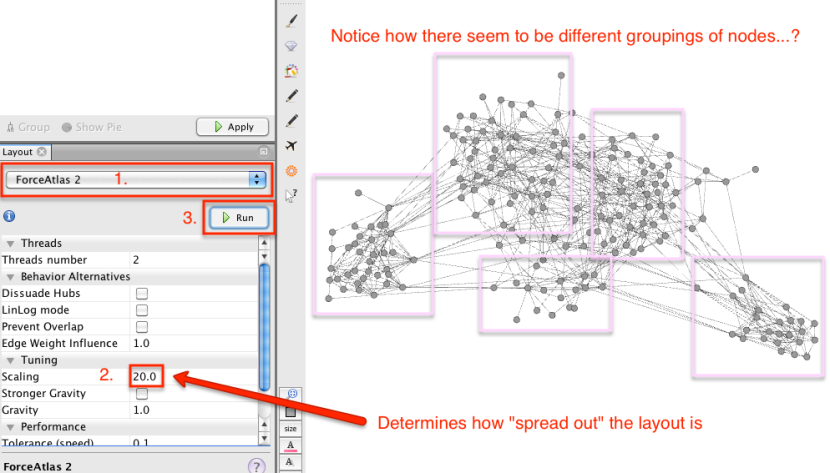
Nuestra percepción visual es muy bueno para la identificación de las agrupaciones espaciales (véase, por ejemplo, los principios de la Gestalt, que conducen a muchos un truco de diseño y un cubo de pistas sobre cómo se burlan de datos, con exclusión de una manera visualmente significativa ...), pero ¿son realmente significativo ?
En este punto de la conversación que estamos teniendo con los datos, probablemente me llamo en una estadística que trata de colocar grupos de nodos conectados en grupos separados de modo que pudiera colorear los nodos en función de su pertenencia a un grupo: la estadística de modularidad:
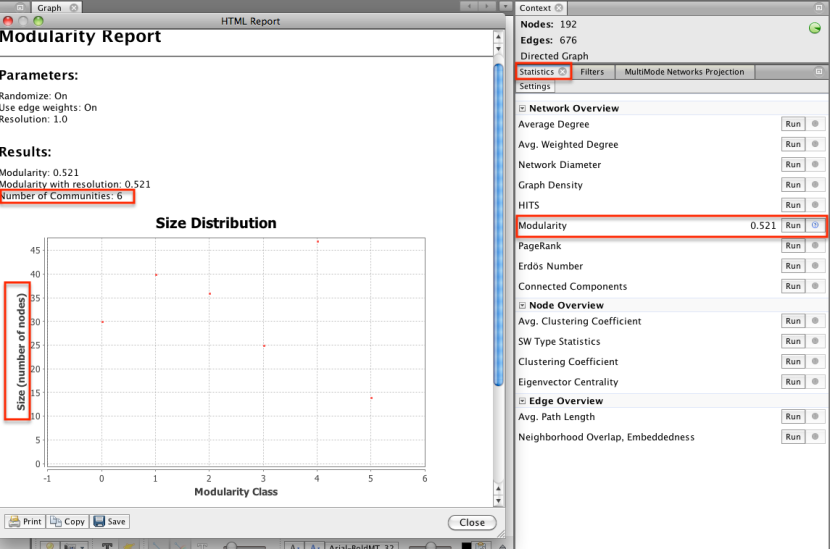
