
martes, 20 de diciembre de 2022
jueves, 4 de agosto de 2022
Historia de la investigación de redes históricas (1/2)
Una (no tan) breve historia de la investigación de redes históricas – parte 1
Laboratorio de Humanidades Digitales
Leibniz-Institut für Europäische Geschichte

por
¡Prepárate para sumergirte en la historia de la investigación de redes históricas! En esta publicación (serie de tres partes), relataré la historia del pensamiento computacional en la investigación histórica, discutiré las redes para la historia y resaltaré algunas de las piedras angulares de las metodologías de redes en los estudios históricos. 1 Prepárese para la parte 1 sobre el pensamiento computacional en los estudios históricos.
Antes de comenzar esta rápida inmersión profunda (recuerde, la cantidad de aire necesaria aumenta a medida que aumenta la presión en 1 bar por cada 10 m de descenso. Por lo tanto, a 20 m de profundidad, necesitamos tres veces la cantidad de aire y podemos permanecer solo 1/3 del tiempo ¡como a nivel de superficie!), tenemos que revisar nuestro equipo.
Así que estoy prologando esto con un par de comentarios:
-
- Podemos definir la investigación histórica de redes como metodologías y enfoques del campo interdisciplinario de la investigación de redes (que a su vez combina aportes de sociología, antropología, estudios políticos, matemáticas e informática) para estudiar modelos de redes del pasado. Cuando estos están integrados en un contexto más amplio de investigación histórica, el análisis de redes históricas puede ayudar a generar una mayor comprensión y nuevos conocimientos sobre los objetos históricos de investigación.
- El análisis histórico de redes (HNA) y la investigación de redes sociales (SNA) utilizan el mismo conjunto de métodos y conceptos; esto también lo ha señalado mi colega Demival Vasques Filho en su reciente “Introducción al análisis histórico de redes (sociales)”. Pero HNA y SNA difieren en las fuentes utilizadas: para HNA, generalmente son fuentes históricas en la investigación histórica, mientras que las fuentes más contemporáneas de SNA se utilizan en los estudios sociales (como datos de redes sociales o datos generados solo con ese propósito, como a través de entrevistas o entrevistas). encuestas). La base de fuentes diferentes da como resultado (a veces) diferentes limitaciones de aplicaciones similares de redes dentro de los campos respectivos, como la fragmentación de fuentes.
- Las redes son gráficos anotados semánticamente con un conjunto de vínculos entre un conjunto de entidades “con la propiedad adicional de que las características de estos vínculos en su conjunto pueden utilizarse para interpretar el comportamiento social de las personas involucradas”, como en la definición comúnmente utilizada por Mitchell (1969, pág. 2). La investigación de redes se centra en la interdependencia de las entidades (Wasserman y Faust 1994, p. 4), que dan forma a su ámbito de acción: como tales ,la posición de una entidad en una red social es importante, ya sea por el poder, el rendimiento o el 'capital' del intercambio social potencial. Freeman (2004, p. 3) caracterizó la investigación de redes (sociales) como (a) el análisis (intuitivo) de las relaciones sociales de los actores, (b) el análisis sistemático basado en datos empíricos, (c) su representación gráfica, y ( d) modelo formal matemático asistido por computadora para analizar dichos datos. El requisito de un análisis formalizado dentro de la investigación de redes proporciona un punto clave en la evaluación de la investigación histórica de redes: un uso metafórico de la terminología de redes carece de tal sistematización. Pero más sobre esto más adelante.
- Quiero enfatizar aquí que las redes son inherentemente modelos . Como modelos, las redes ofrecen una aproximación a y de la realidad a través de la selección subjetiva (en el fondo siempre) de los factores o parámetros supuestamente importantes o representativos y su ponderación y evaluación subjetiva, siguiendo la clásica definición de modelos de Stachowiak (1973). Por lo tanto, el modelado es una herramienta epistémica fundamental: "Modelamos para comprender", parafraseó Le Moigne (2004) la toma de Stachowiak (1973, p. 56) de que todos los conocimientos son conocimientos en modelos o a través de modelos ( compárese tambiéna Piotrowski 2020, pág. 10). Sin embargo, como aproximaciones a la realidad, cualquier modelo está sesgado subjetivamente. En consecuencia, cualquier modelo puede considerarse solo una instancia de un "número infinito de otros modelos potenciales" (Rehbein 2020, p. 265), y como tal, ofrece más una 'muleta' pero nunca la 'verdad' sobre el objeto. de investigación Drucker (2011). Esta dicotomía de los modelos de red como una 'muleta' para aproximarse a la realidad (histórica) y el análisis formalizado de dichos modelos permiten una gama heterogénea de aplicaciones de la terminología y metodología de redes en la investigación histórica.
La historia de la investigación histórica en redes, en mi opinión, no puede caracterizarse como una genealogía: por lo general, los estudios históricos que emplean una metodología de redes no se construyeron progresivamente unos sobre otros (a menos que se hicieran dentro de grupos de investigación o asociaciones), sino que hacen referencia a los estudios metodológicos inaugurales de la investigación general de redes (sociales). Por lo tanto, contextualizaré la historia de HNR por sus dos influyentes corrientes de origen: por un lado, la larga historia del pensamiento computacional y los métodos basados en la computación en los estudios históricos (una historia mucho más larga de lo que a muchos les gustaría creer, y en parte 1 de esta serie de publicaciones de blog); y por dos, los desarrollos en el campo de la investigación de redes sociales (parte 2); antes abordaré las redes en la investigación histórica (parte 3).

Fig. 1. Clio, la musa de la historia, de Pierre Mignard, 1689, PD
El pensamiento computacional en la investigación histórica
Desde principios del siglo XX, la escuela francesa de los Annales proclamó que la entonces nueva historia social utilizaba tipos de fuentes previamente ignoradas (como los registros del censo) para comprender y cuantificar la experiencia de la gente 'ordinaria', en contraste con el estudio de las élites, conocido coloquialmente como la historia de los 'grandes hombres' (compárese, por ejemplo, con Reynolds 1998, pp. 141-2; Aydelotte 1966, Boonstra et al. [2004] 2006, p. 25; Anderson 2007; Crymble 2021, página 22). Esto evolucionaría, a raíz de la informatización, hacia el nuevo campo de la historia cuantitativa, también llamado 'cliometría' o 'econometría'.
Sin embargo, también hay ejemplos de estudios protocomputacionales de los siglos XVII y XVIII antes de la profesionalización de los estudios históricos (compárese, por ejemplo, con Gordon (1991) 2003; Novick 1988; Crymble 2021, pp. 20–7 ; Thaler 2017). La litografía de entrada de esta publicación es un ejemplo temprano de la visualización de datos de Charles Minard, y describe las pérdidas del ejército francés en su viaje a Rusia en 1812-13 en ubicaciones geográficas específicas y eventos temporales, lo que muestra la disminución de la fuerza del ejército en su camino hacia Moscú. (en rojo) y de regreso (en negro). Coincidentemente, también puede considerarse una visualización de red.
En la década de 1960, los enfoques computacionales basados en máquinas (que implicaban enfoques cuantitativos y análisis estadístico) se hicieron populares en las humanidades, luego bajo el nombre de 'computación de humanidades' o 'computación en humanidades'. Presagiando desarrollos futuros aquí ya: ¡Solo a principios de la década de 2000, la 'computación de humanidades' crecería hasta convertirse en 'Humanidades digitales' en el inicio de la digitalización masiva y el nacimiento de Internet!

Fig. 2. 'Harvard Computers' de Edward Charles Pickering, Archivos de la Universidad de Harvard, manifiesto IIIF
Esta expansión de la experimentación computacional en las humanidades fue el resultado de los avances tecnológicos en computación y la disponibilidad cada vez mayor de computadoras (humanas y no humanas) y software estadístico, que permitieron buscar patrones y generar nuevos conocimientos a través de la cuantificación utilizando máquinas (Hockey 2004, pág. 5;Crymble 2021, pág. 24). Las primeras computadoras eran estadísticas humanas, por lo general mujeres (ver, por ejemplo, la fotografía de las computadoras del astrónomo Edward Charles Pickering, a menudo astrónomos consumados); La investigación militar trajo avances en protocomputadoras de última generación en la década de 1940, como las máquinas lectoras de tarjetas perforadas, que nuevamente eran operadas en gran parte por trabajadoras.

