¿Qué es un meme, técnicamente hablando?
Digital Methods InitiativeExplorando la tecnicidad de los memes en diferentes entornos digitales
Miembros del equipo
Alberto Olivieri, Alexander, Alice Noris, Andre Theng, Anton Berg, Anunaya Rajhans, Artur Holiavin, Chloë Arkenbout, Giovanni Daniele Starita, Kristen Zheng, Marcantonio Bracale, Marco Valli, Nabeel Siddiqui, Nina Welt, Octavian, Samson Geboers, Swati
Facilitadores: Prof. Richard Rogers, Dra. Janna Joceli Omena, Giulia Giorgi
Resultados clave
-
Los entornos de software afectan en gran medida la conceptualización y la estética de los memes. De hecho, los géneros y formatos dominantes suelen variar según la plataforma de la que se extraen.
-
El
análisis visual revela un espectro de formatos, cuya presencia y
frecuencia en los entornos de software puede oscilar considerablemente:
por ejemplo, Imgur contiene la mayor cantidad de macros de imágenes, a
diferencia del conjunto de datos extraído con CrowdTangle , en el que casi no estaban.
-
En
general, las capturas de pantalla de los tweets son el formato de memes
que se presenta con mayor frecuencia, cruzando transversalmente los
cuatro entornos de software considerados en el análisis.
-
Además del análisis visual, las redes de visión por computadora pueden contribuir a la ontología memética. Mientras
que la centralidad de la red de las entidades web dominantes captura lo
que es un meme, identificando componentes pre-meméticos como 'texto',
'imagen', 'captura de pantalla', 'título', 'dibujo', 'dibujo', 'cita',
las zonas periféricas de la red muestran las peculiaridades del meme
ligado a entornos web específicos. Finalmente,
los grupos de 'puente' revelan las entidades asociadas con dos o más
plataformas para clasificar sus imágenes de memes covid. En
general, el análisis revela cómo las diferentes plataformas vernáculas
dan forma a las culturas de los memes, arrojando luz sobre lo que es
común entre dos o más plataformas, y lo que falta o está ausente.
1. Introducción
La
investigación que llevamos a cabo durante la Escuela de Invierno de
Métodos Digitales 2022 ofrece una descripción de cómo se identifican y
detectan los memes dentro y entre diferentes entornos de software,
contribuyendo así al campo más amplio de la investigación de memes. Más
específicamente, este trabajo tiene como objetivo mapear la composición
técnica de las imágenes meméticas y cómo este tecnicismo se relaciona o
es específico de uno o varios entornos de software. El proyecto se basa en un artículo de investigación reciente, "¿Qué es un meme, técnicamente hablando?" (Rogers y Giorgi, en revisión), que concibe los memes como colecciones de artefactos moldeados por el software que los genera.
La
investigación existente entiende los memes como artefactos culturales
multimodales, que los usuarios crean, remezclan y hacen circular a
través de plataformas digitales (Shifman, 2014; Milner, 2016; Davison,
2012). Su origen se
remonta a los espacios digitales marginales y, hasta principios de la
década de 2010, eran una prerrogativa de las comunidades subculturales
que poblaban sitios web como 4chan y Reddit (cfr. Zanettou et al.,
2018). Sin embargo, se ha
hecho evidente que la relevancia de los memes también se ha extendido a
los principales medios digitales, ya que se han convertido en una
“práctica ubicua, posiblemente fundamental, de los medios digitales”
(Miltner, 2018, p. 412). En
este sentido, los memes se consideran un género completo, con conjuntos
de reglas y convenciones definidas sociológicamente (Wiggins y Bowers,
2015).
En
particular, los académicos han puesto énfasis en diferentes aspectos de
los memes, como su tipología (Shifman, 2013; Laineste y Voolaid, 2016;
Dynel, 2016), su circulación viral (Spitzberg, 2014) y su papel en
diferentes entornos subculturales (Nissenbaum & Shifman, 2017;
Miltner, 2018). Además del
enfoque vernáculo, un aspecto interesante y relativamente poco
estudiado consiste en la exploración de la tecnicidad, materialidad y
relacionalidad de los memes ligada a las especificidades de la
plataforma. Como lo
describe Niederer (2019), esta “tecnicidad del contenido” está
delimitada y co-constituida por el portador que los proporciona (p. 18).
En este sentido, el punto
de partida del presente trabajo es la definición de los memes como
productos resultantes de una combinación de posibilidades técnicas,
prácticas convencionalizadas y cultura participativa digital.
Tomando
prestado el término 'tecnicidad' (Niederer & Van Dijck, 2010) para
capturar la idea del meme como 'compuesto tecnológicamente' o
'co-constituido' por su entorno de software (Bucher, 2012), nos
dispusimos a investigar los memes como productos en línea que pueden
etiquetarse y recopilarse en bases de datos, software de creación de
medios o generadores, identificados y etiquetados por software analítico
y de visión y devueltos por 'búsqueda de memes' en paneles de datos de
investigación y marketing. Cada software genera una colección de memes peculiar, destacando ciertas características y eclipsando otras. Es
decir, las colecciones de objetos técnicos representados por los
entornos de software tienen diferentes características que dependen de
si se acumularon a través de una base de datos, plantillas, análisis,
coincidencias u otra lógica. En esta luz,
3. Preguntas de investigación
Siguiendo el marco teórico esbozado anteriormente, esta investigación busca dar respuesta a estas preguntas de investigación:
-
¿Cómo contribuye el entorno de software en el que se delimitan los memes a dar forma a diferentes colecciones de memes?
