8 Excellent Twitter Analytics Tools to Extract Insights from Twitter Streams
Yung Hui Lim
Twitter is now the third most popular social network, behind Facebook and MySpace (Compete, 2009). A year ago, it has over a million users and 200,000 active monthly users sending over 3 million updates per day (TechCrunch, 2008). Those figures have almost certainly increased since then. With the torrential streams of Twitter updates (or tweets), there's an emerging demand to sieve signals from noises and harvest useful information.
Enter Twitter Analytics, Twitter Analysis, or simply just Analytwits (in the tradition of Twitter slang). These analytics tools are growing in numbers; even Twitter is developing them.
Besides Twitter Search, the following 8 Analytwits are some of the more useful web applications to analyze Twitter streams. Each of these tools serve specific purpose. They crawl and sift through Twitter streams; also, aggregate, rank and slice-and-dice data to deliver some insights on Twitter activities and trends. There's no single best analytic tool available but use in combination, they can extract interesting insights from Twitter streams.
8 Great Tools for Social (Twit)telligence
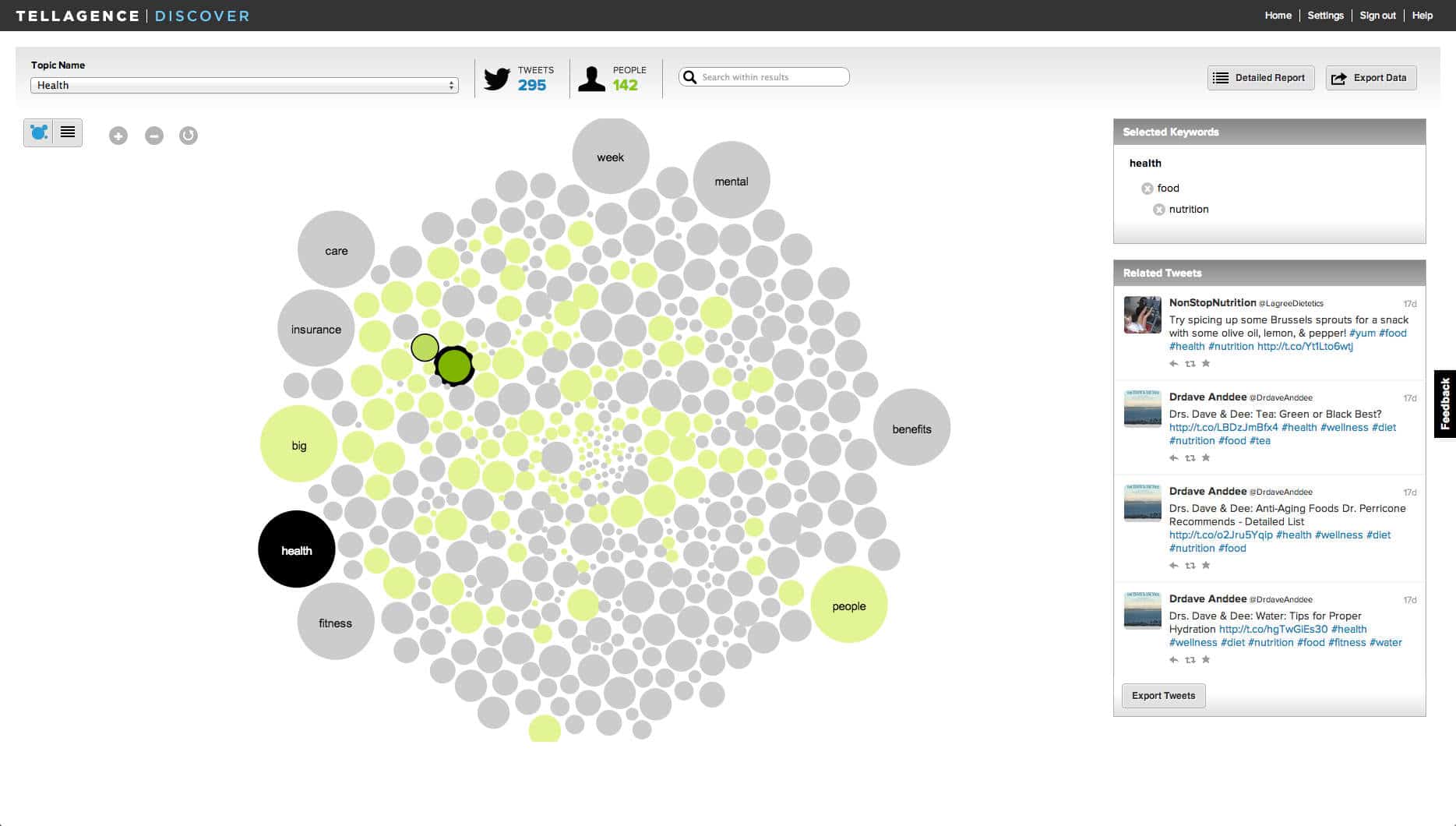
 TWITALYZER provides activities analysis of any Twitter user, based on social media success yardsticks. Its metrics include (a) Influence score, which is basically your popularity score on Twitter (b) signal-to-noise ratio (c) one's propensity to ‘retweet' or pass along others' tweets (d) velocity - the rate one's updates on Twitter and (e) clout - based on how many times one is cited in tweets. Its Time-based Analysis of Twitter Usage produces graphical representation of progression on various measures. Using Twitalyzer is a easy; just enter your Twitter ID and that's it! It doesn't require any password to use its service. Speed of analysis is depending on the size of your Followed and Followers lists.