Fig. 3. Betty Jennings (izquierda) y Frances Bilas (derecha), dos de las seis mujeres elegidas para trabajar como programadoras principales de ENIAC, organizando la configuración del programa en el programador maestro, 1947, Hagley Museum and Library, Wilmington.
Pronto, estos dieron paso a las computadoras centrales que llenaban la habitación, cuyo tamaño se redujo continuamente desde finales de la década de 1950, culminando en el desarrollo de la computadora personal portátil en la década de 1980 (compárese, por ejemplo, con Anderson 2007; Crymble 2021, pp. 21— 2; Petz 2022, pp. 17—8).). De la 'computación de humanidades' pronto surgieron subdisciplinas: por ejemplo, 'lingüística informática' (que posteriormente dio el salto a un campo de investigación independiente), o subcampos especializados como 'historia e informática' y 'ciencias de la información histórica'. (Boonstra et al. [2004] 2006).
Junto con los avances de la destreza computacional, e independientemente de los desarrollos en la 'computación de las humanidades', especialmente una generación más joven de historiadores recurrió a la historia cuantitativa ('cliometría') en su apogeo durante la década de 1960 hasta finales de la de 1970, como Whales (1991, p. . 296) ha demostrado. Esto fue facilitado por el mayor acceso a soporte técnico adecuado (Aydelotte 1966; Reynolds 1998, pp. 141-2; Boonstra et al. [2004] 2006; Anderson 2007), así como por el creciente interés en la historia social y económica en la profesión histórica general.
Aunque las metodologías cuantitativas se usaron en proyectos de investigación histórica y se discutieron en revistas tradicionales y conferencias especializadas, y se integraron en los planes de estudio universitarios (Anderson (2007) señaló que los métodos estadísticos han sido parte del 40% de los planes de estudio estadounidenses), también experimentaron resistencia y reacción contra su positivismo percibido por los estudios históricos más "ortodoxos", lo que finalmente llevó a su distanciamiento a mediados de la década de 1980, siguiendo de cerca las implicaciones del giro cultural postestructuralista y el cambio de enfoque hacia la naturaleza social de los textos del giro lingüista (Graham et al. al. 2016, p. 23; Petz 2022, p. 19). “Los textos reemplazaron a las tablas”, resumió este desarrollo Edward L. Ayers (1999), cuando la popular historia cuantitativa comenzó a reducirse a un nicho.
A partir de la década de 1980, las computadoras finalmente "penetraron en todos los campos imaginables de las humanidades", afirmaron Boonstra et al. ([2004] 2006, p. 13): la computadora personal y el correo electrónico se integraron lentamente en la vida del investigador en humanidades, y trabajar con computadoras se hizo en general más fácil y rápido debido a los avances en el procesamiento de archivos más rápido (Hockey 2004, pp. 9 –10). El advenimiento de Internet anunció una nueva era, seguida con el comienzo de la digitalización masiva a mediados de la década de 1990. Pero el hecho de que las computadoras estuvieran disponibles y fueran capaces de usarse para el análisis basado en computación y el procesamiento de texto no significaba (y todavía no significa) que muchos las usaran de esta manera.
En la próxima parte 2 de esta serie, desarrollaré el desarrollo y los supuestos subyacentes de la investigación general de redes (sociales), con el fin de unir esto para la investigación histórica de redes en la tercera entrega de esta serie.
Referencias
- Anderson, Margo. 2007. “Quantitative History.” In The SAGE Handbook of Social Science Methodology, edited by William Outhwaite and Stephen P. Turner, 248–264. London: Sage. doi:10.4135/ 9781848607958.n14.
- Aydelotte, William O. 1966. “Quantification in History.” The American Historical Review 71 (3): 803–825.
- Ayers, Edward L. 1999. “The Pasts and Futures of Digital History.” VCDH Virginia Center for Digital History (website). http://www.vcdh.virginia.edu/PastsFutures.html.
- Boonstra, Onno, Breure, Leen, and Doorn, Peter. [2004] 2006. “Past, Present and Future of His- torical Information Science.” (Amsterdam).
- Crymble, Adam. 2021. Technology and the Historian. Transformation in the Digital Age. Urbana, Chicago, Springfield: University of Illinois Press.
- Drucker, Johanna. 2011. “Humanities Approaches to Graphical Display.” Digital Humanities Quarterly 5 (1). http://www.digitalhumanities.org/dhq/vol/5/1/000091/000091.html.
- Freeman, Linton C. 2004. The development of social network analysis: a study in the sociology of science. Vancouver, BC: Empirical Press.
- Gordon, Scott. (1991) 2003. The history and philosophy of social science. Taylor & Francis e-Library.
- Graham, Shawn, Milligan, Ian, and Weingart, Scott. 2016. Exploring Big Historical Data. The Historian’s Macroscope. London: Imperial College Press.
- Hockey, Susan. 2004. “The History of Humanities Computing.” In A Companion to Digital Humanities, edited by Susan Schreibman, Ray Siemens, and John Unsworth. Oxford: Blackwell. http://digitalhumanities.org:3030/companion/view?docId=blackwell/9781405103213/9781405103213.xml&chunk.id=ss1-2-1
- Le Moigne, Jean-Louis. 2004. Le Constructivisme. Tome III. Mod ́eliser pour comprendre. Collection Ingénium. L’Harmattan.
- Mitchell, J. Clyde. 1969. “The Concept and Use of Social Networks.” In Social Networks in Urban Situations: Analyses edited by J. Clyde Mitchell, 1–50. Oxford: Published for the Institute for Social Research University of Zambia by Manchester University Press.
- Novick, Peter. 1988. That Noble Dream. The `Objectivity Question’ and the American Historical Profession. Cambridge University Press.
- Petz, Cindarella. 2022. “On Combining Network Research and Computational Methods on Historical Research Questions and its Implications for the Digital Humanities.” Dissertation at the TUM School of Social Sciences and Technology, Technical University Munich. http://mediatum.ub.tum.de/node?id=1624881.
- Piotrowski, Michael. 2020. “Ain’t No Way Around It: Why We Need to Be Clear About What We Mean by ”Digital Humanities”.” Preprint submitted for the Pproceedings of the Symposium “Wozu Digitale Geiteswissenschaft? Innovationen, Revisionen, Binnenkonflikte,” held at Leuphana University Lüneburg, Nov. 20 – 22, 2019. doi:10.31235/osf.io/d2kb6.
- Rehbein, Malte. 2020. “Historical Network Research, Digital History, and Digital Humanities.” In The Power of Networks. Prospects of Historical Network Research, edited by Marten Du ̈ring, Florian Kerschbaumer, Linda von Keyserlingk-Rehbein, and Martin Stark, 253–279. London New York: Routledge.
- Reynolds, John F. 1998. “Do Historians Count Anymore? The Status of Quantitative Methods in History, 1975–1995.” Historical Methods: A Journal of Quantitative and Interdisciplinary History 31 (4): 141–148.
- Stachowiak, Herbert. 1973. Allgemeine Modelltheorie. Wien, New York: Springer Verlag. https://archive.org/details/Stachowiak1973AllgemeineModelltheorie.
- Thaller, Manfred. 2017. “Geschichte der Digital Humanities.” In Digital Humanities: Eine Einführung, edited by Fotis Jannidis, Hubertus Kohle, and Malte Rehbein, 3–12. Stuttgart: J. B. Metzler.
- Wasserman, Stanley and Faust, Katherine. 1994. Social Network Analysis: Methods and Applications. 1st ed. Structural Analysis in the Social Sciences, 8. New York: Cambridge University Press.
- Whales, Robert. 1991. “A Quantitative History of the Journal of Economic History and the Cliometric Revolution.” The Journal of Economic History 51 (2): 289–301.
Citar este artículo como: Cindarella Petz, "Una (no tan) breve
historia de la investigación de redes históricas: parte 1", en
Digital Humanities Lab , 07/01/2022,
https://dhlab.hypotheses.org/3126 .
Créditos de la imagen: Imagen destacada: Charles-Joseph Minard: Carte figurative des pertes successives en hommes de l'armée française dans la Campagne de Russie 1812-1813. Régnier y Dourdet 1869. https://gallica.bnf.fr/ark:/12148/btv1b52504201x/f1.item.zoom# .
Fig. 3: Betty Jennings (izquierda) y Frances Bilas (derecha), dos de las seis mujeres elegidas para trabajar como programadoras principales de ENIAC, organizando la configuración del programa en el programador maestro, 1947. Información de archivo: 1985231_001_001_005, Cuadro 1, Carpeta 1, Sperry Corporation, fotografías y materiales audiovisuales de la División UNIVAC (Accesión 1985.261), Departamento de Iniciativas Digitales y Colecciones Audiovisuales, Museo y Biblioteca Hagley, Wilmington, DE 19807. https://digital.hagley.org/1985231_001_001_005 . Incluido como dominio público a través de Wikimedia Commons .
sábado, 9 de julio de 2022

{kind=link}
{kind=link}
.jpg){kind=link}
domingo, 26 de junio de 2022
Enlace: La distancia y la fortaleza de la amistad
¿Quieres amistades más cercanas? Aléjate de tus amigos.
Resulta que la distancia no es la barrera para las relaciones profundas que algunos pueden pensar.Por Maggie Mertens || The Atlantic