-
¿Cómo afecta esa creación de conjuntos o colecciones a la investigación de memes?
A
través de este estudio empírico, pretendemos mostrar que diferentes
entornos de software contienen una lógica diferente a la formación de
colecciones de memes. Con
esto en mente, formulamos la siguiente hipótesis: las colecciones de
objetos técnicos generados por los entornos de software tienen
características únicas que dependen de si se acumularon a través de una
base de datos, plantillas, análisis, coincidencias u otra lógica.
4. Conjuntos de datos iniciales
Selección de casos. La
base de datos para esta investigación fue ensamblada por participantes
de la Escuela de Invierno mediante la recopilación de imágenes en cuatro
entornos de software seleccionados. Nuestra
selección de plataformas, que podría describirse como una forma de
muestreo de máxima variación (Etikan et al., 2016) con un enfoque en la
diversidad y heterogeneidad de casos, incluye:
-
CrowdTangle,
una herramienta de marketing de la empresa Meta (ex Facebook), que se
empleaba para extraer datos de Instagram y Facebook;
-
Imágenes de Google;
-
Imgur, un generador digital que proporciona plantillas para macros de imágenes;
-
KnowYourMeme, uno de los repositorios de memes más antiguos y conocidos.
Recopilación de datos. Para
capturar representaciones contemporáneas de lo que puede constituir un
meme según estos entornos de software y enfatizar la comparabilidad,
decidimos recopilar contenido memético en torno al tema de la pandemia
de Covid-19, ya que lo consideramos un contenido altamente mediatizado
que ha dado lugar a un intensa producción de contenido en diferentes
plataformas (Murru y Vicari, 2021). Para
mejorar aún más la operatividad de los resultados de las imágenes, la
recopilación de datos se centró en el contenido en inglés (Pearce et al.
2018). Para garantizar un
entorno de software "inglés", se utilizaron redes privadas virtuales,
imitando un sistema basado en la ubicación en los Estados Unidos
(Rogers, 2019).
Para ello, buscamos las palabras clave "covid meme" en las plataformas seleccionadas. El tablero de datos de marketing CrowdTangle ofrece la opción de "búsqueda de memes", donde se puede consultar contenido memético en Facebook e Instagram. Además,
el tablero nos permite filtrar el idioma (seleccionamos "Inglés") y el
tipo de contenido (seleccionamos "Fotos" para Facebook y "Fotos" y
"Álbumes" para Instagram). Datos de Google Imágenes, Imgur y Know Your
Meme se recopilaron con la herramienta ImageScraper (disponible en GitHub ). El rango de tiempo para los resultados de la búsqueda se restringió al año 2021.
Muestreo del conjunto de datos. Submuestreamos los datos extraídos con CrowdTangle
de Instagram y Facebook, eligiendo las primeras 1000 imágenes ordenadas
por el número total de interacciones (uno de los metadatos
predeterminados proporcionados por CrowdTangle ). Para
Imgur y Know Your Meme, se seleccionaron las primeras 1000 imágenes del
resultado de la búsqueda, ordenadas por la calificación de interacción
de los sitios web. El
conjunto de datos de imágenes de Google consta de los primeros 500
resultados de imágenes debido a las limitaciones del alcance de la
investigación. La Figura 1 detalla la composición de cada submuestra en términos del número de elementos considerados por entorno de software.

Figura 1. Proceso de creación de conjuntos de datos
5. Metodología
Nuestra
investigación toma la forma de un análisis comparativo, destinado a
revelar cómo los diferentes entornos de software identifican y agrupan
los memes de manera diferente. Mediante el uso de métodos y herramientas digitales como ImageSorter
y Google Vision, los memes recopilados se clasifican según sus
propiedades formales, visuales y de contenido, lo que da como resultado
un conjunto de formatos de memes, algunos más específicos de la
plataforma que otros. Lo que un entorno de software representa como un meme diferencia de un entorno a otro. Por
ejemplo, lo que Imgur enumera como un meme difiere de lo que Facebook o
Instagram consideran como un meme al mirar sus mejores resultados. Estos
contrastes se suman al argumento de Rogers y Giorgi (bajo revisión), de
que el entorno del software contribuye a dar forma a las colecciones de
memes.
El
análisis de los datos digitales consistió en dos secciones de trabajo
empírico, realizadas respectivamente por dos subgrupos diferentes de
participantes. Específicamente,
el análisis realizado por el Grupo 1 se basó en el análisis visual
(Rogers, 2021), mientras que el Grupo 2 adoptó un enfoque de red de
visión por computadora (Omena et. al. 2021; Omena 2021). En el resto de esta sección, ilustraremos ambos procedimientos metodológicos.