La estadística de la modularidad es un algoritmo aleatorio, por lo que puede obtener diferentes (aunque muy similares) resulta cada vez que lo ejecute. En este caso, se descubrió seis agrupaciones o grupos de nodos interconectados posibles (a menudo, un grupo es una miscelánea ...). Podemos ver qué grupo cada nodo era lugar en aplicando una coloración de reparto
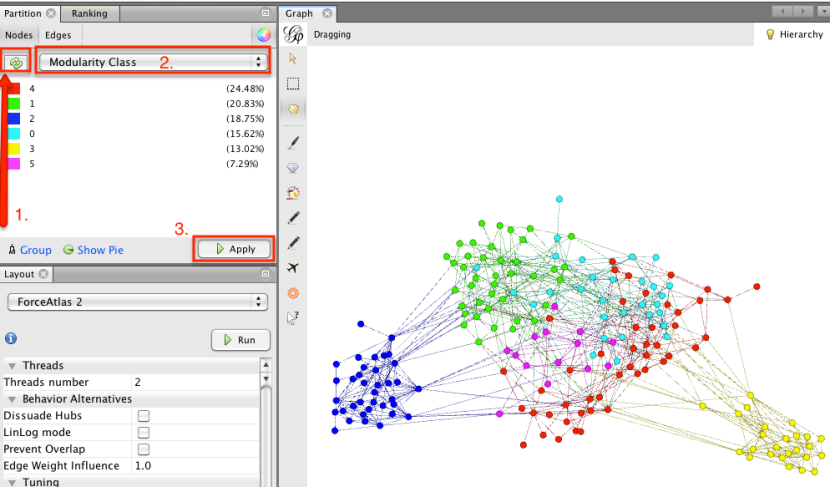
Vemos cómo las agrupaciones modularidad ampliamente mapa en que las agrupaciones visuales revelados por el algoritmo de diseño ForceAtlas2. Pero los grupos se refieren a algo significativo? ¿Qué pasa si nos volvemos las etiquetas de?
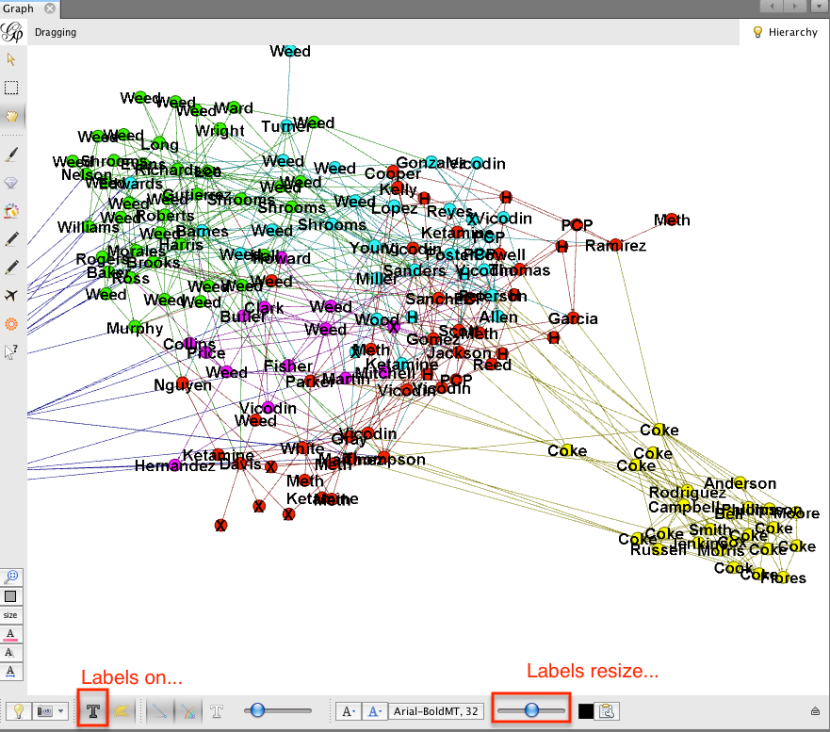
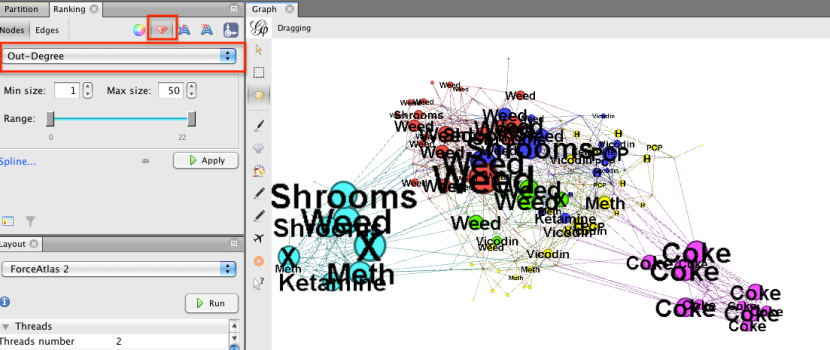
El grupo verde parece referirse a operaciones de malezas, los rojos son X, metanfetamina y ketamina ofertas, y amarillo para las cabezas de coque. Así que las ofertas no parecen agruparse en torno a diferentes tipos de trato.
