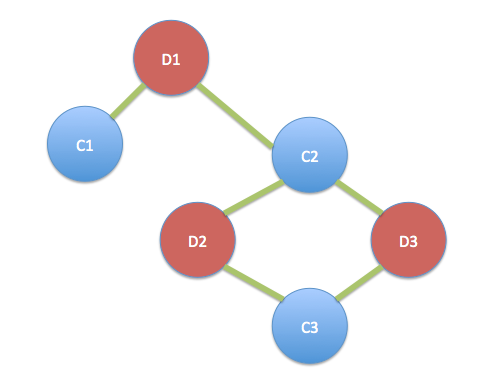
El CEO de Cambridge Analytica Alexander Nix habla en la Cumbre Concordia 2016 - Día 1 en Grand Hyatt New York el 19 de septiembre de 2016 en la ciudad de Nueva York. Bryan Bedder vía Getty Images
Revelado: 50 millones de perfiles de Facebook cosechados para Cambridge Analytica en violación de datos importantes
Delator describe cómo la empresa vinculada al ex asesor de Trump, Steve Bannon compiló los datos de los usuarios para apuntar a los votantes estadounidenses• Cómo los algoritmos de Cambridge Analytica convirtieron los "me gusta" en una herramienta política
Carole Cadwalladr y Emma Graham-Harrison | The Guardian
Denunciante de Cambridge Analytica: 'Gastamos $ 1m recolectando millones de perfiles de Facebook' - video
La firma analítica de datos que trabajó con el equipo electoral de Donald Trump y la ganadora campaña Brexit recolectó millones de perfiles de Facebook de votantes estadounidenses, en una de las infracciones de datos más grandes del gigante tecnológico, y los usó para construir un poderoso programa de software para predecir e influir en las elecciones en las urnas.
Un denunciante ha revelado al observador cómo Cambridge Analytica - una empresa propiedad del multimillonario de fondos de cobertura Robert Mercer, y encabezada en ese momento por el asesor clave de Trump, Steve Bannon - usó información personal tomada sin autorización a principios de 2014 para construir un sistema que pudiera perfilarse votantes estadounidenses individuales, con el fin de dirigirlos a ellos con publicidades políticas personalizadas.

Christopher Wylie, el alcahuete de Cambridge Analytica
Christopher Wylie, que trabajó con un académico de la Universidad de Cambridge para obtener los datos, le dijo al observador: "Aprovechamos Facebook para recolectar millones de perfiles de personas. Y construyó modelos para explotar lo que sabíamos acerca de ellos y apuntar a sus demonios internos. Esa fue la base sobre la que se basó toda la compañía ".
Los documentos vistos por el Observer, y confirmados por una declaración de Facebook, muestran que a fines de 2015 la compañía había descubierto que la información se había recolectado a una escala sin precedentes. Sin embargo, en ese momento no alertó a los usuarios y tomó solo medidas limitadas para recuperar y proteger la información privada de más de 50 millones de personas.
Perfiles
Cambridge Analytica: los jugadores clave
Alexander Nix, CEO
Antiguo Etoniano de la Universidad de Manchester, Nix, de 42 años, trabajó como analista financiero en México y el Reino Unido antes de unirse a SCL, una empresa de comunicaciones estratégicas, en 2003. Desde 2007 asumió la división de elecciones de la compañía, y afirma tener trabajó en 260 campañas a nivel mundial. Estableció Cambridge Analytica para trabajar en Estados Unidos, con la inversión de Robert Mercer.
Aleksandr Kogan, minero de datos
Aleksandr Kogan nació en Moldavia y vivió en Moscú hasta la edad de siete años, luego se mudó con su familia a los Estados Unidos, donde se convirtió en ciudadano naturalizado. Estudió en la Universidad de California, Berkeley, y obtuvo su doctorado en la Universidad de Hong Kong antes de unirse a Cambridge como profesor de psicología y experto en psicometría de redes sociales. Estableció Global Science Research (GSR) para llevar a cabo la investigación de datos de CA. Mientras estuvo en Cambridge, aceptó un puesto en la Universidad Estatal de San Petersburgo y también recibió becas del gobierno ruso para investigación. Cambió su nombre a Spectre cuando se casó, pero luego volvió a Kogan.