Grupo 1 - Exploración de colecciones de memes a través de un software de análisis visual automatizado. Tomando cada submuestra por separado, empleamos el software ImageSorter para analizar visualmente las colecciones devueltas por los cuatro entornos (Rogers, 2021). Al organizar las imágenes con ImageSorter
por tono y color, la herramienta nos permitió identificar tanto grupos
homogéneos de imágenes (Warren Pearce et al., 2018) como imágenes que se
repiten con frecuencia. Contextualmente, también pudimos distinguir entre copias exactas e imágenes similares (Rogers, 2021). Luego
profundizamos en el análisis de las similitudes y diferencias de los
conglomerados, realizando una lectura atenta de las muestras, con foco
en tres rasgos característicos:
-
Tipos
de Imágenes Dominantes: qué tipologías de imágenes ocurrieron más en
cada muestra, en términos de imágenes similares y copias;
-
Ontología: qué elementos materiales y estéticos caracterizaron cada plataforma;
-
Epistemología: lo que constituye un meme para cada plataforma a partir de las respectivas imágenes de cada muestra.
Además,
con la ayuda de Memespector GUI (Chao, 2021), analizamos los metadatos
de la imagen para extraer los sitios web donde se encontraron imágenes
totalmente coincidentes. Esto
nos ayudó a contextualizar la circulación de imágenes en la web (Omena
et. al. 2021), para evaluar en qué medida cada submuestra resultó de
imágenes relacionadas con otras plataformas o se compartieron
principalmente en la misma plataforma de la que las extrajimos.
Grupo 2 - Exploración de colecciones de memes a través de la visión artificial. En
un segundo nivel de análisis, seguimos un enfoque de red de visión por
computadora (Omena et. al. 2021; Omena 2021) para estudiar las
colecciones de imágenes capturadas en diferentes entornos de software. Se requirió una variedad de herramientas y software de investigación para implementar este método, como DownThemAll (Maier, Parodi & Verna, 2007), Memespector GUI (Chao, 2021), Google Spreadsheets, Table2Net y Gephi (Bastian, Heymann & Jacomy, 2009). ).
Construimos
una red con salidas de visión por computadora (detección web Google
Vision AI, es decir, entidades web) para nuestra colección de imágenes,
creando nodos como plataformas (Facebook, Instagram, Imgur y KnowYourMeme ) y entidades web. Las
entidades web pueden describirse como una cosa, una persona, un lugar