Entonces, ¿qué más podríamos ser capaces de aprender? ¿La dimensión de manera operacional en un acuerdo por separado a cabo en todos los nodos (nulos en esta dimensión se relaciona con los clientes)?
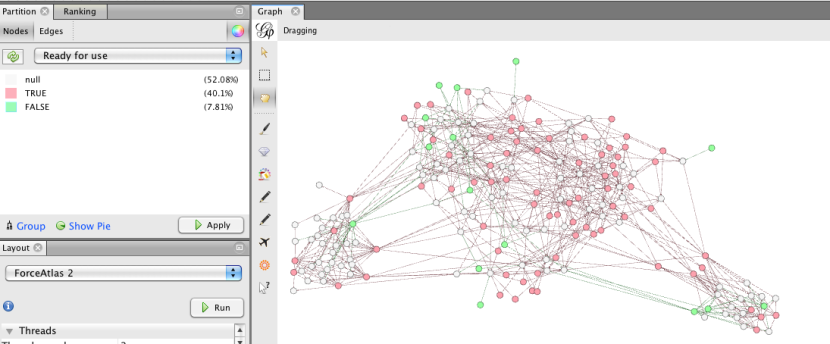
Tendríamos que saber un poco más acerca de cuáles podrían ser las consecuencias de "listo para el uso", pero a simple vista nos dan una sensación al del cluster en el extremo izquierdo está dominado por las operaciones con un gran número de clientes (hay un montón de blancos nodos / cliente) y el cluster relacionados Coca-Cola de la derecha tiene un buen número de oficios (los nodos verdes) que no están listos para su uso. (Una pregunta que viene a la mente mirando esa área es: ¿existen clientes que parecen ir a por no listo para su uso oficios, y lo que podría decirnos esto sobre ellos si es así?)
Otra cosa que podríamos mirar a es el tamaño de las operaciones, así como cualquier descuento asociados. Coloreemos los nodos utilizando la herramienta de partición de acuerdo con el tipo de nodo (nombre de atributo es "típico" - nodos son ofertas (rojo) o clientes (aqua)) y luego el tamaño de los nodos de acuerdo para hacer frente a tamaño utilizando la pantalla de clasificación:
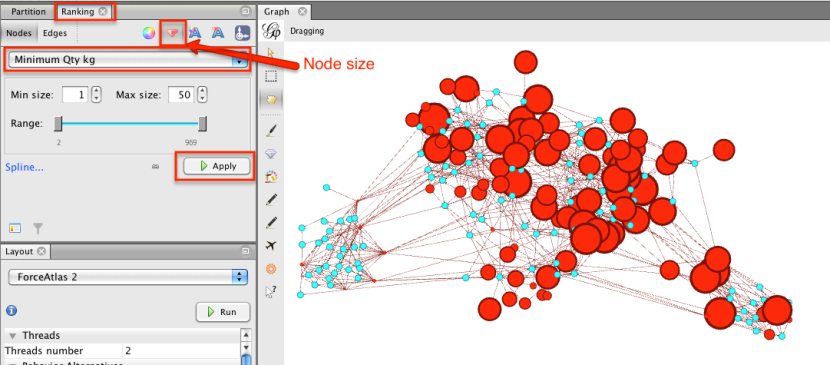
Las ofertas "fritas" pequeñas en el grupo de la mano izquierda. Mirando de nuevo a la agrupación de Coca-Cola, donde hay una mezcla de ofertas de pequeñas y grandes, otra pregunta que podríamos presentar distancia se encuentra "son los clientes que optan por allí, ya sea para los comercios grandes o pequeños?"
