Virgile Juhan | JDN

La explotación de datos para mejorar el SEO fue uno de los principales temas de SEO Camp'us. Al final del día, dos retroalimentaciones instructivas, incluida la de Priceminister..
La explosión de datos también concierne a los SEO, y la explotación de este depósito de información está comenzando a madurar y tiene un fuerte impacto en la gestión del SEO. Esta es una de las lecciones que se pueden aprender de SEO Camp'us, el evento estrella de SearchBridge el 9 y 10 de marzo de 2017, del cual JDN fue socio.
"Los datos pueden provenir de Google y sus herramientas, como su webmaster. Pero también hay herramientas de terceros, tales Botify, Yooda o Majestic que puede proporcionar aún más datos. Cruzarlos a continuación, utilizando todos estos datos se utiliza para salir de una lógica empírica para la construcción de las estrategias impulsadas por datos-, "observó Olivier Tassel, consultor de NetBooster en su precisión en base a este tema de la conferencia (" empíricamente SEO a SEO de datos centrada en cómo su estrategia corporativa en 2017? "). Este especialista también señala que todos estos datos pueden ser monitorizados con soluciones personalizables de cuadros de mando muy flexibles y potentes, además de código abierto, como Superserie, desarrollado por Airbnb. Arriba: hábilmente explotados todos estos datos se pueden alimentar los sistemas de aprendizaje automático, y por lo tanto abierto a la senda predictiva.
Un DataViz para la detección de un fallo de funcionamiento
Para tomar un ejemplo la primera base, los datos de una herramienta útil SEO pueden ser explotadas por una solución DataViz para extraer rápidamente la atención a un problema importante. El caso fue presentado por Simon Georges, consultor de Makina Corpus. Este experto SEO Drupal y utilizó por primera vez el rastreo Screaming Frog herramienta para navegar por un sitio como Google haría. Gritando rana está en la lista que incluye las direcciones URL visitadas dentro de este sitio web. entonces esta lista se ha subido a la herramienta DataViz Gephi de código abierto. Y luego, sorpresa: si el sitio se supone que tiene tres secciones, una cuarta apareció muy claramente en el gráfico. la respuesta del propietario del sitio: "se ve como un tumor". Y eso es todo, de hecho.
DataViz realizado por Gephi que muestra 4 colores correspondientes a las cuatro partes de un sitio ... que se supone que hace que el recuento 3! © Simon Georges
Lo que pasa es que el sitio de la casa incluye un calendario de eventos. En esta agenda, no eran tan absolutamente clásico, un enlace "próximo mes" y "mes anterior". El rastreador se vio envuelto en un sinfín de estos enlaces. Volvió décadas atrás, y lo mismo antes. Esta es la cuarta sección del sitio, que aparece muy visual (púrpura aquí-contra) en Gephi, y por lo tanto en realidad corresponde a ... un calendario. "Luego, cuando se estudió el verdadero rastreo robot de Google, se confirmó que estaba tomando exactamente el mismo camino que el robot Screaming Frog. Por lo tanto, Google desperdiciando su tiempo para rastrear páginas sin ningún interés, mientras que para otras páginas con un gran potencial de SEO fueron descuidados o no del todo exploradas", lo que lleva Simon Georges.
SEO predictivo en PriceMinister
También hay ejemplos mucho más avanzadas en el campo de la minería de datos, predictivo y tendiendo a. SEO Priceminister Cecile Beroni, ha compartido su trabajo en el campo de datos grandes. Su entorno es uno de los sitios con alto volumen, un sitio con no menos de 24 millones de páginas, incluyendo 17 millones indexadas en Google. Por supuesto, SEO es altamente estratégica, con 30 a 40% de las visitas SEO (excluyendo consultas decir "marca", navegación).
Cécile Beroni, Priceminister SEO para SEO Camp'us © 2017 JDN
"Queríamos utilizar los primeros datos disponibles para mejorar la indexación de Google. El propósito era específicamente para aumentar el número de páginas indexadas o mejorar la rotación de URL rastreadas," resume SEO. Para este primer proyecto, el rastreo de Google es estudiado en profundidad, y cambios en el sitio para ayudar a guiar robots de Google ayudaron mucho mejor predecir qué páginas serán cubiertos. Un algoritmo de casa, confidencial, se ha desarrollado.
"Ahora sabemos que el 80% de las URL que Google rastree, mientras que en el principio era el 61%," dice SEO. "Al final, el número de páginas que se arrastró en realidad no ha aumentado. Especialmente la rotación viajó URL que ha sido mejorado." PriceMinister puede entonces "empujar" y almacenar millones de URL estratégicas - una cifra que tiende a limitar su caché solución sin barniz. "Anteriormente, Google podría obtener más de seis meses para recorrer todo el catálogo, ahora Google puede tener acceso a un mayor número de direcciones URL en un tiempo bastante corto. Este fue nuestro principio", recuerda Cécile Béroni.
Luego fue el blanco de una mejor predicción de palabras clave estratégicas "las principales palabras clave",. Para este proyecto, el sitio era capaz de confiar en un equipo interno (SEO, inteligencia de negocios, grandes volúmenes de datos), sino también en un proveedor de servicios externo, Authoritas, que proporciona gran cantidad de datos. Entre ellos: las palabras clave sobre la que se colocan Priceminister con su volumen de búsquedas y competidores que también están en sus resultados de búsqueda, entre otros. "Era necesario poner de relieve las oportunidades", dijo Seo. Ellos tomaron la forma de una lista bastante cruda de 2,4 millones de palabras clave que podrían apuntar sitio de comercio electrónico.
"A continuación, tuvo que trabajar en la lista, respondiendo a varias preguntas: ¿Tenemos el producto afectado por palabra clave ¿Cuál es la competencia para esa palabra clave, la presencia de Google Shopping también puede dar pistas interesantes de este tema ", detalla el empleado PriceMinister. Una vez que estos filtros producen, 1,4 millones de nuevas páginas de destino fueron creados o mejorados. El resultado anunciado por el sitio del comerciante es espectacular: 40% más de visibilidad en los resultados de reensamblaje de Google, según la herramienta de Searchmetrics.







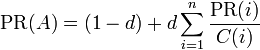
 es el PageRank de la página A.
es el PageRank de la página A.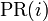 son los valores de PageRank que tienen cada una de las páginas i que enlazan a A.
son los valores de PageRank que tienen cada una de las páginas i que enlazan a A.