TWITALYZER provides activities analysis of any Twitter user, based on social media success yardsticks. Its metrics include (a) Influence score, which is basically your popularity score on Twitter (b) signal-to-noise ratio (c) one's propensity to ‘retweet' or pass along others' tweets (d) velocity - the rate one's updates on Twitter and (e) clout - based on how many times one is cited in tweets. Its Time-based Analysis of Twitter Usage produces graphical representation of progression on various measures. Using Twitalyzer is a easy; just enter your Twitter ID and that's it! It doesn't require any password to use its service. Speed of analysis is depending on the size of your Followed and Followers lists. MICROPLAZA offers an interesting way to make sense of your Twitter streams. Called itself “your personal micro-news agency,” it aggregates and organizes links shared by those you follow on Twitter and display them as newstream. Status updates that contain similar web links are aggregated into 'tiles.' Within a tile, you can see updates from those you follow and also those you don't. Another interesting feature is ‘Being Someone', which you can peek into someone's world and see their 'tiles'; designed to facilitate information discovery. You can also organize those you follow into groups or ‘tribes'. You can create, for example, a knitting ‘tribe' to easily what URLs your knitting friends are tweeting. In addition, you can bookmark 'tiles' for future reference. Its yet-to-be-released feature, Mosaic, allows users to group together the bookmarked 'tiles' and turn them into social objects - for sharing and discussion. At the time of this posting, MicroPlaza is still in private beta.