El viaje del amigo es una respuesta natural a nuestros avances tecnológicos. ( Alex Cochran )
Este artículo apareció en One Story to Read Today, un boletín en el que nuestros editores recomiendan una sola lectura obligada de The Atlantic , de lunes a viernes. Registrate aquí.
Las amistades adultas pueden ser difíciles de mantener. Las personas se alejan de su ciudad universitaria cuando termina la educación, comienzan las carreras y monopolizan nuestro tiempo, socializar en las horas felices puede comenzar a perder su atractivo a medida que envejecemos. Y durante la pandemia, cientos de miles de estadounidenses se mudaron de ciudades llenas de amigos a áreas menos pobladas. En consecuencia, las amistades cercanas que hemos cultivado desde la adultez temprana pueden parecer más propensas a terminar a medida que perdemos formas convenientes de mantenernos en contacto, como vivir en el mismo lugar. Pero los Millennials y Gen Zers se están casando y teniendo hijos más tarde que las generaciones anteriores (o evitando estos hitos por completo), además de redefinir su relación con el trabajo ., haciendo que las amistades sean más importantes. Resulta que la distancia ya no es la barrera que solía ser, gracias en parte a una forma en que algunos de nosotros mantenemos vivas estas relaciones: las vacaciones de amigos.
Un viaje para reunirse con amigos lejanos suele nacer del deseo de simplemente divertirse y tal vez revivir viejos recuerdos. Para Kathryn Stephenson, una reclutadora de ejecutivos de 31 años de Atlanta, eso solía ser cierto. Mientras vivía en Los Ángeles en 2017, Stephenson conoció a sus hermanas de la hermandad de mujeres de la Universidad de Oregón para pasar un fin de semana de vacaciones en Las Vegas. “Fue un fin de semana muy tonto, totalmente ridículo”, me dijo por teléfono. Pero el viaje fue más que vivir el libertinaje estereotípico de Las Vegas: descubrieron que viajar juntos era una manera de mantenerse auténticamente conectados.
Desde entonces, el trío se ha vuelto más deliberado acerca de nutrir su relación a larga distancia. Se conocieron en Minneapolis y en Bend, Oregón, y están pensando en otro viaje pronto. “En 10 años hemos tenido muchos cambios en la vida, desde la universidad hasta los 30, y nuestras interacciones se han vuelto más profundas”, dijo Stephenson. Y aferrarse a esas relaciones la ayuda a conocerse mejor. “Hay cierta superficialidad en la forma en que pensamos sobre la amistad en estos días; el mundo de Instagram o Facebook nos da esa sensación de necesitar más amigos, más de todo. Pero poder viajar para ver a buenos amigos demuestra que no necesitas una gran red; necesitas uno intencional”.
El viaje de amigos es una respuesta natural a nuestros avances tecnológicos, me dijo William Chopik, un psicólogo de personalidad social que dirige el Laboratorio de Relaciones Cercanas en la Universidad Estatal de Michigan. Gracias a las redes sociales y los teléfonos inteligentes que nos permiten enviar mensajes de texto, correos electrónicos y videollamadas a cualquier persona que deseemos, “las personas son más accesibles que nunca, pero no necesariamente más cercanas entre sí”, dijo. La cercanía real, según muestra la investigación de Chopik, a menudo proviene de oportunidades para la divulgación mutua; en otras palabras, compartir y escuchar profundamente. “Si va de viaje una o dos veces al año, tendrá muchas oportunidades de divulgación para actualizar a las personas sobre las cosas más importantes de su vida”.
Entonces, si bien puede ver a un amigo que vive cerca con más frecuencia, es posible que se quede sin cosas de las que hablar con ellos, según Chopik. Pero cuando rara vez ves a un amigo, y luego invertiste energía y dinero para pasar el rato, es probable que tengas una conexión más intensa durante ese tiempo: "Ese tipo de intención de escuchar a menudo ocurre en persona", dijo. . Stephenson está de acuerdo: “Soy terrible enviando mensajes de texto”, me dijo, y ella y sus amigos de larga distancia “no están en comunicación constante. Pero estos viajes son una especie de antídoto para tener que hacer eso”.
Los viajes intencionales con amigos, donde la gente se pone al día con los momentos más profundos de la vida, también pueden fomentar el tipo de conexiones profundas que muchos de nosotros pensamos que están reservadas para las reuniones familiares. Logan Rockmore, un ingeniero de software de 35 años de Brooklyn, reservó por primera vez un alquiler vacacional con un grupo de compañeros de trabajo/amigos cuando todos vivían en San Francisco en 2014. El grupo fue al río Russian River para el 4 de julio. y la pasaron tan bien que se fueron de vacaciones dos veces más ese mismo año. Hoy, Rockmore invita a más de 30 personas, que ahora viven en todo el país, a dos viajes al año, muchos de ellos en un lugar nuevo. Solo uno de los asistentes todavía trabaja en la empresa donde se reunió el grupo original. “A lo largo de los años, los amigos comenzaron a salir con nuevas personas y las trajeron al redil, y otros han traído nuevos amigos que han sido bienvenidos”, me dijo Rockmore por correo electrónico. Si bien el grupo grande incluye algunos de los amigos de Rockmore (y ahora su esposa) y algunas personas que, como él, actualmente viven en Nueva York, también hay personas a las que ve solo en estos viajes. “Pero incluso me siento muy cerca de [ellos] ya que tenemos una buena oportunidad de ponernos al día y hablar sobre cosas 'reales' mientras estamos allí... lo que creo que ayuda a contribuir a las vibraciones de Family Reunion y nos mantiene a todos muy unidos. ”
Muchas amistades a larga distancia también tienen la ventaja de parecer compromisos de alto riesgo. Al programar tiempo con un amigo cercano, por ejemplo, la cancelación puede no parecer un gran problema. Pero coordinar el tiempo de vacaciones y reservar una casa de alquiler con alguien es más difícil cuando las tensiones de la vida diaria se interponen en el camino. Ese es el caso de Catherine Hovell y su mejor amiga, Heather Ahearn, que nunca han vivido juntas en la misma ciudad. Hovell, una ingeniera estructural civil de 39 años de Seattle, se ha mudado a varias ciudades a lo largo de los años debido a su trabajo, lo que ha dificultado mantener amistades locales. Ella y Ahearn se conocieron en un viaje de 2006 donde ambos jugaron en un torneo de hockey, que luego se convirtió en un acontecimiento anual para ellos. Aún así, su amistad tomó tiempo para crecer. Cuando Hovell volvió a mudarse de ciudad a Montreal en 2015, hizo planes para ver con más frecuencia a Ahearn, que vivía a cinco horas en auto en Salem, Massachusetts. Desde entonces, han estado en viajes de fin de semana en Nueva Inglaterra y en vacaciones más largas y que requieren más tiempo: Islandia durante 10 días, Phoenix durante seis días y el Caribe dos veces. Hovell me dijo que la voluntad de Ahearn de aprovechar diversas oportunidades de viaje y vivir nuevas experiencias juntos ha ayudado a fomentar una relación profunda entre los dos. Tanto es así que Ahearn se ha convertido en la persona a la que Hovell llama cuando tiene que tomar una gran decisión en la vida: "Es básicamente mi esposo, mi familia y ella". Islandia durante 10 días, Phoenix durante seis días y el Caribe dos veces. Hovell me dijo que la voluntad de Ahearn de aprovechar diversas oportunidades de viaje y vivir nuevas experiencias juntos ha ayudado a fomentar una relación profunda entre los dos. Tanto es así que Ahearn se ha convertido en la persona a la que Hovell llama cuando tiene que tomar una gran decisión en la vida: "Es básicamente mi esposo, mi familia y ella". Islandia durante 10 días, Phoenix durante seis días y el Caribe dos veces. Hovell me dijo que la voluntad de Ahearn de aprovechar diversas oportunidades de viaje y vivir nuevas experiencias juntos ha ayudado a fomentar una relación profunda entre los dos. Tanto es así que Ahearn se ha convertido en la persona a la que Hovell llama cuando tiene que tomar una gran decisión en la vida: "Es básicamente mi esposo, mi familia y ella".
Sin embargo, en última instancia, el simple hecho de planificar un viaje con un amigo no los convertirá mágicamente en mejores amigos. Chopik dice que hay un predictor importante de si una amistad será satisfactoria: "La conveniencia de tener un amigo a unas cuadras de distancia, o si un amigo es alguien a quien conoces desde hace 20 años, nada de eso es tan importante como si te gusta pasar tiempo con ellos”. Como dijo Hovell, no importa si ella y Ahearn están en una playa haciendo crucigramas o haciendo turismo en el extranjero. Está dispuesta a viajar a donde sea para ver a Ahearn, porque la parte importante es "simplemente la persona". Chopik señaló la evidencia de su laboratorio de investigación que muestra que más personas dicen que priorizarán a los amigos en lugar de encontrar un compañero de vida. Y aunque una escapada de amistad a veces puede parecer una indulgencia personal frívola,