Volvamos al color original (a través de la partición La modularidad de color, tenga en cuenta que la asignación aleatoria de colores podría cambiar a partir del conjunto color original; botón derecho del ratón que permite volver a asignar al azar a los colores; al hacer clic en un cuadrado de color le permite color Seleccione por mano) y el tamaño de los nodos de grado de salida (es decir, la suma total de los enlaces salientes de un nodo - recuerde, el grafo se describió como un grafo dirigido, con los enlaces que van desde las transas a los clientes):
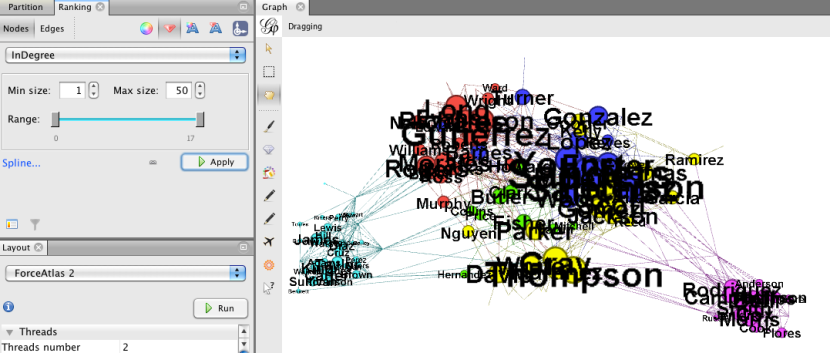
entonces he dimensionado las etiquetas para que sean proporcionales al tamaño de los nodos:

El tamaño nodo / etiqueta muestra que se ocupa tenían un montón de compradores. De calibrado por el grado de salida muestra el número de ofertas de cada cliente participó en:
Esta es una visión bastante desordenado ... volviendo al panel Diseño, podemos usar el diseño de expansión para estirarse todo el diseño, así como la Etiqueta ajusta la herramienta para sacudir nodos de modo que las etiquetas no se superponen. Observe que también puede hacer clic en un nodo para arrastrarlo por, o un grupo de nodos mediante el aumento de la "campo de visión" del cursor del ratón:
Así es como me rearmé el diseño mediante la ampliación de la disposición después ajustando las etiquetas ...:

(Una de las cosas que podría estar tentado a hacer es filtrar los usuarios que sólo participan en uno o dos o ofertas, tal vez como un wau de la identificación de los clientes habituales, por supuesto, un usuario sólo puede participar en una sola, pero muy grande trato, así que tendríamos que pensar cuidadosamente acerca de lo que eran en realidad la pregunta pidiendo a la hora de hacer una elección. por ejemplo, también puede estar interesado en la búsqueda de clientes que realizan grandes operaciones poco frecuentes, lo que requeriría una estrategia de análisis diferente.)
En la medida en que va, esto no es realmente muy interesante - lo que podría ser más convincente sería datos en relación con quien trataba con quién, pero que no está disponible inmediatamente. Lo que debemos ser capaces de hacer, sin embargo, es ver lo que los clientes están relacionados en virtud de participar de las mismas ofertas, y ver qué ofertas están relacionados en virtud de haber tratado a los mismos clientes. Podemos quizá chico nosotros mismos pensando que podemos ver en el grafo cliente-acuerdo, pero podemos ser un poco más riguroso de dos en la construcción de dos nuevos grafos: uno que muestra enlaces entre ofertas que comparten uno o más clientes comunes; y uno que muestra enlaces entre clientes que comparten una o más de las mismas ofertas.