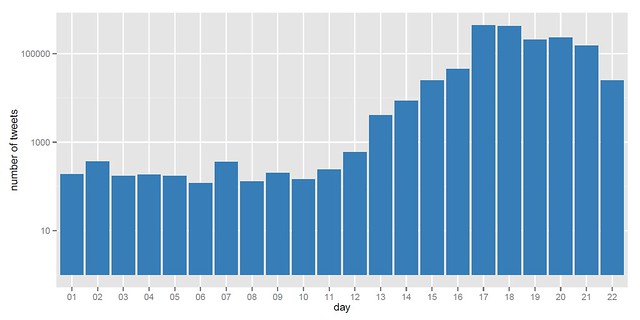
MICROPLAZA offers an interesting way to make sense of your Twitter streams. Called itself “your personal micro-news agency,” it aggregates and organizes links shared by those you follow on Twitter and display them as newstream. Status updates that contain similar web links are aggregated into 'tiles.' Within a tile, you can see updates from those you follow and also those you don't. Another interesting feature is ‘Being Someone', which you can peek into someone's world and see their 'tiles'; designed to facilitate information discovery. You can also organize those you follow into groups or ‘tribes'. You can create, for example, a knitting ‘tribe' to easily what URLs your knitting friends are tweeting. In addition, you can bookmark 'tiles' for future reference. Its yet-to-be-released feature, Mosaic, allows users to group together the bookmarked 'tiles' and turn them into social objects - for sharing and discussion. At the time of this posting, MicroPlaza is still in private beta. TWIST offers trends of keywords or product name, based what Twitter users are tweeting about. You can see frequency of a keyword or product name being mentioned over a period a week or a month and display them on a graph. Select an area on the graph to zoom into trend for specific time range. Click on any point on the graph to see all tweets posted during a specific time. One can also see the latest tweets on the topic. Twist also allows you do a trend comparison of two (or more) keywords. Its graphs are embeddable on any website. A simple but effective tool for trending, similar to what Google Trends is doing for search queries.
TWIST offers trends of keywords or product name, based what Twitter users are tweeting about. You can see frequency of a keyword or product name being mentioned over a period a week or a month and display them on a graph. Select an area on the graph to zoom into trend for specific time range. Click on any point on the graph to see all tweets posted during a specific time. One can also see the latest tweets on the topic. Twist also allows you do a trend comparison of two (or more) keywords. Its graphs are embeddable on any website. A simple but effective tool for trending, similar to what Google Trends is doing for search queries. TWITTURLY tracks popular URLs tracker on Twitter. With Digg-style interface, it displays 100 most popular URLs shared on Twitter over the last 24 hours. On Digg, people vote for a particular web content, whereas on Twitterurly, each time a user share a link, it is counted as 1 vote. This is a good tool to see what people are ‘talking' about in Twitterville and see total tweets that carry the links. Its URL stats provides information on number of tweets in last 24 hrs, last 1 week and last 1 month. It also calculates total estimated reach of the tweets. Another interesting site is Tweetmeme, which can filter popular URLs into blogs, images, videos and audios.
TWITTURLY tracks popular URLs tracker on Twitter. With Digg-style interface, it displays 100 most popular URLs shared on Twitter over the last 24 hours. On Digg, people vote for a particular web content, whereas on Twitterurly, each time a user share a link, it is counted as 1 vote. This is a good tool to see what people are ‘talking' about in Twitterville and see total tweets that carry the links. Its URL stats provides information on number of tweets in last 24 hrs, last 1 week and last 1 month. It also calculates total estimated reach of the tweets. Another interesting site is Tweetmeme, which can filter popular URLs into blogs, images, videos and audios. TWEETSTATS is useful to reveal tweeting behavior of any Twitter users. It consolidates and collates Twitter activity data and present them in colorful graphs. Its Tweet Timeline is probably the most interesting, as it shows month-by-month total tweets since your joined Twitter (TweetStats showed Evan Williams, co-founder of Twitter, started tweeting since March 2006; 80 tweets during that month). Twitterholic can also show when a person joined Twitter but not in graphical format. Other metrics include (a) Aggregate Daily Tweets - total tweets, by day (c) Aggregate Hourly Tweets - total tweets, by hour (d) Tweet Density: hourly Twitter activities over 7 days period (e) Replies to: top 10 persons you've replied and (f) Interfaces Used: top 10 clients used to access Twitter. In addition, its Tweet Cloud allows you to see the popular words you used in your tweets.