jueves, 23 de junio de 2022
Analizando datos con Graph Commons
Análisis de redes de datos
Burak Arikan
El análisis de datos con métodos visuales lo ayuda a obtener una mejor comprensión de la complejidad. Ya sea que indague en una base de datos filtrada, investigue las interacciones entremezcladas de un ecosistema, administre su organización en red o organice un gran archivo, comienza a dar sentido a un problema complejo al mapear sus actores y relaciones. Como un proceso de pensamiento fundamentalmente humano, el mapeo nos ayuda a navegar vínculos particulares entre los actores mientras vemos los patrones en un panorama más amplio y obtenemos información a lo largo de este viaje. Hemos estado adaptando interfaces y procesos para que esa experiencia sea lo más intuitiva posible en la plataforma Graph Commons. 
Comienza analizando un mapa de red examinando su centralidad y métricas de agrupación. La red se organiza a sí misma mediante una simulación basada en la física entre nodos vecinos, jalándose y empujándose unos a otros como resortes. Este proceso de organización del diseño revela los actores centrales y periféricos, los enlaces indirectos, los grupos orgánicos, los nodos puente y los valores atípicos que de otro modo no vería.
Mientras navega por un mapa de red, reconoce visualmente los nodos más conectados a partir de sus líneas de entrada y salida, que establecen conexiones específicas entre partes de la imagen, mientras descartan otras. El tamaño de fuente y círculo indica la importancia relativa de cada nodo. Observa los grupos de nodos estrechamente interconectados. Los nodos puente entre dos o más clústeres se vuelven claramente visibles. Sin embargo, cuando un mapa de red se hace más grande, el nivel de detalle abruma nuestros sentidos. Para examinar y comparar dichas cualidades con precisión, necesita vistas más cuantitativas de los datos contenidos en el grafo.
Red de Sistemas Penales (2013)— Un mapa de red de países vinculados a temas jurídicos ya sea que se ejerzan o no en su derecho.
La interfaz gráfica actual en Graph Commons proporciona una experiencia continua de cambiar de lo particular (un nodo específico y sus relaciones inmediatas) a lo general (ver la red más grande) y viceversa. Creemos que este ciclo te ayuda a crear un marco de referencia útil en tu mente para digerir la complejidad. Para respaldar esta experiencia cualitativa con métodos cuantitativos, hemos desarrollado una nueva característica que simplemente llamamos "Analysis".
De un grafo a una lista, luego a un gráfico
Para obtener un resumen de los nodos más importantes en un gráfico, abra la barra de Análisis, donde verá una lista de los nodos principales ordenados por sus métricas, como el número de conexiones, la centralidad de intermediación y propiedades numéricas como la edad, también como la frecuencia de propiedades nominales como el día de la semana. Desde una lista, abre un gráfico para ver la distribución de todos los nodos por una determinada métrica, lo que proporciona un análisis comparativo de un gráfico de dispersión típico.
Identifique clústeres en su red
Una tarea común de análisis en redes es descubrir los grupos orgánicos o comunidades en base a las conexiones entre los nodos de la red. La idea es encontrar grupos de nodos que tengan más conexiones entre sí que con los extraños.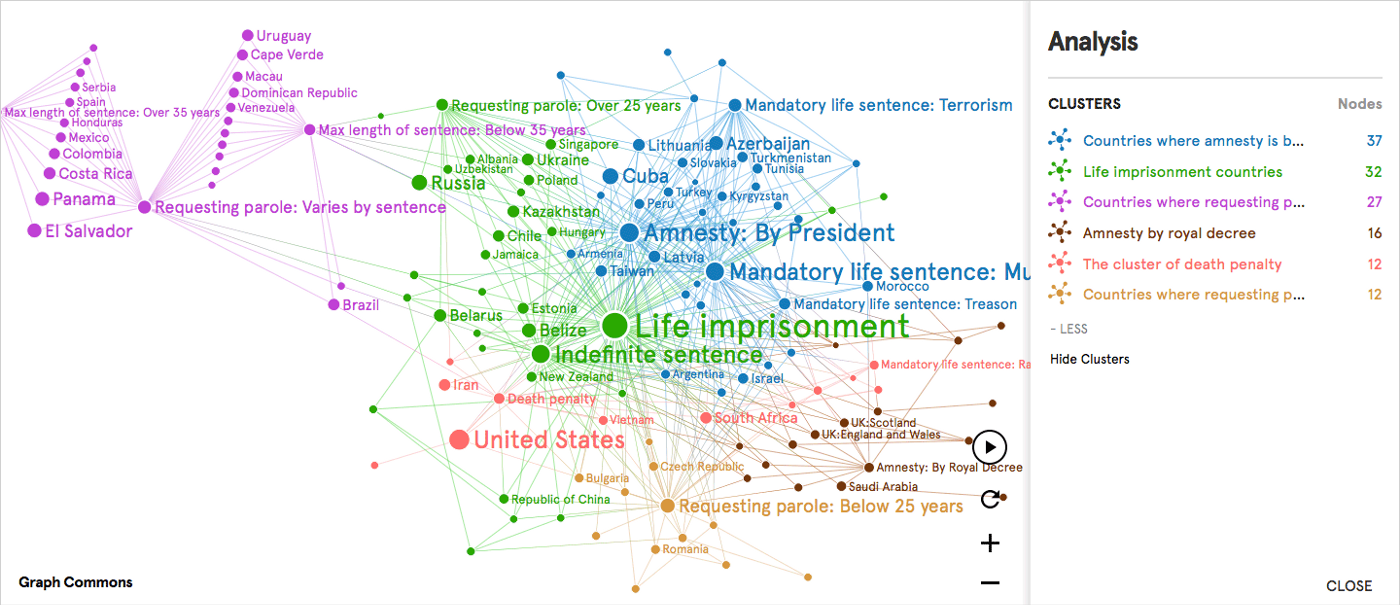
Mostrando 6 clusters por color identificados en la red
Con la función "Clustering" en la barra de análisis, puede identificar grupos orgánicos en su red. Cuando ejecuta el proceso de agrupamiento, aplica el algoritmo de modularidad de Louvain y encuentra los grupos muy unidos caracterizados por una densidad de vínculos relativamente alta.
Cuando se detectan clústeres, es importante resaltar su importancia dentro de la red más grande. Por lo tanto, se etiquetan automáticamente en función del nodo más conectado del clúster. Sin embargo, le recomendamos encarecidamente que cambie el nombre de estas comunidades usted mismo para resaltar lo que estas comunidades especifican en su red.
La “Red de Sistemas Penales” (visto arriba), es un mapa de red de países en relación con temas jurídicos como cadena perpetua, libertad condicional, sentencia indefinida y amnistía. Al mostrar si estos temas se están ejerciendo o cómo, proporciona una comparación de sanciones a escala entre países y sistemas legales.
Cuando aplicamos el análisis de conglomerados, muestra los siguientes conglomerados, que están etiquetados por el nodo más central dentro de un conglomerado determinado:
- Países donde la amnistía es otorgada por un presidente
- Países con cadena perpetua
- Países donde la solicitud de libertad condicional varía según la sentencia
- Amnistía por real decreto
- El cúmulo de la pena de muerte
- Países donde solicitar libertad condicional es menor de 25 años
La agrupación de estos países y los sistemas de penas están en línea con la distinción de las tradiciones legales. Los países de derecho consuetudinario (desde EE. UU. hasta el Reino Unido y sus antiguas colonias), los países de derecho civil (Europa, América Latina, Asia y más allá) y la combinación de países de derecho civil y religioso (en parte, Oriente Medio y África del Norte ) se encuentran cerca uno del otro en el diagrama de red.
Lista de actores y vínculos importantes
Según el tipo de red, algunos nodos pueden tener posiciones relativamente más importantes que otros. En algunas situaciones, los nodos importantes pueden definirse como centrales para la red cuando tienen muchas conexiones, o como puentes entre dos comunidades. Los nodos puente pueden ser importantes porque su eliminación puede dividir la red en partes o se vuelven demasiado poderosos, ya que son el intermediario del flujo de información entre las comunidades.
Estados Unidos tiene la tasa de encarcelamiento más alta del mundo.
En la barra de análisis, puede enumerar los nodos principales por una propiedad numérica, en este caso, esta es una lista de países por tasas de encarcelamiento (prisioneros por cada 100 000 habitantes). Los datos de este gráfico son de 2013, Estados Unidos tenía la tasa de encarcelamiento más alta del mundo, seguido de Cuba, Rusia, El Salvador, Azerbaiyán y Belice. Los principales países actuales con altas tasas de encarcelamiento no cambiaron drásticamente. Como ves en la captura de pantalla anterior, en la lista puedes hacer clic en un país y resaltarlo para ver sus conexiones.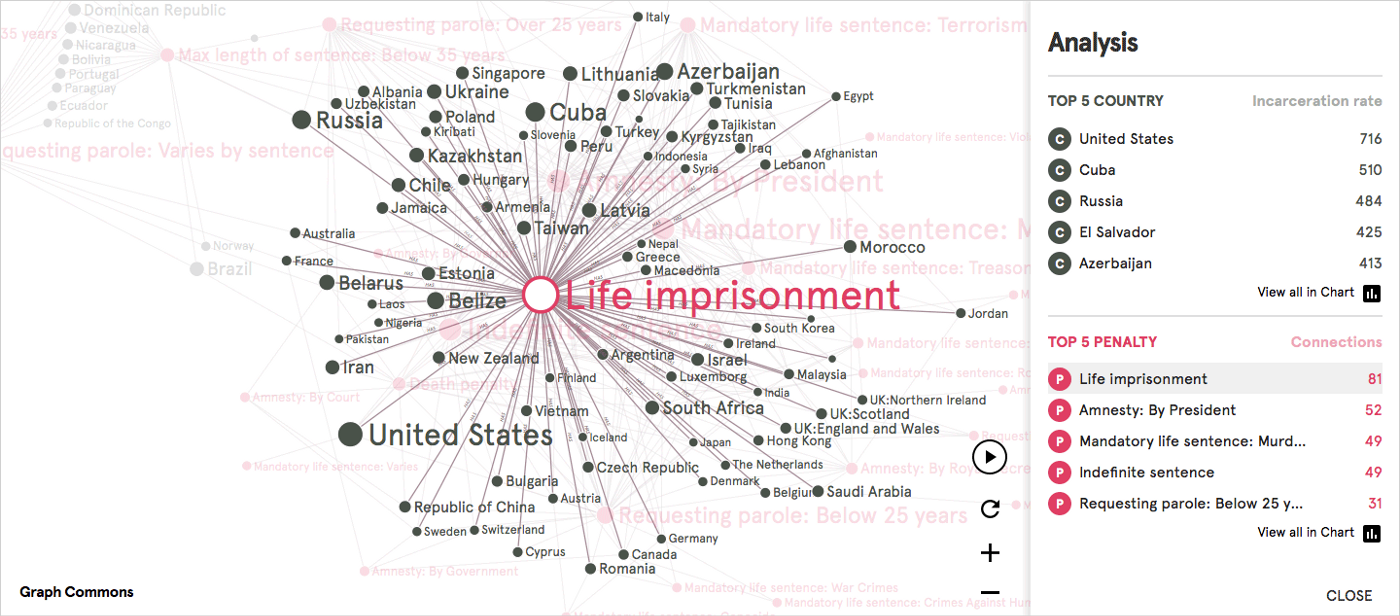
La cadena perpetua existe en la mayoría de los países. Se hace clic en la penalización de la lista para resaltar sus conexiones/países.
En esta red tiene sentido enumerar las penalizaciones por número de conexiones, ya que podemos conocer las penalizaciones más comunes entre estos países. La “cadena perpetua” es la más común, seguida de la “amnistía del presidente” y la “cadena perpetua por asesinato”. Es bastante preocupante ver que la pena de “Sentencia indefinida” aún se aplica en 49 países del mundo.
Las listas proporcionan un resumen de los nodos más importantes de un gráfico. Al hacer clic en un nodo de la lista, verá dónde se encuentra en la red junto con sus conexiones resaltadas.
Comparar distribuciones en gráficos
Cuando está mapeando, a menudo descubre patrones que no sabía que existían antes. Ver la distribución de todos los actores le brinda una vista cuantitativa completa de todos los nodos ordenados por propiedad, para que comprenda mejor qué actores son más importantes que otros según las métricas que elija mirar. Cuando abre un gráfico, ve la distribución de todos los nodos en un gráfico de dispersión, que proporciona un análisis comparativo de los nodos en dos ejes.
Distribución de países por tasa de encarcelamiento. A partir de esta distribución de cabeza gruesa, podemos decir que muchos países tienen altas tasas de encarcelamiento. Para ver los gráficos interactivos, haga clic en el enlace "View in Chart" en la barra de análisis.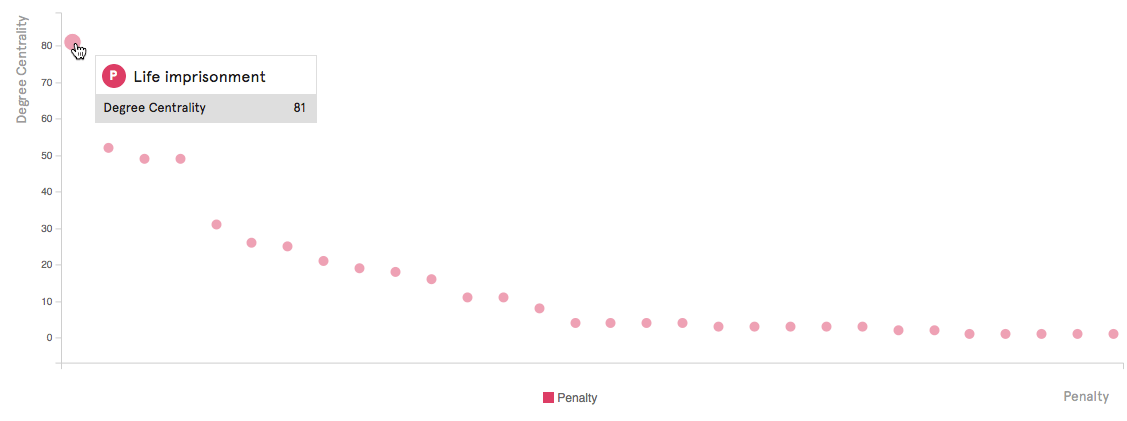
La distribución de penalizaciones por grado de centralidad (número de conexiones), que se muestra arriba, sigue ligeramente el típico diagrama de ley de potencia que se observa en las redes sin escala.
La distribución de sanciones por centralidad de intermediación se muestra arriba. Las primeras 2 y las siguientes 4 penalizaciones tienen valores de centralidad de intermediación distintivamente altos, lo que significa que tienen la mayor calidad de puente entre los diferentes grupos.