(ubicación) o el nombre de una organización/evento detectado y
reconocido en contenido basado en Internet. En
nuestro contexto, proporcionaron referencias contextuales y culturales a
nuestras colecciones de imágenes, pero yendo más allá del contenido de
las imágenes mismas (Omena et. al. 2021). Sin
renderizar las imágenes dentro de la red, pudimos dar sentido a la
materialidad de los memes al observar las entidades web dominantes
(centro de la red) y los contextos culturales específicos de los memes a
través de las zonas periféricas de la red y los grupos de entidades web
puente.
En
la exploración y análisis visual de la red (Venturini, Jacomy &
Jensen, 2019), nos enfocamos en las zonas fijas de la red, pero
entendiendo el significado de la posición y el tamaño del nodo para el
análisis de imágenes (ver Omena & Amaral, 2019). En
la red a continuación, el tamaño del nodo de la plataforma significa el
total de entidades web asociadas con la colección de imágenes de memes
que provienen de una plataforma. El
tamaño del nodo de la entidad web significa la cantidad de veces que se
usó una entidad determinada para describir una o más imágenes
(considerando todas las imágenes que provienen de diferentes
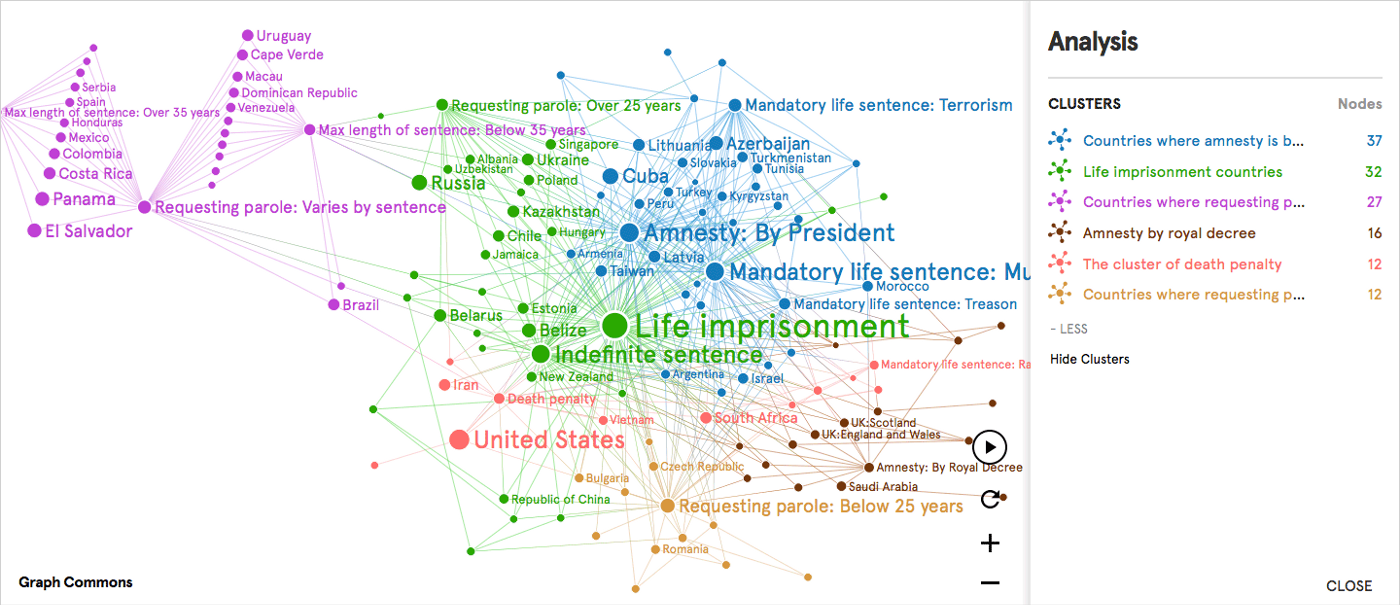
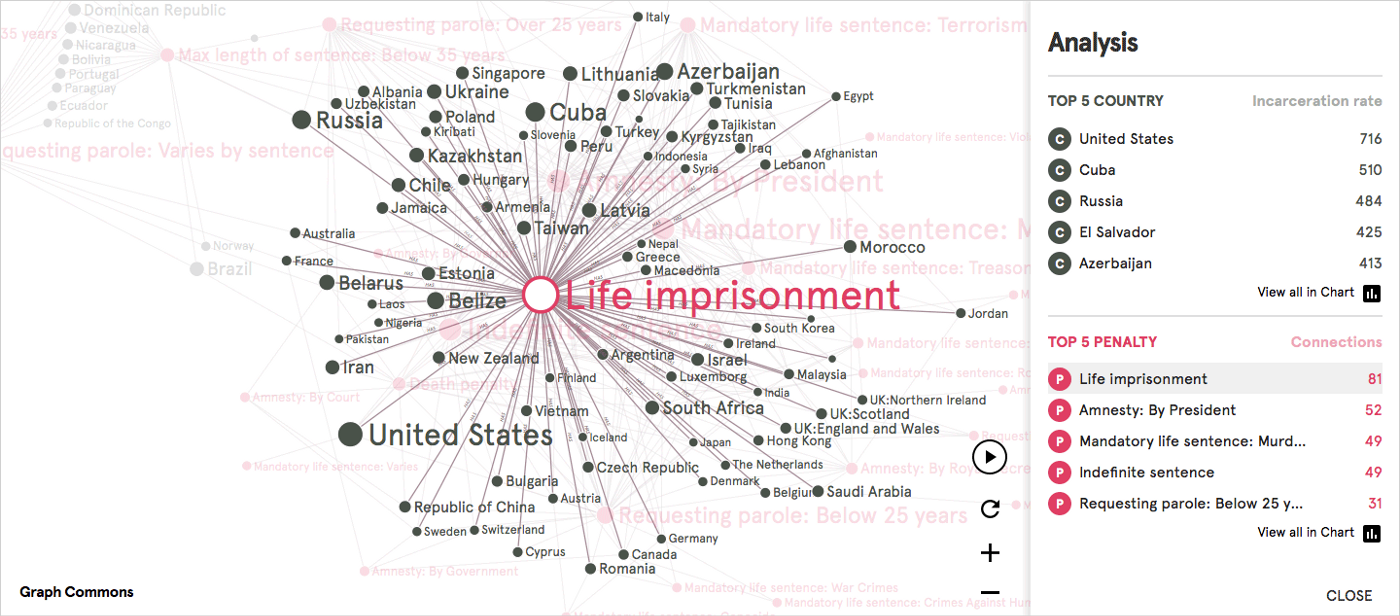
plataformas). Siguiendo las posibilidades del algoritmo de diseño gráfico ForceAtlas2 (Jacomy, Venturini, Heymann & Bastian, 2014), la siguiente tabla explica la posición del nodo y cómo interpretamos la red.


Figura 2. ¿Cómo leer una red de plataformas y entidades web asociadas a imágenes de memes covid? Tabla explicativa y descriptiva (arriba) y visualización de red gif (abajo).
6. Hallazgos
6.1 Exploración de colecciones de memes a través de software para análisis visual automatizado.
Los
principales hallazgos generados por el enfoque de análisis visual
ilustrado en la sección de métodos se visualizan en la Figura 3. Como se
ilustra en la barra de espectro superior, hubo varios formatos de
imagen en los conjuntos de datos. Cuando
se combinaron todos los conjuntos de datos, las capturas de pantalla de
los tweets fueron el formato más dominante: una mirada más cercana
reveló que este formato predominaba en
CrowdTangle
, mientras que el conjunto de datos de Imgur contenía la menor cantidad
de ocurrencias, como se ilustra en la segunda barra de espectro en la
Figura 3.