Steve Bannon, ex miembro de la junta
Un ex banquero de inversión convertido en un svengali de medios "alt-right", Steve Bannon era el jefe del sitio web Breitbart cuando conoció a Christopher Wylie y Nix y aconsejó a Robert Mercer que invierta en investigación de datos políticos estableciendo CA. En agosto de 2016 se convirtió en el CEO de campaña de Donald Trump. Bannon alentó a la estrella de televisión a adoptar la agenda "populista, nacionalista económico" que lo llevaría a la Casa Blanca. Eso le valió a Bannon el puesto de estratega jefe del presidente y durante un tiempo fue posiblemente el segundo hombre más poderoso de Estados Unidos. Para agosto de 2017, su relación con Trump se había agriado y él estaba fuera.
Robert Mercer, inversor
Robert Mercer, de 71 años, es un informático y multimillonario de fondos de cobertura, que usó su fortuna para convertirse en uno de los hombres más influyentes en la política estadounidense como uno de los principales donantes republicanos. Un experto en inteligencia artificial, hizo una fortuna con los pioneros en comercio cuantitativo Renaissance Technologies, y luego construyó un cofre de guerra de 60 millones de dólares para respaldar causas conservadoras mediante el uso de un vehículo de inversión offshore para evitar los impuestos estadounidenses.
Rebekah Mercer, inversionista
Rebekah Mercer es matemática de Stanford y trabajó como comerciante, pero su influencia proviene principalmente de los miles de millones de su padre. El cuarenta y tantos, la segunda de las tres hijas de Mercer, encabeza la fundación familiar que canaliza el dinero a los grupos de derecha. Los mega-donantes conservadores respaldaron a Breitbart, Bannon y, más influyente, invirtieron millones en la campaña presidencial de Trump.
The New York Times informa que todavía se pueden encontrar copias de los datos recopilados para Cambridge Analytica en línea; su equipo de informes había visto algunos de los datos sin procesar.
Los datos fueron recolectados a través de una aplicación llamada thisisyourdigitallife, construida por el académico Aleksandr Kogan, separada de su trabajo en la Universidad de Cambridge. A través de su empresa Global Science Research (GSR), en colaboración con Cambridge Analytica, se les pagó a cientos de miles de usuarios para que realicen una prueba de personalidad y acordaron que se recopilaran sus datos para uso académico.
Sin embargo, la aplicación también recopiló la información de los amigos de Facebook de los candidatos, lo que llevó a la acumulación de un grupo de datos de decenas de millones de personas. La "política de plataforma" de Facebook permitió solo la recopilación de datos de amigos para mejorar la experiencia del usuario en la aplicación y prohibió su venta o uso para publicidad. El descubrimiento de la recolección de datos sin precedentes, y el uso que se le dio, plantea nuevas preguntas urgentes sobre el papel de Facebook en la selección de votantes en las elecciones presidenciales de Estados Unidos. Se produce solo semanas después de las acusaciones de 13 rusos formuladas por el asesor especial Robert Mueller, que afirmaba que habían utilizado la plataforma para perpetrar una "guerra de información" contra los EE. UU.
Cambridge Analytica y Facebook son un foco de una investigación sobre datos y política realizada por la Oficina del Comisionado de Información británico. Por otro lado, la Comisión Electoral también está investigando qué papel desempeñó Cambridge Analytica en el referéndum de la UE.
"Estamos investigando las circunstancias en que los datos de Facebook pueden haber sido adquiridos y utilizados ilegalmente", dijo la comisionada de información Elizabeth Denham. "Es parte de nuestra investigación en curso sobre el uso de análisis de datos para fines políticos que se inició para considerar cómo los partidos políticos y las campañas, las empresas de análisis de datos y las plataformas de redes sociales en el Reino Unido están utilizando y analizando información personal de las personas para micro-segmentar a los votantes. "
El viernes, cuatro días después, The Observer buscó comentarios para esta historia, pero más de dos años después de que se informara la violación de datos, Facebook anunció que suspendería Cambridge Analytica y Kogan de la plataforma, a la espera de más información sobre el uso indebido de datos. Por otra parte, los abogados externos de Facebook advirtieron al observador que estaba haciendo acusaciones "falsas y difamatorias", y se reservaron la posición legal de Facebook.