Arriba se muestra una comparación de las sanciones por grado (eje y) y valores de centralidad de intermediación (eje x). La “prisión perpetua” tiene con diferencia los valores más altos en ambos grados. En general, esta comparación es útil para encontrar valores atípicos, lo que no es realmente el caso en esta red en particular.
El uso de una interfaz híbrida que emplee mapas visuales, listas y gráficos le ayudaría a obtener una visión más profunda al analizar redes complejas.
sábado, 14 de mayo de 2022
Análisis técnico de memes y su difusión
¿Qué es un meme, técnicamente hablando?
Digital Methods InitiativeExplorando la tecnicidad de los memes en diferentes entornos digitales
Miembros del equipo
Alberto Olivieri, Alexander, Alice Noris, Andre Theng, Anton Berg, Anunaya Rajhans, Artur Holiavin, Chloë Arkenbout, Giovanni Daniele Starita, Kristen Zheng, Marcantonio Bracale, Marco Valli, Nabeel Siddiqui, Nina Welt, Octavian, Samson Geboers, Swati
Facilitadores: Prof. Richard Rogers, Dra. Janna Joceli Omena, Giulia Giorgi

Resultados clave
-
Los entornos de software afectan en gran medida la conceptualización y la estética de los memes. De hecho, los géneros y formatos dominantes suelen variar según la plataforma de la que se extraen.
-
El análisis visual revela un espectro de formatos, cuya presencia y frecuencia en los entornos de software puede oscilar considerablemente: por ejemplo, Imgur contiene la mayor cantidad de macros de imágenes, a diferencia del conjunto de datos extraído con CrowdTangle , en el que casi no estaban.
-
En general, las capturas de pantalla de los tweets son el formato de memes que se presenta con mayor frecuencia, cruzando transversalmente los cuatro entornos de software considerados en el análisis.
-
Además del análisis visual, las redes de visión por computadora pueden contribuir a la ontología memética. Mientras que la centralidad de la red de las entidades web dominantes captura lo que es un meme, identificando componentes pre-meméticos como 'texto', 'imagen', 'captura de pantalla', 'título', 'dibujo', 'dibujo', 'cita', las zonas periféricas de la red muestran las peculiaridades del meme ligado a entornos web específicos. Finalmente, los grupos de 'puente' revelan las entidades asociadas con dos o más plataformas para clasificar sus imágenes de memes covid. En general, el análisis revela cómo las diferentes plataformas vernáculas dan forma a las culturas de los memes, arrojando luz sobre lo que es común entre dos o más plataformas, y lo que falta o está ausente.
1. Introducción
La investigación que llevamos a cabo durante la Escuela de Invierno de Métodos Digitales 2022 ofrece una descripción de cómo se identifican y detectan los memes dentro y entre diferentes entornos de software, contribuyendo así al campo más amplio de la investigación de memes. Más específicamente, este trabajo tiene como objetivo mapear la composición técnica de las imágenes meméticas y cómo este tecnicismo se relaciona o es específico de uno o varios entornos de software. El proyecto se basa en un artículo de investigación reciente, "¿Qué es un meme, técnicamente hablando?" (Rogers y Giorgi, en revisión), que concibe los memes como colecciones de artefactos moldeados por el software que los genera.
La investigación existente entiende los memes como artefactos culturales multimodales, que los usuarios crean, remezclan y hacen circular a través de plataformas digitales (Shifman, 2014; Milner, 2016; Davison, 2012). Su origen se remonta a los espacios digitales marginales y, hasta principios de la década de 2010, eran una prerrogativa de las comunidades subculturales que poblaban sitios web como 4chan y Reddit (cfr. Zanettou et al., 2018). Sin embargo, se ha hecho evidente que la relevancia de los memes también se ha extendido a los principales medios digitales, ya que se han convertido en una “práctica ubicua, posiblemente fundamental, de los medios digitales” (Miltner, 2018, p. 412). En este sentido, los memes se consideran un género completo, con conjuntos de reglas y convenciones definidas sociológicamente (Wiggins y Bowers, 2015).
En particular, los académicos han puesto énfasis en diferentes aspectos de los memes, como su tipología (Shifman, 2013; Laineste y Voolaid, 2016; Dynel, 2016), su circulación viral (Spitzberg, 2014) y su papel en diferentes entornos subculturales (Nissenbaum & Shifman, 2017; Miltner, 2018). Además del enfoque vernáculo, un aspecto interesante y relativamente poco estudiado consiste en la exploración de la tecnicidad, materialidad y relacionalidad de los memes ligada a las especificidades de la plataforma. Como lo describe Niederer (2019), esta “tecnicidad del contenido” está delimitada y co-constituida por el portador que los proporciona (p. 18). En este sentido, el punto de partida del presente trabajo es la definición de los memes como productos resultantes de una combinación de posibilidades técnicas, prácticas convencionalizadas y cultura participativa digital.
Tomando prestado el término 'tecnicidad' (Niederer & Van Dijck, 2010) para capturar la idea del meme como 'compuesto tecnológicamente' o 'co-constituido' por su entorno de software (Bucher, 2012), nos dispusimos a investigar los memes como productos en línea que pueden etiquetarse y recopilarse en bases de datos, software de creación de medios o generadores, identificados y etiquetados por software analítico y de visión y devueltos por 'búsqueda de memes' en paneles de datos de investigación y marketing. Cada software genera una colección de memes peculiar, destacando ciertas características y eclipsando otras. Es decir, las colecciones de objetos técnicos representados por los entornos de software tienen diferentes características que dependen de si se acumularon a través de una base de datos, plantillas, análisis, coincidencias u otra lógica. En esta luz,
3. Preguntas de investigación
Siguiendo el marco teórico esbozado anteriormente, esta investigación busca dar respuesta a estas preguntas de investigación:
-
¿Cómo contribuye el entorno de software en el que se delimitan los memes a dar forma a diferentes colecciones de memes?
-
¿Cómo afecta esa creación de conjuntos o colecciones a la investigación de memes?
A través de este estudio empírico, pretendemos mostrar que diferentes entornos de software contienen una lógica diferente a la formación de colecciones de memes. Con esto en mente, formulamos la siguiente hipótesis: las colecciones de objetos técnicos generados por los entornos de software tienen características únicas que dependen de si se acumularon a través de una base de datos, plantillas, análisis, coincidencias u otra lógica.
4. Conjuntos de datos iniciales
Selección de casos. La base de datos para esta investigación fue ensamblada por participantes de la Escuela de Invierno mediante la recopilación de imágenes en cuatro entornos de software seleccionados. Nuestra selección de plataformas, que podría describirse como una forma de muestreo de máxima variación (Etikan et al., 2016) con un enfoque en la diversidad y heterogeneidad de casos, incluye:
-
CrowdTangle, una herramienta de marketing de la empresa Meta (ex Facebook), que se empleaba para extraer datos de Instagram y Facebook;
-
Imágenes de Google;
-
Imgur, un generador digital que proporciona plantillas para macros de imágenes;
-
KnowYourMeme, uno de los repositorios de memes más antiguos y conocidos.
Recopilación de datos. Para capturar representaciones contemporáneas de lo que puede constituir un meme según estos entornos de software y enfatizar la comparabilidad, decidimos recopilar contenido memético en torno al tema de la pandemia de Covid-19, ya que lo consideramos un contenido altamente mediatizado que ha dado lugar a un intensa producción de contenido en diferentes plataformas (Murru y Vicari, 2021). Para mejorar aún más la operatividad de los resultados de las imágenes, la recopilación de datos se centró en el contenido en inglés (Pearce et al. 2018). Para garantizar un entorno de software "inglés", se utilizaron redes privadas virtuales, imitando un sistema basado en la ubicación en los Estados Unidos (Rogers, 2019).
Para ello, buscamos las palabras clave "covid meme" en las plataformas seleccionadas. El tablero de datos de marketing CrowdTangle ofrece la opción de "búsqueda de memes", donde se puede consultar contenido memético en Facebook e Instagram. Además, el tablero nos permite filtrar el idioma (seleccionamos "Inglés") y el tipo de contenido (seleccionamos "Fotos" para Facebook y "Fotos" y "Álbumes" para Instagram). Datos de Google Imágenes, Imgur y Know Your Meme se recopilaron con la herramienta ImageScraper (disponible en GitHub ). El rango de tiempo para los resultados de la búsqueda se restringió al año 2021.
Muestreo del conjunto de datos. Submuestreamos los datos extraídos con CrowdTangle de Instagram y Facebook, eligiendo las primeras 1000 imágenes ordenadas por el número total de interacciones (uno de los metadatos predeterminados proporcionados por CrowdTangle ). Para Imgur y Know Your Meme, se seleccionaron las primeras 1000 imágenes del resultado de la búsqueda, ordenadas por la calificación de interacción de los sitios web. El conjunto de datos de imágenes de Google consta de los primeros 500 resultados de imágenes debido a las limitaciones del alcance de la investigación. La Figura 1 detalla la composición de cada submuestra en términos del número de elementos considerados por entorno de software.