Si bien algunos de los conjuntos tenían formatos superpuestos, también había distinciones claras entre ellos. Mirando
las especificidades de la plataforma, la mayor cantidad de macros de
imágenes (es decir, imágenes con texto sobre una imagen y generalmente
vistas como un formato de meme tradicional) se encontró en Imgur,
mientras que
CrowdTangle (Facebook e Instagram) contenía la menor cantidad de macros de imágenes. Por su parte, el conjunto de datos recuperado de
CrowdTangleformatos
destacados como retratos (imágenes de prensa de personas famosas,
portadas de revistas y selfies), imágenes de texto de redes sociales
(texto sin formato que está formateado en un diseño específico con
colores específicos como una imagen para Historias de Instagram o
publicaciones de Facebook, por ejemplo), redes sociales tarjetas de
declaración (información que está formateada con texto e imágenes, para
noticias o citas inspiradoras, por ejemplo) e infografías (que a menudo
contienen gráficos y tablas).
KnowYourMeme
incluía múltiples plantillas de macros de imágenes (imágenes sin texto
que se utilizan en los generadores de memes) y logotipos, mientras que
los datos de Google Image mostraban imágenes de mercancías.
Al
observar la aparición de imágenes, surge que las muestras extraídas de
los conjuntos de datos de Google Images e Imgur contienen una cantidad
significativa de imágenes similares. Estos
conjuntos también presentaban una cantidad relativamente pequeña de
imágenes iguales (duplicados), que en su mayoría eran macros de
imágenes.
Al
observar estos resultados, se puede argumentar que los entornos de
software afectan en gran medida los conjuntos de imágenes recopilados. De hecho, los géneros dominantes de imágenes tienden a variar según la plataforma de la que se extraen. Si
uno considerara como memes solo los formatos presentes en todos los
conjuntos de datos, entonces los memes serían capturas de pantalla de
tweets.

Figura 3. El espectro de formatos de memes y su circulación en la web.
6.2 Exploración de colecciones de memes a través de la visión artificial.
La siguiente imagen-pared se genera con la técnica de reducción de dimensionalidad UMAP y se agrupa mediante
PixPlot. Como
puede ver, cómo las entidades web de Google Vision son
sorprendentemente precisas en la identificación de memes, superando a
Crowdtangle. Todas las
imágenes tienen 'meme' en su descripción de entidad web, y la
clasificación devuelve todos los memes de facto, construidos a través de
plantillas familiares y macros de imágenes. La
precisión de Google Vision al separar los memes de los que no son memes
destaca la especificidad del medio de los memes: son colecciones
digitales nativas, co-constituidas por los entornos de software en los
que se difunden y circulan. De
hecho, la detección de entidades web considera los sitios de
circulación entre sus parámetros, mejorando así su precisión de
clasificación. En otras
palabras, si una imagen circula en un entorno memético y es parte de una
extensa colección de imágenes similares, entonces esta imagen es
probablemente un meme. Por lo tanto,

Figura 4. Uso de Pixplot para interrogar la precisión de las entidades web para la identificación de memes.
#Redes de visión por computadora para dar sentido a la colección de imágenes de memes
Las
redes de visión por computadora se construyen sobre las características
de visión por computadora, como la clasificación de imágenes y la
detección de entidades web. Aquí
utilizamos la detección de entidades web, yendo más allá y detrás del
contenido de la imagen inmediata, y utilizando el entorno web como
fuente de conocimiento contextual y cultural para aumentar y enriquecer
el análisis de la imagen. A
partir de las entidades web detectadas, construimos una red bipartita
con un nodo de plataforma al que se vinculan las entidades web
específicas de la plataforma. En
el centro, encontramos entidades web compartidas, mientras que en la
periferia las entidades web están asociadas con entornos web específicos
y culturas de memes (Imgur, FB, IG, KnowYourMeme ). Entre
pares de plataformas, podemos ver grupos puente que representan
entidades web compartidas, en otras palabras, qué plataformas tienen en
común.
Las
redes de visión por computadora se construyen sobre las características
de visión por computadora, como la clasificación de imágenes y la
detección de entidades web. Aquí
utilizamos la detección de entidades web, yendo más allá y detrás del
contenido de la imagen inmediata, y utilizando el entorno web como
fuente de conocimiento contextual y cultural para aumentar y enriquecer
el análisis de la imagen. A
partir de las entidades web detectadas, construimos una red bipartita
con un nodo de plataforma al que se vinculan las entidades web
específicas de la plataforma. En
el centro, encontramos entidades web compartidas, mientras que en la
periferia las entidades web están asociadas con entornos web específicos
y culturas de memes (Imgur, FB, IG, KnowYourMeme ). Entre
pares de plataformas podemos ver grupos puente que representan
entidades web compartidas, en otras palabras, qué plataformas tienen en
común.

 Figura 5. Los elementos formales y temáticos que constituyen las imágenes de los memes covid. Entidades web compartidas asociadas con la colección de imágenes de memes multiplataforma (arriba).