TWEETSTATS is useful to reveal tweeting behavior of any Twitter users. It consolidates and collates Twitter activity data and present them in colorful graphs. Its Tweet Timeline is probably the most interesting, as it shows month-by-month total tweets since your joined Twitter (TweetStats showed Evan Williams, co-founder of Twitter, started tweeting since March 2006; 80 tweets during that month). Twitterholic can also show when a person joined Twitter but not in graphical format. Other metrics include (a) Aggregate Daily Tweets - total tweets, by day (c) Aggregate Hourly Tweets - total tweets, by hour (d) Tweet Density: hourly Twitter activities over 7 days period (e) Replies to: top 10 persons you've replied and (f) Interfaces Used: top 10 clients used to access Twitter. In addition, its Tweet Cloud allows you to see the popular words you used in your tweets. TWITTERFRIENDS focuses on conversation and information aspects of Twitter users' behaviors. Two key metrics are Conversational Quotient (CQ) and Links Quotient (LQ). CQ measures how many tweets were replied whereas LQ measures how many tweets contained links. Its TwitGraph displays six metrics - Twitter rank, CQ, LQ, Retweet Quotient, Follow cost, Fans and @replies. Its interactive graph (using Google Visualization API) can displays relationships between two variables. In addition, you can search for conversations between two Twitter users. This app seems to slice-and-dice data in more ways compared to other applications listed here.
TWITTERFRIENDS focuses on conversation and information aspects of Twitter users' behaviors. Two key metrics are Conversational Quotient (CQ) and Links Quotient (LQ). CQ measures how many tweets were replied whereas LQ measures how many tweets contained links. Its TwitGraph displays six metrics - Twitter rank, CQ, LQ, Retweet Quotient, Follow cost, Fans and @replies. Its interactive graph (using Google Visualization API) can displays relationships between two variables. In addition, you can search for conversations between two Twitter users. This app seems to slice-and-dice data in more ways compared to other applications listed here. THUMMIT QUICKRATE offers sentiments analysis, based on conversations on Twitter. This web application identifies latest buzzwords, actors, movies, brands, products, etc. (called ‘topics') and combines them with conversations from Twitter. It does sentiment analysis to determine whether each Twitter update is Thumms up(positive), neutral or Thumms down (negative). Click on any topic to display opinions on the topic found on Twitter. In addition, it allows people to vote on topics via its website or mobile phones. The idea behind this app is good but still has some kinks to work out.
THUMMIT QUICKRATE offers sentiments analysis, based on conversations on Twitter. This web application identifies latest buzzwords, actors, movies, brands, products, etc. (called ‘topics') and combines them with conversations from Twitter. It does sentiment analysis to determine whether each Twitter update is Thumms up(positive), neutral or Thumms down (negative). Click on any topic to display opinions on the topic found on Twitter. In addition, it allows people to vote on topics via its website or mobile phones. The idea behind this app is good but still has some kinks to work out. TWEETEFFECT matches your tweets timeline with your gain/lose followers timeline to determine which tweet makes you lost or gain followers. It analyze the latest 200 tweets and highlights tweets that coincides with you losing or gaining two (or more) followers in less than 5 minutes. This application simplistically assumed that your tweet is the sole factor affecting your gain/lose followers pattern. But, in reality, there are many other factors involved. Nevertheless, TweetEffect is still a fun tool to use; just don't take the results too seriously.
TWEETEFFECT matches your tweets timeline with your gain/lose followers timeline to determine which tweet makes you lost or gain followers. It analyze the latest 200 tweets and highlights tweets that coincides with you losing or gaining two (or more) followers in less than 5 minutes. This application simplistically assumed that your tweet is the sole factor affecting your gain/lose followers pattern. But, in reality, there are many other factors involved. Nevertheless, TweetEffect is still a fun tool to use; just don't take the results too seriously.
Let's Continue the Discourse on Twitter
Which of the abovementioned Twitter analytics you like the most? How can these tools generate revenue? Have you discovered any other interesting Twitter analytics? Share your thoughts on Twitter; find me @limyh