Figura 1. Proceso de creación de conjuntos de datos
5. Metodología
Nuestra investigación toma la forma de un análisis comparativo, destinado a revelar cómo los diferentes entornos de software identifican y agrupan los memes de manera diferente. Mediante el uso de métodos y herramientas digitales como ImageSorter y Google Vision, los memes recopilados se clasifican según sus propiedades formales, visuales y de contenido, lo que da como resultado un conjunto de formatos de memes, algunos más específicos de la plataforma que otros. Lo que un entorno de software representa como un meme diferencia de un entorno a otro. Por ejemplo, lo que Imgur enumera como un meme difiere de lo que Facebook o Instagram consideran como un meme al mirar sus mejores resultados. Estos contrastes se suman al argumento de Rogers y Giorgi (bajo revisión), de que el entorno del software contribuye a dar forma a las colecciones de memes.
El análisis de los datos digitales consistió en dos secciones de trabajo empírico, realizadas respectivamente por dos subgrupos diferentes de participantes. Específicamente, el análisis realizado por el Grupo 1 se basó en el análisis visual (Rogers, 2021), mientras que el Grupo 2 adoptó un enfoque de red de visión por computadora (Omena et. al. 2021; Omena 2021). En el resto de esta sección, ilustraremos ambos procedimientos metodológicos.
Grupo 1 - Exploración de colecciones de memes a través de un software de análisis visual automatizado. Tomando cada submuestra por separado, empleamos el software ImageSorter para analizar visualmente las colecciones devueltas por los cuatro entornos (Rogers, 2021). Al organizar las imágenes con ImageSorter por tono y color, la herramienta nos permitió identificar tanto grupos homogéneos de imágenes (Warren Pearce et al., 2018) como imágenes que se repiten con frecuencia. Contextualmente, también pudimos distinguir entre copias exactas e imágenes similares (Rogers, 2021). Luego profundizamos en el análisis de las similitudes y diferencias de los conglomerados, realizando una lectura atenta de las muestras, con foco en tres rasgos característicos:
-
Tipos de Imágenes Dominantes: qué tipologías de imágenes ocurrieron más en cada muestra, en términos de imágenes similares y copias;
-
Ontología: qué elementos materiales y estéticos caracterizaron cada plataforma;
-
Epistemología: lo que constituye un meme para cada plataforma a partir de las respectivas imágenes de cada muestra.
Además, con la ayuda de Memespector GUI (Chao, 2021), analizamos los metadatos de la imagen para extraer los sitios web donde se encontraron imágenes totalmente coincidentes. Esto nos ayudó a contextualizar la circulación de imágenes en la web (Omena et. al. 2021), para evaluar en qué medida cada submuestra resultó de imágenes relacionadas con otras plataformas o se compartieron principalmente en la misma plataforma de la que las extrajimos.
Grupo 2 - Exploración de colecciones de memes a través de la visión artificial. En un segundo nivel de análisis, seguimos un enfoque de red de visión por computadora (Omena et. al. 2021; Omena 2021) para estudiar las colecciones de imágenes capturadas en diferentes entornos de software. Se requirió una variedad de herramientas y software de investigación para implementar este método, como DownThemAll (Maier, Parodi & Verna, 2007), Memespector GUI (Chao, 2021), Google Spreadsheets, Table2Net y Gephi (Bastian, Heymann & Jacomy, 2009). ).
Construimos una red con salidas de visión por computadora (detección web Google Vision AI, es decir, entidades web) para nuestra colección de imágenes, creando nodos como plataformas (Facebook, Instagram, Imgur y KnowYourMeme ) y entidades web. Las entidades web pueden describirse como una cosa, una persona, un lugar (ubicación) o el nombre de una organización/evento detectado y reconocido en contenido basado en Internet. En nuestro contexto, proporcionaron referencias contextuales y culturales a nuestras colecciones de imágenes, pero yendo más allá del contenido de las imágenes mismas (Omena et. al. 2021). Sin renderizar las imágenes dentro de la red, pudimos dar sentido a la materialidad de los memes al observar las entidades web dominantes (centro de la red) y los contextos culturales específicos de los memes a través de las zonas periféricas de la red y los grupos de entidades web puente.
En la exploración y análisis visual de la red (Venturini, Jacomy & Jensen, 2019), nos enfocamos en las zonas fijas de la red, pero entendiendo el significado de la posición y el tamaño del nodo para el análisis de imágenes (ver Omena & Amaral, 2019). En la red a continuación, el tamaño del nodo de la plataforma significa el total de entidades web asociadas con la colección de imágenes de memes que provienen de una plataforma. El tamaño del nodo de la entidad web significa la cantidad de veces que se usó una entidad determinada para describir una o más imágenes (considerando todas las imágenes que provienen de diferentes plataformas). Siguiendo las posibilidades del algoritmo de diseño gráfico ForceAtlas2 (Jacomy, Venturini, Heymann & Bastian, 2014), la siguiente tabla explica la posición del nodo y cómo interpretamos la red.