Figura 5. Los elementos formales y temáticos que constituyen las imágenes de los memes covid. Entidades web compartidas asociadas con la colección de imágenes de memes multiplataforma (arriba).
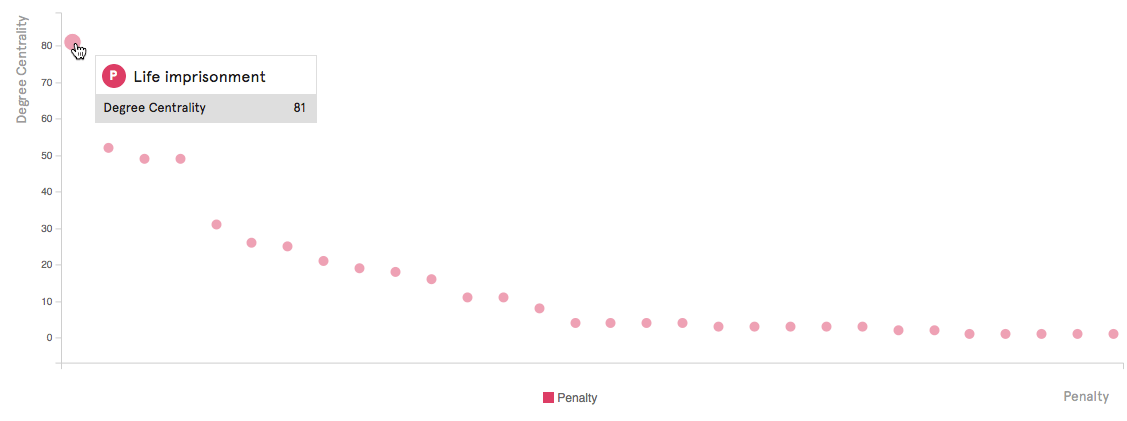
Un análisis del grupo central muestra cómo las redes de visión artificial pueden contribuir a la ontología memética. La
centralidad de la red de las entidades web dominantes, que funcionan
como puentes entre plataformas, muestra a través de la planitud para el
análisis de redes cómo la jerarquía ontológica de los modelos de visión
por computadora captura lo que es un meme. Entidades
como 'texto', 'imagen', 'captura de pantalla', 'título', 'caricatura',
'dibujo', 'cita' son componentes pre-meméticos que aún no son memes. En
otras palabras, los elementos formales de los memes, sus bloques de
construcción y las condiciones necesarias son, desde una perspectiva de
red, entidades web multiplataforma. Estas
entidades web centrales constituyen las primitivas ontológicas y
epistemológicas del medio memético: qué es un meme, cómo podemos
reconocerlo y cómo podemos crearlo. Como
podemos ver, el único clúster temático en el centro está compuesto por
entidades relacionadas con Covid, reflejando el diseño de consulta
original y representándolo como centralidad de red. Un
razonamiento similar se aplica a la ontología de un 'meme covid': debe
decir algo sobre la pandemia, la campaña de vacunación y comprometerse
con la política. Podemos
argumentar que la investigación de memes realizada a través de redes de
visión por computadora a menudo arrojará resultados similares: en el
centro encontraremos primitivos meméticos, formales y temáticos,
mientras que las constelaciones periféricas expresarán culturas de memes
locales. debe decir algo sobre la pandemia, la campaña de vacunación y comprometerse con la política.

Figura 6. Las zonas periféricas: culturas meme y vernáculos de plataforma
En las zonas periféricas de la red vemos una clara división. Por
un lado, los memes covid están más orientados a la corriente principal,
siendo Facebook presentado por la política dominante, mientras que
Instagram es la cultura dominante. Por otro lado, vemos memes de nicho relacionados con la cultura nerd (Imgur) y la política alternativa (Know Your Meme). Ambos casos refuerzan el argumento de los memes como colecciones que responden al entorno de software en el que se insertan.
Las
entidades web asociadas a los memes covid de Facebook exponen la
pandemia y sus noticias relacionadas, también eventos actuales con
especial enfoque en noticias políticas, personalidades políticas,
políticas y políticas del país. Los memes están desconectados de la cultura pop y las referencias a la cultura de Internet. A continuación, ejemplos de entidades web asociadas exclusivamente con los memes covid de Facebook.

Figura 7. Red de entidades web de Facebook
En Instagram vemos una relación directa con los aspectos principales de la cultura pop. Por ejemplo, deportes y celebridades con entidades como
messi, ronaldo, real madrid, equipo de fútbol de inglaterra . Además,
el lenguaje visual obvio de Instagram, por ejemplo, moda, glamour y
exageración, se identificó a través de entidades como
socialité, vestimenta, turquesa, gafas de sol, criptomonedas, bitcoin, ethereum, belleza, estado físico, modelo . La
cultura memética de los memes covid en Instagram no está directamente
relacionada con la pandemia, las noticias o la política.