Consejero clave de Trump Steve Bannon
Las revelaciones provocaron una indignación generalizada. La fiscal general de Massachusetts, Maura Healey, anunció que el estado lanzaría una investigación. "Los residentes merecen respuestas inmediatamente de Facebook y Cambridge Analytica", dijo en Twitter.
El senador demócrata Mark Warner dijo que la recolección de datos en una escala tan amplia para la focalización política subrayó la necesidad de que el Congreso mejore los controles. Ha propuesto una Ley de anuncios honestos para regular la publicidad política en línea de la misma manera que la televisión, la radio y la prensa. "Esta historia es más evidencia de que el mercado de publicidad política en línea es esencialmente el Salvaje Oeste. Ya sea que les permita a los rusos comprar avisos políticos, o una amplia microtelevisión basada en datos de usuarios mal comprados, está claro que, si no se regula, este mercado seguirá siendo propenso al engaño y carente de transparencia ", dijo.
El mes pasado, tanto Facebook como el CEO de Cambridge Analytica, Alexander Nix, dijeron en una investigación parlamentaria sobre noticias falsas: que la compañía no tenía ni usaba datos privados de Facebook.
Simon Milner, director de políticas del Reino Unido de Facebook, cuando se le preguntó si Cambridge Analytica tenía datos de Facebook, le dijo a los parlamentarios: "Pueden tener muchos datos, pero no serán datos de usuarios de Facebook". Pueden ser datos sobre personas que están en Facebook que se han reunido, pero no son datos que hemos proporcionado ".
El director ejecutivo de Cambridge Analytica, Alexander Nix, dijo a la consulta: "No trabajamos con datos de Facebook y no tenemos datos de Facebook".
Wylie, un experto en análisis de datos canadiense que trabajó con Cambridge Analytica y Kogan para diseñar e implementar el esquema, mostró un dosier de pruebas sobre el uso indebido de datos para el Observer que parece suscitar preguntas sobre su testimonio. Lo ha pasado a la unidad de ciberdelincuencia de la Agencia Nacional de Crimen y a la Oficina del Comisionado de Información. Incluye correos electrónicos, facturas, contratos y transferencias bancarias que revelan que más de 50 millones de perfiles, en su mayoría pertenecientes a votantes estadounidenses registrados, se obtuvieron del sitio en una de las mayores violaciones de datos de Facebook. Facebook el viernes dijo que también estaba suspendiendo a Wylie de acceder a la plataforma mientras llevaba a cabo su investigación, a pesar de su papel como delator.
En el momento de la violación de los datos, Wylie era un empleado de Cambridge Analytica, pero Facebook lo describió como que trabajaba para Eunoia Technologies, una empresa que creó por su cuenta después de dejar a su antiguo empleador a finales de 2014.
La evidencia que Wylie suministró a las autoridades del Reino Unido y los EE. UU. Incluye una carta de los propios abogados de Facebook que le enviaron en agosto de 2016, pidiéndole que destruya todos los datos que tenía recogidos por GSR, la empresa creada por Kogan para recolectar los perfiles.
¿Qué son los archivos de Cambridge Analytica?
Al trabajar con un informante que ayudó a configurar Cambridge Analytica, el Observer y Guardian han visto documentos y recopilado informes de testigos que levantan la tapa de la empresa de análisis de datos que ayudó a Donald Trump a la victoria. La compañía está siendo investigada en ambos lados del Atlántico. Es un tema clave en dos investigaciones en el Reino Unido - por la Comisión Electoral, sobre el posible papel de la empresa en el referéndum de la UE y la Oficina del Comisionado de Información, en análisis de datos con fines políticos - y uno en los EE. UU., Como parte de un abogado especial La investigación de Robert Mueller sobre la colusión entre Trump y Rusia.