Recordando la grafo /bipartito / "bimodal" arriba:
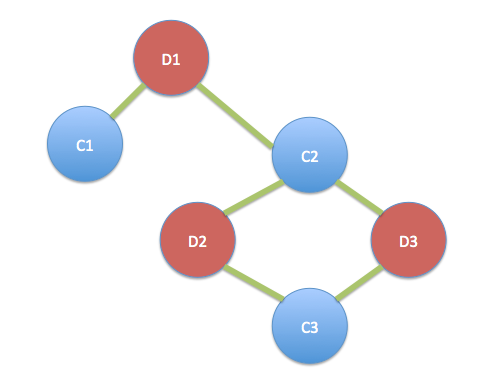
Eso significa que debemos ser capaces de generar grafos unimodales a lo largo de las siguientes líneas:
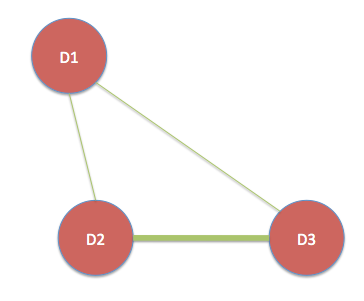
D1 está conectado a través de D2 y D3 C2 cliente (es decir, existe un enlace entre D1 y D2, y otro enlace entre D1 y D3). D2 y D3 se unen entre sí a través de dos rutas, C2 y C3. Así podemos ponderar el enlace entre D2 y D3 de ser más pesado, o más importante, que el enlace entre ambos D1 y D2, D1 y D3 o.
¿Y para los clientes?
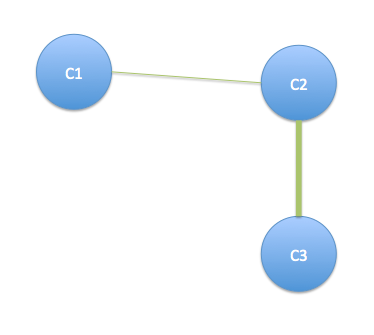
C1 está conectado a través de C2 acuerdo D1. C2 y C3 están conectados por un enlace ponderada más pesado que refleja el hecho de que ambos participaron en ofertas D2 y D3.
Usted se espera que sea capaz de imaginar cómo más complejos grafos de cliente-acuerdo podría colapsar en grafos al cliente en el cliente o el acuerdo de reparto donde hay grupos de clientes (u ofertas) basado en el hecho de que múltiples, desconectado (o sólo muy débilmente conectada) hay conjuntos de ofertas que no comparten ningún clientes comunes en absoluto, por ejemplo. (A modo de ejercicio, trate de dar con algunos grafos cliente-acuerdos y luego "colapso" a los grafos del cliente del cliente o contrato de acuerdo, que estén desconectados componentes.)
Entonces, ¿podemos generar grafos de este tipo utilizando Gephi? Bueno, da la casualidad que podamos, con la función de proyección multimodo Networks. Para empezar vamos a generar un par de espacios de trabajo que contienen el grafo original, menos las ofertas que no tenían clientes. Al seleccionar uno de estos espacios de trabajo, que ahora puede generar el grafo de acuerdo de reparto (vía común de los clientes) :
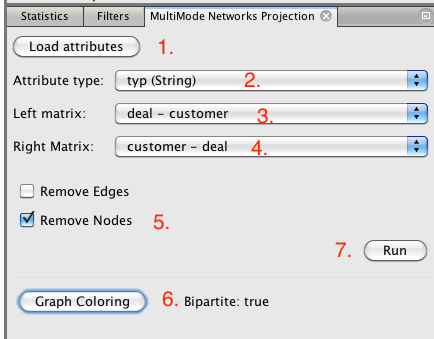
Cuando corremos la proyección, el grafo se proyecta sobre un grafo de oferta-oferta:

El espesor de los enlaces describe el número de clientes dos ofertas compartidos.