Figura 8. Red de entidades web de Instagram
Las
entidades web exclusivas del entorno de software de Imgur se asocian
principalmente con referencias culturales pop y se ubican en el cruce de
la cultura pop y la cultura de Internet. Dentro
de ellos, podemos detectar dos conjuntos distintos pero
interrelacionados: el primero contiene referencias a la cultura nerd,
mostrando entidades como Harry Potter, Batman, Voldemort, Hobbit, Studio Ghibli, Star Wars, Lord of the Rings, Dungeons and Dragons, Pixar, y Fullmetal Alchemist . El
segundo conjunto parece estar relacionado con la cultura viral de
internet y los fenómenos culturales en general: entre las entidades
encontramos 'i can has cheezburger', tiger king, dog videos, okay boomer, guitar, depression .

Figura 8. Red de entidades web de Imgur
Mirando
las entidades web asociadas con el archivo web Know Your Meme, surge un
grupo de referencias de nicho y, por lo tanto, no convencionales. Al mismo tiempo, hay una falta sustancial de referencias a la política dominante oa la cultura dominante de las celebridades. En
cambio, es posible identificar un enfoque general en los fenómenos de
Internet y específico en la web vernácula profunda (Tuters, 2019), como
lo sugieren entidades como wojak, corona chan, space karen, wookiepedia, 4 chan, deviantart, cheems . Además
de eso, se puede observar que las referencias políticas son más
representativas de las ideologías políticas extremas (tanto de extrema
derecha como de extrema izquierda), como lo insinúa un grupo de
entidades asociadas a la ideología Alt-right:Pepe the Frog, derecha, anthony fauci, espectro político, brújula política, autoritarismo y controversias sobre vacunas.

Figura 9. Red de entidades web KnowYourMeme
Mirando las entidades web de los cuatro clústeres, se puede argumentar que
KnowYourMeme e Imgur juntos son más específicos y menos convencionales, con respecto a los otros dos entornos web considerados. Finalmente,
la red también permite mirar el “al revés” de cada entorno de software,
que contiene las entidades web comunes a las otras plataformas. En
este sentido, es posible definir la producción memética de un espacio
digital específico a partir de sus “sombras”, es decir, considerando lo
que falta en los memes que produce y difunde. Es el caso del clúster de entidades web compartidas por Instagram, Know Your Meme e Imgur pero no por Facebook, como
know your meme, broma, risa, entretenimiento, youtube, video viral, grogu, imgflip.
Figura 10. La “sombra de Facebook” o “al revés”
7. Discusión
Esta
investigación, realizada durante la Escuela de Invierno de Métodos
Digitales 2022, analiza la tecnicidad de los memes en relación con las
especificidades de la plataforma. Este
estudio sigue la trayectoria de investigación establecida por Rogers
& Giorgi (en revisión) en su artículo '¿Qué es un meme, técnicamente
hablando?', que propone demarcar la tecnicidad de los memes como
colecciones de contenido generado por entornos de software.
Hablando epistemológicamente, cuando se observan los hallazgos, vale la pena discutir algunos puntos. En
primer lugar, al observar qué es un meme técnicamente hablando con una
lente lógica de tablero de marketing de redes sociales, esto constituye
la ontología más amplia de lo que se considera un meme; Aquí no solo está presente el formato macro de imagen clásico, sino también muchos otros formatos diferentes. En
segundo lugar, al observar qué es un meme técnicamente hablando con una
lente lógica de generador y servidor de alojamiento de imágenes, esto
constituye la ontología más estrecha de lo que se considera un meme; un formato macro de imagen clásico. En
tercer lugar, al observar qué es un meme técnicamente hablando con un
archivo de base de datos y una lente lógica de motor de búsqueda, la
ontología se encuentra en algún punto intermedio; las macros de imagen clásicas se combinan con un par de otros formatos. Por último,
Desde
el punto de vista del análisis de visión por computadora, inferimos qué
es un meme a través de la detección de entidades web de Google Vision. La
técnica de creación de redes permitió el análisis multiplataforma de
imágenes utilizando todos los idiomas de Google y su soporte de
tecnología Vision, pero sin ver las imágenes. No
solo pudimos informar qué constituyen técnicamente los memes covid,
sino que también captamos las lenguas vernáculas de los memes en varias
plataformas. Inferimos
temas específicos de la plataforma derivados de entidades web al cerrar
la lectura de la periferia y las zonas medias de la red. Aquí,
el análisis de memes requirió la experiencia de un equipo
multidisciplinario y el reconocimiento de la tecnicidad del medio
memético y sus entornos web.
8. Conclusión
La pregunta de investigación de qué es un meme, técnicamente hablando y cómo las plataformas de software construyen las colecciones de memes, es muy amplia. Nuestro proyecto de investigación solo ha comenzado a rascar la superficie de cómo se puede investigar empíricamente la tecnicidad de los memes. Al observar los resultados, se puede argumentar en general que lo que constituye un meme depende en gran medida del entorno del software, ya que un entorno web contextual específico de la plataforma y las definiciones difieren ampliamente según la plataforma. De hecho, este proyecto proporciona hallazgos empíricos que respaldan la afirmación principal de Rogers y Giorgi (en revisión), es decir, que los memes tienen una tecnicidad que los afecta materialmente como colecciones en estudio.