Esa carta legal fue enviada varios meses después de que The Guardian informara por primera vez de la violación y días antes de que se anunciara oficialmente que Bannon estaba asumiendo el control como jefe de campaña de Trump y trayendo Cambridge Analytica con él.
"Debido a que estos datos se obtuvieron y usaron sin permiso, y debido a que GSR no estaba autorizado a compartirlos o venderlos, no se pueden usar legítimamente en el futuro y deben eliminarse inmediatamente", decía la carta.
Facebook no solicitó una respuesta cuando la carta inicialmente no recibió respuesta durante semanas porque Wylie estaba de viaje, y tampoco siguió con controles forenses en sus computadoras o almacenamiento, dijo.
"Eso para mí fue lo más sorprendente". Esperaron dos años y no hicieron absolutamente nada para verificar que los datos se borraron. Todo lo que me pidieron que hiciera fue marcar una casilla en un formulario y publicarlo nuevamente ".
Paul-Olivier Dehaye, especialista en protección de datos, quien encabezó los esfuerzos de investigación en el gigante tecnológico, dijo: "Facebook ha negado, negado y negado esto. Ha engañado a los parlamentarios y a los investigadores del Congreso y ha fallado en sus deberes de respetar la ley.
"Tiene la obligación legal de informar a reguladores e individuos sobre esta violación de datos, y no es así. Una y otra vez ha fallado ser abierto y transparente ".
Aprovechamos Facebook para cosechar millones de perfiles. Y construir modelos para explotar eso y apuntar a sus demonios internosLa mayoría de los estados estadounidenses tienen leyes que requieren notificación en algunos casos de violación de datos, incluyendo California, donde se basa Facebook.
Christopher Wylie
Facebook niega que la recolección de decenas de millones de perfiles por parte de GSR y Cambridge Analytica haya sido una violación de datos. Dijo en un comunicado que Kogan "obtuvo acceso a esta información de manera legítima y a través de los canales adecuados", pero "no acató nuestras reglas" porque transmitió la información a terceros.
Facebook dijo que retiró la aplicación en 2015 y exigió la certificación de todos los que tenían copias de que los datos habían sido destruidos, aunque la carta a Wylie no llegó hasta la segunda mitad de 2016. "Nos comprometemos a aplicar enérgicamente nuestras políticas para proteger la información de las personas . Tomaremos todos los pasos necesarios para garantizar que esto ocurra ", dijo en un comunicado Paul Grewal, vicepresidente de Facebook. La compañía ahora está investigando informes de que no se han eliminado todos los datos.
Kogan, que anteriormente no informó enlaces a una universidad rusa y tomó subvenciones rusas para investigación, tenía una licencia de Facebook para recopilar datos de perfil, pero solo para fines de investigación. Entonces cuando buscó información para la empresa comercial, estaba violando los términos de la compañía. Kogan sostiene que todo lo que hizo era legal, y dice que tenía una "relación de trabajo cercana" con Facebook, que le había otorgado permiso para sus aplicaciones.
Cómo se desarrolló la historia
The Observer ha visto un contrato con fecha del 4 de junio de 2014, que confirma que SCL, una filial de Cambridge Analytica, celebró un acuerdo comercial con GSR, totalmente basado en la recolección y el procesamiento de datos de Facebook. Cambridge Analytica gastó casi $ 1 millón en la recopilación de datos, lo que arrojó más de 50 millones de perfiles individuales que podrían combinarse con las listas electorales. A continuación, utilizó los resultados de las pruebas y los datos de Facebook para construir un algoritmo que podría analizar perfiles de Facebook individuales y determinar los rasgos de personalidad relacionados con el comportamiento electoral.El algoritmo y la base de datos juntos constituyeron una poderosa herramienta política. Permitió una campaña para identificar posibles votantes indecisos y crear mensajes con más probabilidades de resonar.
"El producto final del conjunto de capacitación es la creación de un 'estándar de oro' para comprender la personalidad desde la información de perfil de Facebook", especifica el contrato. Promete crear una base de datos de 2 millones de perfiles "coincidentes", identificables y vinculados a los registros electorales, en 11 estados, pero con espacio para expandirse mucho más.