Si se corre la estadística de la modularidad sobre el grafo de acuerdos -acuerdos y el color del grafo por la partición de la modularidad, podemos ver cómo las ofertas se agrupan en virtud de tener clientes compartidos:

Si a continuación, vamos a filtrar el grafo de espesor en el enlace de manera que sólo se muestran los enlaces con un grosor de tres o más (tres clientes compartidos) podemos ver algunos cómo algunos de los tipos de trato mirada como si se agrupan en torno a determinadas comunidades sociales (es decir, se suministran a la misma serie de personas):

Si ahora vamos a la otra área de trabajo que hemos creado que contiene el grafo original (menos ofertas insatisfechas), podemos generar la proyección cliente-cliente:
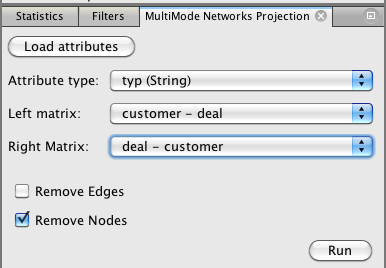
Ejecutar la estadística de la modularidad y recolour:

Si bien hay mucho que decir para el mantenimiento de la disposición espacial de manera que podamos comparar las diferentes parcelas, podríamos tener la tentación de volver a ejecutar el algoritmo de diseño para ver si el que se destacan las asociaciones estructurales más claramente? En este caso, no hay mucha diferencia:
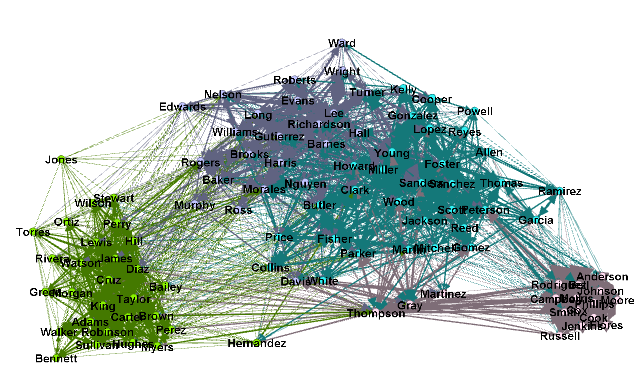
Si corremos el diámetro de la herramienta de red, podemos generar algunas estadísticas de red a través de esta red cliente-cliente:

Si ahora por tamaño los nodos de centralidad de intermediación, el tamaño de las etiquetas de los nodos proporcionales, y el uso de las herramientas de expandir / etiqueta de diseño de solapamiento de ajustar la pantalla, esto es lo que obtenemos:

Thompson parece ser un personaje interesante, que abarca los diversos grupos ... pero lo que en realidad está ofertas participando en? Si volvemos al grafo del cliente-acuerdo orignal, podemos utilizar un filtro para ver el ego:

Para buscar grupos sociales reales, podemos filtrar la red basada en el peso de enlace, por ejemplo, para mostrar sólo los enlaces por encima de un determinado peso (es decir, el número de ofertas compartidos), y luego dejar caer este conjunto en un nuevo espacio de trabajo. Si corremos el estadístico de Grado Medio, se puede calcular el grado de los nodos en este grafo, y el tamaño de los nodos en consecuencia. La retransmisión del grafo nos muestra algunas redes sociales corse basado en un número significativo de operaciones compartidas:

Esperemos que ahora que está empezando a "ver" cómo podemos empezar a tener una conversación visual con los datos, preguntas diferentes de la misma en base a cosas que estamos aprendiendo sobre él. Si bien es posible que tenga que mirar realmente a los números (y pestaña Laboratorio de Datos de Gephi nos permite hacer eso), me parece que la exploración visual puede proporcionar una forma rápida de orientación (orientador?) Usted mismo con respecto a un determinado conjunto de datos, y conseguir una sentir por el tipo de preguntas que pueden formularse de la misma, preguntas que bien podría implicar una consideración detallada de los mismos números reales. Pero para empezar, el recorrido visual a menudo funciona para mí ...
PS Hay un enlace al archivo de grafo de aquí, así que si quieres probar explorar por sí mismo, puede hacerlo :-)