Aunque limitados, estos hallazgos también nos permiten concluir con una declaración especulativa sobre lo que lo anterior podría significar para la investigación de memes en general. La definición ontológica de lo que es un meme, basada en el entorno de software que analizamos, es más amplia de lo que los investigadores probablemente clasificarían como un meme (la macro de imagen clásica) e incluye más formatos de imagen. Esto implica que cuando los investigadores utilizan estas herramientas para realizar investigaciones de memes, lo que están investigando se está moviendo hacia un modo más amplio de análisis de imágenes virales, pasando de un tipo de investigación más vernáculo de nicho.
9. Referencias
Bastian, M., Heymann, S., & Jacomy, M. (2009). Gephi: An Open Source Software for Exploring and Manipulating Networks. Third International AAAI Conference on Weblogs and Social Media, 361–362.
https://doi.org/10.1136/qshc.2004.010033 Bucher, T. (2012). A technicity of attention: How software 'makes sense'. Culture Machine, 13, 1-23.
Chao, J. (2021). Memespector GUI: Graphical User Interface Client for Computer Vision APIs (Version 0.2) [Software]. Available from
https://github.com/jason-chao/memespector-gui.
Davison, P. (2012). The language of internet memes. The social media reader, 120-134.
Dynel, M. (2016). “I has seen Image Macros!” Advice Animals memes as visual-verbal jokes. International Journal of Communication, 10, 29.
Jacomy M, Venturini T, Heymann S, Bastian M (2014)
ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software.
PLoS ONE 9(6): e98679.
https://doi.org/10.1371/journal.pone.0098679 Laineste, L., & Voolaid, P. (2016). Laughing across borders: Intertextuality of internet memes. The European Journal of Humour Research, 4(4), 26-49.
Maier, Nils; Parodi, Federico & Verna, Stefano (2007).
DownThemAll (Version 4.04) [browser extention] . Available from
https://www.downthemall.org/ Medialab Tools.
Table2Net Available from
https://medialab.github.io/table2net/ Milner, R. M. (2018). The world made meme: Public conversations and participatory media. MIT Press.
Miltner, K. M. (2014). “There’s no place for lulz on LOLCats”: The role of genre, gender, and group identity in the interpretation and enjoyment of an Internet meme. First Monday.
Miltner, K. M. (2018). Internet memes. The SAGE handbook of social media, 55, 412-428.
Niederer, S. (2019). Networked Content Analysis: The case of climate change. (1 ed.)
(Theory on Demand; No. 32). Hogeschool van Amsterdam, Lectoraat Netwerkcultuur.
Niederer, S., & Van Dijck, J. (2010). Wisdom of the crowd or technicity of content? Wikipedia as a sociotechnical system. New media & society, 12(8), 1368-1387.
Nissenbaum, A., & Shifman, L. (2017). Internet memes as contested cultural capital: The case of 4chan’s/b/board. New Media & Society, 19(4), 483-501.
Omena, J. J. (2021). Digital Methods and Technicity-of-the-Mediums. From Regimes of Functioning to Digital Research [Universidade Nova de Lisboa]. Available from
https://run.unl.pt/handle/10362/127961 Omena, J. J., Elena, P., Gobbo, B., & Jason, C. (2021). The Potentials of Google Vision API-based Networks to Study Natively Digital Images. Diseña, (19), 1-1.
Omena, J. J., & Amaral, I. (2019). Sistemas de leitura de redes digitais multiplatform. In J. J. Omena (Ed.) Métodos Digitais: Teoria-Prática-Crítica. Lisboa: ICNOVA. ISBN: 978‐972‐9347‐34‐4
Rogers, R. (2019). Doing digital methods. Sage.
Rogers, R. (2021). Visual media analysis for Instagram and other online platforms. London. SAGE Publications Ltd.
Rogers, R., and Giorgi, G. (under review). ‘What is a meme, technically speaking?’.
Shifman, L. (2014). Memes in digital culture. MIT press.
Tuters, M. (2019). LARPing & liberal tears: Irony, belief and idiocy in the deep vernacular web. Available from
https://mediarep.org/bitstream/handle/doc/13282/Post_Digital_Cultures_37-48_Tuters_LARPing_Liberal_Tears.pdf?sequence=1 Venturini, T., Jacomy, M., & Jensen, P. (2019). What do we see when we look at networks. arXiv preprint arXiv:1905.02202.
Pearce, W., Özkula, S. M., Greene, A. K., Teeling, L., Bansard, J. S., Omena, J. J., & Rabello, E. T. (2020). Visual cross-platform analysis: Digital methods to research social media images. Information, Communication & Society, 23(2), 161-180.
Spitzberg, B. H. (2014). Toward a model of meme diffusion (
M3D). Communication Theory, 24(3), 311-339.
Wiggins, B. E., & Bowers, G. B. (2015). Memes as genre: A structurational analysis of the memescape. New media & society, 17(11), 1886-1906.
Zannettou, S., Caulfield, T., Blackburn, J., De Cristofaro, E., Sirivianos, M., Stringhini, G., & Suarez-Tangil, G. (2018, October). On the origins of memes by means of fringe web communities. In Proceedings of the Internet Measurement Conference 2018 (pp. 188-202).