Figura 2. ¿Cómo leer una red de plataformas y entidades web asociadas a imágenes de memes covid? Tabla explicativa y descriptiva (arriba) y visualización de red gif (abajo).
6. Hallazgos
6.1 Exploración de colecciones de memes a través de software para análisis visual automatizado.
Los principales hallazgos generados por el enfoque de análisis visual ilustrado en la sección de métodos se visualizan en la Figura 3. Como se ilustra en la barra de espectro superior, hubo varios formatos de imagen en los conjuntos de datos. Cuando se combinaron todos los conjuntos de datos, las capturas de pantalla de los tweets fueron el formato más dominante: una mirada más cercana reveló que este formato predominaba en CrowdTangle , mientras que el conjunto de datos de Imgur contenía la menor cantidad de ocurrencias, como se ilustra en la segunda barra de espectro en la Figura 3. Si bien algunos de los conjuntos tenían formatos superpuestos, también había distinciones claras entre ellos. Mirando las especificidades de la plataforma, la mayor cantidad de macros de imágenes (es decir, imágenes con texto sobre una imagen y generalmente vistas como un formato de meme tradicional) se encontró en Imgur, mientras que CrowdTangle (Facebook e Instagram) contenía la menor cantidad de macros de imágenes. Por su parte, el conjunto de datos recuperado de CrowdTangleformatos destacados como retratos (imágenes de prensa de personas famosas, portadas de revistas y selfies), imágenes de texto de redes sociales (texto sin formato que está formateado en un diseño específico con colores específicos como una imagen para Historias de Instagram o publicaciones de Facebook, por ejemplo), redes sociales tarjetas de declaración (información que está formateada con texto e imágenes, para noticias o citas inspiradoras, por ejemplo) e infografías (que a menudo contienen gráficos y tablas). KnowYourMeme incluía múltiples plantillas de macros de imágenes (imágenes sin texto que se utilizan en los generadores de memes) y logotipos, mientras que los datos de Google Image mostraban imágenes de mercancías.Al observar la aparición de imágenes, surge que las muestras extraídas de los conjuntos de datos de Google Images e Imgur contienen una cantidad significativa de imágenes similares. Estos conjuntos también presentaban una cantidad relativamente pequeña de imágenes iguales (duplicados), que en su mayoría eran macros de imágenes.
Al observar estos resultados, se puede argumentar que los entornos de software afectan en gran medida los conjuntos de imágenes recopilados. De hecho, los géneros dominantes de imágenes tienden a variar según la plataforma de la que se extraen. Si uno considerara como memes solo los formatos presentes en todos los conjuntos de datos, entonces los memes serían capturas de pantalla de tweets.

Figura 3. El espectro de formatos de memes y su circulación en la web.
6.2 Exploración de colecciones de memes a través de la visión artificial.
La detección de entidades web de #Google Vision como una herramienta precisa para identificar memes
La siguiente imagen-pared se genera con la técnica de reducción de dimensionalidad UMAP y se agrupa mediante PixPlot. Como puede ver, cómo las entidades web de Google Vision son sorprendentemente precisas en la identificación de memes, superando a Crowdtangle. Todas las imágenes tienen 'meme' en su descripción de entidad web, y la clasificación devuelve todos los memes de facto, construidos a través de plantillas familiares y macros de imágenes. La precisión de Google Vision al separar los memes de los que no son memes destaca la especificidad del medio de los memes: son colecciones digitales nativas, co-constituidas por los entornos de software en los que se difunden y circulan. De hecho, la detección de entidades web considera los sitios de circulación entre sus parámetros, mejorando así su precisión de clasificación. En otras palabras, si una imagen circula en un entorno memético y es parte de una extensa colección de imágenes similares, entonces esta imagen es probablemente un meme. Por lo tanto,
Figura 4. Uso de Pixplot para interrogar la precisión de las entidades web para la identificación de memes.
#Redes de visión por computadora para dar sentido a la colección de imágenes de memes
Las redes de visión por computadora se construyen sobre las características de visión por computadora, como la clasificación de imágenes y la detección de entidades web. Aquí utilizamos la detección de entidades web, yendo más allá y detrás del contenido de la imagen inmediata, y utilizando el entorno web como fuente de conocimiento contextual y cultural para aumentar y enriquecer el análisis de la imagen. A partir de las entidades web detectadas, construimos una red bipartita con un nodo de plataforma al que se vinculan las entidades web específicas de la plataforma. En el centro, encontramos entidades web compartidas, mientras que en la periferia las entidades web están asociadas con entornos web específicos y culturas de memes (Imgur, FB, IG, KnowYourMeme ). Entre pares de plataformas, podemos ver grupos puente que representan entidades web compartidas, en otras palabras, qué plataformas tienen en común.
Las redes de visión por computadora se construyen sobre las características de visión por computadora, como la clasificación de imágenes y la detección de entidades web. Aquí utilizamos la detección de entidades web, yendo más allá y detrás del contenido de la imagen inmediata, y utilizando el entorno web como fuente de conocimiento contextual y cultural para aumentar y enriquecer el análisis de la imagen. A partir de las entidades web detectadas, construimos una red bipartita con un nodo de plataforma al que se vinculan las entidades web específicas de la plataforma. En el centro, encontramos entidades web compartidas, mientras que en la periferia las entidades web están asociadas con entornos web específicos y culturas de memes (Imgur, FB, IG, KnowYourMeme ). Entre pares de plataformas podemos ver grupos puente que representan entidades web compartidas, en otras palabras, qué plataformas tienen en común.

 Figura 5. Los elementos formales y temáticos que constituyen las imágenes de los memes covid. Entidades web compartidas asociadas con la colección de imágenes de memes multiplataforma (arriba).
Figura 5. Los elementos formales y temáticos que constituyen las imágenes de los memes covid. Entidades web compartidas asociadas con la colección de imágenes de memes multiplataforma (arriba).
Un análisis del grupo central muestra cómo las redes de visión artificial pueden contribuir a la ontología memética. La centralidad de la red de las entidades web dominantes, que funcionan como puentes entre plataformas, muestra a través de la planitud para el análisis de redes cómo la jerarquía ontológica de los modelos de visión por computadora captura lo que es un meme. Entidades como 'texto', 'imagen', 'captura de pantalla', 'título', 'caricatura', 'dibujo', 'cita' son componentes pre-meméticos que aún no son memes. En otras palabras, los elementos formales de los memes, sus bloques de construcción y las condiciones necesarias son, desde una perspectiva de red, entidades web multiplataforma. Estas entidades web centrales constituyen las primitivas ontológicas y epistemológicas del medio memético: qué es un meme, cómo podemos reconocerlo y cómo podemos crearlo. Como podemos ver, el único clúster temático en el centro está compuesto por entidades relacionadas con Covid, reflejando el diseño de consulta original y representándolo como centralidad de red. Un razonamiento similar se aplica a la ontología de un 'meme covid': debe decir algo sobre la pandemia, la campaña de vacunación y comprometerse con la política. Podemos argumentar que la investigación de memes realizada a través de redes de visión por computadora a menudo arrojará resultados similares: en el centro encontraremos primitivos meméticos, formales y temáticos, mientras que las constelaciones periféricas expresarán culturas de memes locales. debe decir algo sobre la pandemia, la campaña de vacunación y comprometerse con la política.

Figura 6. Las zonas periféricas: culturas meme y vernáculos de plataforma
En las zonas periféricas de la red vemos una clara división. Por un lado, los memes covid están más orientados a la corriente principal, siendo Facebook presentado por la política dominante, mientras que Instagram es la cultura dominante. Por otro lado, vemos memes de nicho relacionados con la cultura nerd (Imgur) y la política alternativa (Know Your Meme). Ambos casos refuerzan el argumento de los memes como colecciones que responden al entorno de software en el que se insertan.
Las entidades web asociadas a los memes covid de Facebook exponen la pandemia y sus noticias relacionadas, también eventos actuales con especial enfoque en noticias políticas, personalidades políticas, políticas y políticas del país. Los memes están desconectados de la cultura pop y las referencias a la cultura de Internet. A continuación, ejemplos de entidades web asociadas exclusivamente con los memes covid de Facebook.
-
Memes como política dominante/figuras políticas:
-
modi, greg abbott, servicio nacional de salud, ron desantis, gobernador, florida, gobierno de la india
-
-
Los memes como noticias principales:
-
oficina de información de prensa, ministerio de salud, variante omicron, investigador diario filipino, transmisión de covid, ocupar demócratas, variante lambda, lavado de manos, covid largo, dosis, variante lambda
-

Figura 7. Red de entidades web de Facebook
En Instagram vemos una relación directa con los aspectos principales de la cultura pop. Por ejemplo, deportes y celebridades con entidades como messi, ronaldo, real madrid, equipo de fútbol de inglaterra . Además, el lenguaje visual obvio de Instagram, por ejemplo, moda, glamour y exageración, se identificó a través de entidades como socialité, vestimenta, turquesa, gafas de sol, criptomonedas, bitcoin, ethereum, belleza, estado físico, modelo . La cultura memética de los memes covid en Instagram no está directamente relacionada con la pandemia, las noticias o la política.
Figura 8. Red de entidades web de Instagram
Las entidades web exclusivas del entorno de software de Imgur se asocian principalmente con referencias culturales pop y se ubican en el cruce de la cultura pop y la cultura de Internet. Dentro de ellos, podemos detectar dos conjuntos distintos pero interrelacionados: el primero contiene referencias a la cultura nerd, mostrando entidades como Harry Potter, Batman, Voldemort, Hobbit, Studio Ghibli, Star Wars, Lord of the Rings, Dungeons and Dragons, Pixar, y Fullmetal Alchemist . El segundo conjunto parece estar relacionado con la cultura viral de internet y los fenómenos culturales en general: entre las entidades encontramos 'i can has cheezburger', tiger king, dog videos, okay boomer, guitar, depression .

Figura 8. Red de entidades web de Imgur
Mirando las entidades web asociadas con el archivo web Know Your Meme, surge un grupo de referencias de nicho y, por lo tanto, no convencionales. Al mismo tiempo, hay una falta sustancial de referencias a la política dominante oa la cultura dominante de las celebridades. En cambio, es posible identificar un enfoque general en los fenómenos de Internet y específico en la web vernácula profunda (Tuters, 2019), como lo sugieren entidades como wojak, corona chan, space karen, wookiepedia, 4 chan, deviantart, cheems . Además de eso, se puede observar que las referencias políticas son más representativas de las ideologías políticas extremas (tanto de extrema derecha como de extrema izquierda), como lo insinúa un grupo de entidades asociadas a la ideología Alt-right:Pepe the Frog, derecha, anthony fauci, espectro político, brújula política, autoritarismo y controversias sobre vacunas.

Figura 9. Red de entidades web KnowYourMeme
Mirando las entidades web de los cuatro clústeres, se puede argumentar que KnowYourMeme e Imgur juntos son más específicos y menos convencionales, con respecto a los otros dos entornos web considerados. Finalmente, la red también permite mirar el “al revés” de cada entorno de software, que contiene las entidades web comunes a las otras plataformas. En este sentido, es posible definir la producción memética de un espacio digital específico a partir de sus “sombras”, es decir, considerando lo que falta en los memes que produce y difunde. Es el caso del clúster de entidades web compartidas por Instagram, Know Your Meme e Imgur pero no por Facebook, como know your meme, broma, risa, entretenimiento, youtube, video viral, grogu, imgflip.
Figura 10. La “sombra de Facebook” o “al revés”
7. Discusión
Esta investigación, realizada durante la Escuela de Invierno de Métodos Digitales 2022, analiza la tecnicidad de los memes en relación con las especificidades de la plataforma. Este estudio sigue la trayectoria de investigación establecida por Rogers & Giorgi (en revisión) en su artículo '¿Qué es un meme, técnicamente hablando?', que propone demarcar la tecnicidad de los memes como colecciones de contenido generado por entornos de software.
Hablando epistemológicamente, cuando se observan los hallazgos, vale la pena discutir algunos puntos. En primer lugar, al observar qué es un meme técnicamente hablando con una lente lógica de tablero de marketing de redes sociales, esto constituye la ontología más amplia de lo que se considera un meme; Aquí no solo está presente el formato macro de imagen clásico, sino también muchos otros formatos diferentes. En segundo lugar, al observar qué es un meme técnicamente hablando con una lente lógica de generador y servidor de alojamiento de imágenes, esto constituye la ontología más estrecha de lo que se considera un meme; un formato macro de imagen clásico. En tercer lugar, al observar qué es un meme técnicamente hablando con un archivo de base de datos y una lente lógica de motor de búsqueda, la ontología se encuentra en algún punto intermedio; las macros de imagen clásicas se combinan con un par de otros formatos. Por último,
Desde el punto de vista del análisis de visión por computadora, inferimos qué es un meme a través de la detección de entidades web de Google Vision. La técnica de creación de redes permitió el análisis multiplataforma de imágenes utilizando todos los idiomas de Google y su soporte de tecnología Vision, pero sin ver las imágenes. No solo pudimos informar qué constituyen técnicamente los memes covid, sino que también captamos las lenguas vernáculas de los memes en varias plataformas. Inferimos temas específicos de la plataforma derivados de entidades web al cerrar la lectura de la periferia y las zonas medias de la red. Aquí, el análisis de memes requirió la experiencia de un equipo multidisciplinario y el reconocimiento de la tecnicidad del medio memético y sus entornos web.
8. Conclusión
La pregunta de investigación de qué es un meme, técnicamente hablando y cómo las plataformas de software construyen las colecciones de memes, es muy amplia. Nuestro proyecto de investigación solo ha comenzado a rascar la superficie de cómo se puede investigar empíricamente la tecnicidad de los memes. Al observar los resultados, se puede argumentar en general que lo que constituye un meme depende en gran medida del entorno del software, ya que un entorno web contextual específico de la plataforma y las definiciones difieren ampliamente según la plataforma. De hecho, este proyecto proporciona hallazgos empíricos que respaldan la afirmación principal de Rogers y Giorgi (en revisión), es decir, que los memes tienen una tecnicidad que los afecta materialmente como colecciones en estudio.Aunque limitados, estos hallazgos también nos permiten concluir con una declaración especulativa sobre lo que lo anterior podría significar para la investigación de memes en general. La definición ontológica de lo que es un meme, basada en el entorno de software que analizamos, es más amplia de lo que los investigadores probablemente clasificarían como un meme (la macro de imagen clásica) e incluye más formatos de imagen. Esto implica que cuando los investigadores utilizan estas herramientas para realizar investigaciones de memes, lo que están investigando se está moviendo hacia un modo más amplio de análisis de imágenes virales, pasando de un tipo de investigación más vernáculo de nicho.
9. Referencias
Bastian, M., Heymann, S., & Jacomy, M. (2009). Gephi: An Open Source Software for Exploring and Manipulating Networks. Third International AAAI Conference on Weblogs and Social Media, 361–362. https://doi.org/10.1136/qshc.2004.010033Bucher, T. (2012). A technicity of attention: How software 'makes sense'. Culture Machine, 13, 1-23.
Chao, J. (2021). Memespector GUI: Graphical User Interface Client for Computer Vision APIs (Version 0.2) [Software]. Available from https://github.com/jason-chao/memespector-gui.
Davison, P. (2012). The language of internet memes. The social media reader, 120-134.
Dynel, M. (2016). “I has seen Image Macros!” Advice Animals memes as visual-verbal jokes. International Journal of Communication, 10, 29.
Jacomy M, Venturini T, Heymann S, Bastian M (2014) ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. PLoS ONE 9(6): e98679. https://doi.org/10.1371/journal.pone.0098679
Laineste, L., & Voolaid, P. (2016). Laughing across borders: Intertextuality of internet memes. The European Journal of Humour Research, 4(4), 26-49.
Maier, Nils; Parodi, Federico & Verna, Stefano (2007). DownThemAll (Version 4.04) [browser extention] . Available from https://www.downthemall.org/
Medialab Tools. Table2Net Available from https://medialab.github.io/table2net/
Milner, R. M. (2018). The world made meme: Public conversations and participatory media. MIT Press.
Miltner, K. M. (2014). “There’s no place for lulz on LOLCats”: The role of genre, gender, and group identity in the interpretation and enjoyment of an Internet meme. First Monday.
Miltner, K. M. (2018). Internet memes. The SAGE handbook of social media, 55, 412-428.
Niederer, S. (2019). Networked Content Analysis: The case of climate change. (1 ed.)
(Theory on Demand; No. 32). Hogeschool van Amsterdam, Lectoraat Netwerkcultuur.
Niederer, S., & Van Dijck, J. (2010). Wisdom of the crowd or technicity of content? Wikipedia as a sociotechnical system. New media & society, 12(8), 1368-1387.
Nissenbaum, A., & Shifman, L. (2017). Internet memes as contested cultural capital: The case of 4chan’s/b/board. New Media & Society, 19(4), 483-501.
Omena, J. J. (2021). Digital Methods and Technicity-of-the-Mediums. From Regimes of Functioning to Digital Research [Universidade Nova de Lisboa]. Available from https://run.unl.pt/handle/10362/127961
Omena, J. J., Elena, P., Gobbo, B., & Jason, C. (2021). The Potentials of Google Vision API-based Networks to Study Natively Digital Images. Diseña, (19), 1-1.
Omena, J. J., & Amaral, I. (2019). Sistemas de leitura de redes digitais multiplatform. In J. J. Omena (Ed.) Métodos Digitais: Teoria-Prática-Crítica. Lisboa: ICNOVA. ISBN: 978‐972‐9347‐34‐4
Rogers, R. (2019). Doing digital methods. Sage.
Rogers, R. (2021). Visual media analysis for Instagram and other online platforms. London. SAGE Publications Ltd.
Rogers, R., and Giorgi, G. (under review). ‘What is a meme, technically speaking?’.
Shifman, L. (2014). Memes in digital culture. MIT press.
Tuters, M. (2019). LARPing & liberal tears: Irony, belief and idiocy in the deep vernacular web. Available from https://mediarep.org/bitstream/handle/doc/13282/Post_Digital_Cultures_37-48_Tuters_LARPing_Liberal_Tears.pdf?sequence=1
Venturini, T., Jacomy, M., & Jensen, P. (2019). What do we see when we look at networks. arXiv preprint arXiv:1905.02202.
Pearce, W., Özkula, S. M., Greene, A. K., Teeling, L., Bansard, J. S., Omena, J. J., & Rabello, E. T. (2020). Visual cross-platform analysis: Digital methods to research social media images. Information, Communication & Society, 23(2), 161-180.
Spitzberg, B. H. (2014). Toward a model of meme diffusion (M3D). Communication Theory, 24(3), 311-339.
Wiggins, B. E., & Bowers, G. B. (2015). Memes as genre: A structurational analysis of the memescape. New media & society, 17(11), 1886-1906.
Zannettou, S., Caulfield, T., Blackburn, J., De Cristofaro, E., Sirivianos, M., Stringhini, G., & Suarez-Tangil, G. (2018, October). On the origins of memes by means of fringe web communities. In Proceedings of the Internet Measurement Conference 2018 (pp. 188-202).
Suscribirse a:
Entradas (Atom)